
ML Interview Q Series: Probability of Doubled Card Numbers: A Combinatorial Calculation

Browse all the Probability Interview Questions here.
Suppose you have 100 uniquely numbered cards (1 through 100). You draw two cards at random without putting the first one back. What is the probability that one card’s number is exactly twice the other card’s number?
Short Compact solution
There are a total of 100 choose 2 ways to pick any two distinct cards from the 100. This count is 4950. Exactly 50 distinct pairs (such as (1,2), (2,4), …, (50,100)) have the property that one value is twice the other. Since we do not care about which card is drawn first, there are 2 different sequences for each of these 50 pairs, giving a total of 100 favorable outcomes. Thus, the probability is 100 ÷ 4950, which is about 0.02.
Detailed Explanation
To see why the total number of ways to pick two cards out of 100 is 4950, we use the binomial coefficient. Specifically:
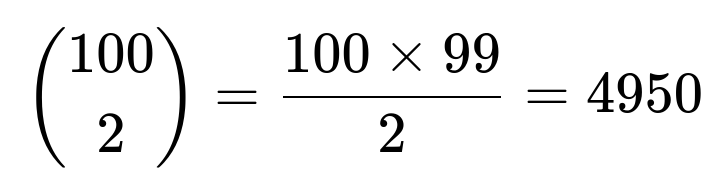
This represents the total possible unordered pairs of distinct cards.
Next, to have one card be exactly twice the other, notice that for any integer (k) from 1 to 50, (2k) will be at most 100, creating a valid double pair ((k, 2k)). That yields 50 such distinct pairs ((1,2), (2,4), \ldots, (50, 100)). However, if we consider sequences (meaning the first card drawn could be the smaller or the larger number), each of those pairs can appear in 2 different ways:
Smaller number drawn first, then larger number.
Larger number drawn first, then smaller number.
Therefore, there are (50 \times 2 = 100) favorable ordered outcomes.
Since drawing two cards without replacement can be viewed as choosing an unordered pair when calculating probability (but effectively it matches the number of ordered outcomes as well, as long as we stay consistent), we find the probability by taking the 100 favorable ways over the total of 4950 possible pairs:
Hence, the probability is about 2%.
In more detail:
The essential insight is identifying which pairs satisfy the “double” property. It is crucial to make sure not to include pairs like ((51, 102)) because 102 is outside our deck range. That is precisely why the highest valid smaller card is 50 (paired with 100).
The order in which the two cards appear does not affect the “event” of having one be double the other. But when we count favorable outcomes carefully, we can either count unordered pairs (50 of them) and compare to the 4950 unordered pairs, or count ordered pairs (100 of them) and compare to the total ordered draws of (100 \times 99). Either method is consistent as long as we do not mix them.
How can we generalize this probability for a deck of size N?
A more generalized approach is to consider a deck of integers from 1 up to (N). One card has to be double the other, so the smaller card (k) can range from 1 up to (\lfloor \frac{N}{2} \rfloor). Each (k) pairs up with (2k). The total number of such valid distinct pairs will be (\lfloor \frac{N}{2} \rfloor). Each distinct pair can be drawn in 2 ways (if we consider the drawing order). The number of ways to select 2 cards out of (N) is (\binom{N}{2}).
So if order does not matter:
Number of favorable pairs: (\lfloor \frac{N}{2} \rfloor).
Total ways to choose any two distinct cards: (\binom{N}{2}).
Probability: (\dfrac{\lfloor \frac{N}{2} \rfloor}{\binom{N}{2}}.)
If you think in terms of ordered draws, you would have (2\lfloor \frac{N}{2} \rfloor) favorable ways out of (N \times (N-1)) possible draws. The numerical value should match as long as you are consistent with whether you are counting ordered or unordered outcomes in both numerator and denominator.
What if we were asked for a different ratio, such as one card is triple the other?
In that case, for each integer (k), we need (3k \leq N). So the smallest card (k) can go from 1 up to (\lfloor \frac{N}{3} \rfloor). The total such pairs would be (\left\lfloor \dfrac{N}{3} \right\rfloor). Again, you would compare it to (\binom{N}{2}). So the probability is (\dfrac{\left\lfloor \frac{N}{3} \right\rfloor}{\binom{N}{2}}). The reasoning is the same: for each (k) in that range, ((k, 3k)) is a unique pair.
How would you implement a quick simulation in Python to verify this probability?
A simple Monte Carlo simulation can be performed. Below is a Python example that randomly draws two distinct cards from a range of integers and estimates how often the “double” condition occurs.
import random
def estimate_probability(num_trials=10_000_00, deck_size=100):
count_double = 0
for _ in range(num_trials):
cards = random.sample(range(1, deck_size + 1), 2) # Draw two distinct cards
# Check if one card is double the other
if (cards[0] == 2 * cards[1]) or (cards[1] == 2 * cards[0]):
count_double += 1
return count_double / num_trials
estimated_prob = estimate_probability()
print(f"Estimated probability: {estimated_prob}")
This approach repeatedly samples two distinct integers from 1 to 100. Each trial checks whether the pair satisfies the double condition and keeps track of how many times that is true. The ratio of successful trials to total trials yields an empirical approximation of the probability, which should come close to 0.02 for a large number of trials.
Are there edge cases or pitfalls to watch out for when coding or reasoning about this?
One common pitfall is to forget the difference between ordered and unordered pairs. When computing probabilities directly from combinatorial arguments, make sure to remain consistent. Either:
Use unordered pairs in both numerator and denominator, or
Use ordered draws (permutations) in both numerator and denominator.
Mixing them produces an incorrect ratio. Another pitfall is failing to handle the boundary properly, such as letting the smaller card exceed (\frac{N}{2}). That will lead to counting pairs that do not exist in the deck (for example, ((51, 102)) if (N = 100)).
Finally, it is important to remember that if you do a direct simulation, you must ensure you draw two distinct cards. Drawing the same card twice is not allowed. Keeping these details straight will ensure correct results.
Below are additional follow-up questions
What changes if each card is drawn with replacement instead of without replacement?
When you draw a card and then replace it before drawing the second card, you need to be mindful that the same card value can appear twice. In that scenario, both draws become independent events, and the sample space becomes larger in terms of ordered draws.
Ordered sample space: You have 100 possible outcomes for the first draw, and 100 possible outcomes for the second draw, leading to (100 \times 100 = 10,000) total ordered possibilities.
Favorable outcomes: We still need pairs ((k, 2k)), but now the same exact card could appear again if 2k happens to equal k, which only occurs if (k = 0). However, our deck values run from 1 to 100, so you cannot have a situation where (k) equals (2k) unless (k) is 0. So effectively, the pairs that matter remain the same 50 double relationships for (k \in {1,2,\ldots,50}). Each of those 50 pairs can appear in two possible orders: ((k,2k)) and ((2k,k)).
But now duplicates are allowed. For example, if you draw the number 10 on the first draw, you can still draw 10 again on the second draw, because you replaced the card. However, that does not help with the “one card is double the other” condition unless 10 is double 10, which it is not. So there are no new “double” pairs added by allowing duplicates of the same card, but the sample space grows to 10,000.
Hence, the favorable set is still (50 \times 2 = 100) ordered pairs that fulfill “one card is double the other,” but the sample space is now 10,000. So the probability becomes (100 / 10000 = 0.01).
Key insight: Because drawing with replacement allows for drawing the same number twice, you must account for the fact that ((x, x)) is a possible draw. However, ((x, x)) never satisfies “one card is exactly double the other” unless (x = 0), which is not in our deck.
A pitfall here is forgetting that with replacement you can get ((x, x)), but that does not create any new valid “double” pairs. Another subtlety is mixing up the total ways to draw with or without replacement, which leads to an incorrect denominator if you are not careful.
How does the result change if the deck is missing some cards?
If the deck is missing cards, the total number of possible draws and the set of valid “double” pairs could change drastically. For instance, if some key cards that participate in doubling relationships are removed, the probability decreases. Conversely, if the missing cards do not influence many potential pairs, then the probability might not change much.
Example scenario: Suppose you know card 50 is missing. This directly removes the double relationship ((50, 100)). Moreover, it might also remove relationships where 25 is involved if 50 is missing. Actually, 50 being missing only removes ((50, 100)) as an explicit double pair, but 25 still pairs with 50, which is absent, so ((25, 50)) is also removed from the set of valid pairs. Hence, you lose two possible favorable scenarios: ((25,50)) and ((50,100)). If either 25 or 100 are also removed, it can get more intricate.
General approach:
Recount how many double relationships remain in the deck. For each number (k) from 1 to 100, check if both (k) and (2k) are present among the remaining cards.
Count those pairs carefully.
Compare it against the new total possible ways to choose 2 distinct cards from the truncated deck.
A subtlety: you might forget that removing a card like 100 also invalidates pairs like ((50, 100)). The best practice is to do a systematic inventory of the deck’s remaining numbers and check all potential “double” matches.
What if the values on the cards are not unique or contain duplicates?
A scenario with duplicates means you might have multiple copies of the same integer. This changes how many ways you can pick a specific number. If a value (v) appears (m) times in the deck, and a value (2v) appears (n) times, you should account for the fact that there are (m \times n) ways to pick ((v,2v)).
Counting total ways:
Let (N) be the total count of cards (including duplicates).
You can still use (\binom{N}{2}) if you are picking unordered pairs from these (N) cards.
Counting favorable ways:
For each unique value (v), check if the value (2v) is present.
Multiply the counts of those duplicates: if (v) appears (m) times and (2v) appears (n) times, then there are (m \times n) ways to pick one from the (v) group and one from the (2v) group.
Add all these products for every (v) where (2v) also exists in the deck.
One pitfall: if (v = 2v), that implies (v = 0). Typically, that situation does not arise for positive integers. But if we had a deck that included zero, it might complicate the question of “double.”
What if we want the event that “one card is at least twice the other”?
This changes the condition from “exactly double” to “at least double,” which broadens the set of valid pairs.
Interpreting the new condition: For each pair ((a, b)) such that (a \ge 2b) or (b \ge 2a).
Approach to count:
For a fixed card (k), how many cards in the deck are at most (\frac{k}{2})? Because all such cards satisfy that (k \ge 2 \times\text{(smaller card)}).
Sum over (k) from 1 to 100. But be careful that you don’t double-count.
Alternatively: Sort the deck from smallest to largest. If you fix the smaller card as (s), then the larger card needs to be at least (2s). So for each (s), count how many integers are (\ge 2s).
For (s=1), all cards from 2 up to 100 qualify if the criterion is ( \ge 2). That is 99 cards.
For (s=2), all cards from 4 up to 100 qualify. That is 97 cards.
Keep going up to 50, after which 2*50 = 100, so only 100 qualifies.
Above 50, you get fewer or no valid pairs.
A pitfall is that “at least twice” is not symmetrical. That is, if (a) is at least twice (b), then (b) is at most half of (a). Counting them in one pass is simpler than trying to sum over all pairs in two ways. Another subtlety is that “at least twice” can lead to the same pair being counted from both perspectives if you are not careful (for example, (2,4) meets the condition from either perspective, but you only want to count it once).
How would the probability be affected if each card is drawn with a different probability weight?
If cards are not equally likely (for instance, some cards are more probable than others), the uniform sample space assumption breaks down. Instead of a straightforward combinatorial approach, you would have to sum over all pairs ((a,b)) with the probability (P(a)\times P(b)) if the draws were independent (with replacement), or handle a hypergeometric-type approach if it is without replacement but each card has a different chance of being present or drawn.
Key steps:
Identify (p_i = P(\text{drawing card with value } i)).
For a scenario with replacement, the chance of drawing ((i, j)) in that order is (p_i \times p_j).
Sum over all ((i, j)) such that (j = 2i) or (i = 2j).
Without replacement: The math is more involved since the probabilities become conditional. If you draw card (i) first, the probability of then drawing card (j) depends on how many copies of (j) remain. This might require a more advanced approach or direct enumeration if the deck is small enough.
Pitfall: Confusing the uniform selection logic with weighted sampling can yield incorrect results if you simply do (\binom{N}{2}) in the denominator. That formula no longer reflects the correct distribution of draws.
Could we extend this to drawing three or more cards, and then find the chance that at least one pair has the double relationship?
In a scenario where we draw (r) cards, we want the probability that among those (r) cards, at least one pair has a “double” relationship.
Direct count approach:
Count the total ways to draw (r) distinct cards: (\binom{100}{r}) for an unordered draw without replacement.
Count how many of these combinations contain at least one pair ((k, 2k)). This often involves using the principle of inclusion-exclusion because you might have multiple double pairs in the same draw.
For instance, you might have ({1,2,4}) which includes both (1,2) and (2,4).
The probability is the ratio of “combinations that have at least one valid double pair” to “all possible (\binom{100}{r}) combinations.”
Inclusion-exclusion can be quite involved:
Sum up the number of ways to include each individual double pair.
Subtract the ways that include two double pairs (because they got counted twice).
Add back in those sets that include three pairs, and so on.
Monte Carlo simulation is often a simpler method in code if (r) is not too large, especially for an interview setting, to get an approximate solution.
Pitfall: Double counting can be very tricky in combinatorial settings with multiple possible pairs. Also, watch out for card overlap (for instance, (1,2) and (2,4) share the card 2).
If we look for pairs (x, y) such that x + y equals a specific number, does that compare in complexity?
This question highlights how the complexity depends heavily on the type of relationship you define. Checking for “x + y = S” for some sum (S) is a different condition than “y = 2x.” Combinatorial counting methods might be easier or harder depending on the constraint:
For (x + y = S), one approach is to fix (x) and see what (y) must be. Then check if (y) is in the deck. This can be simpler or more complicated depending on the distribution of numbers.
The pitfall is to realize that constraints like “sum equals a fixed number” often have more pairs than the “double” relationship, so you must carefully count all integers (x) such that (1 \le x \le S-1), and then check if (S-x) is also valid.
In general, any specific functional relationship might require a unique approach to counting or enumerating valid pairs.
How do we efficiently implement a check for doubling pairs in a large set without enumerating all pairs?
If you have a massive set of integers and want to quickly find all pairs where one is double the other, you might try to avoid checking every pair:
Hash-based approach:
Put all numbers in a hash set.
Iterate through each number (x), check if (2x) is in the set. If yes, you have a doubling pair.
Sorting-based approach:
Sort all numbers.
For each (x), perform a binary search for (2x).
Pitfall: If the set has duplicates, you must keep track of the count of each integer in a hash map (or dictionary). Then for an integer (x) that appears (m) times and its double (2x) appears (n) times, you have (m \times n) pairs.
This is more about computational complexity. If you had to do pairwise checks in a dataset of size (N=10^6), that would be (O(N^2)), which is often infeasible. A hashing or sorting approach runs in (O(N)) or (O(N \log N)), respectively, which is typically much more practical.
Does the result change if the definition of “double” is replaced by rounding rules, like “approximately double” or “double within a 5% margin”?
In real-world scenarios, you might define “double” in a less strict way, allowing a small percentage tolerance. For instance, you might say (y) is considered a valid double of (x) if (y) is between (1.95x) and (2.05x). This complicates things because:
You can no longer rely on a purely integer-based check that “(y = 2x).”
Instead, you need to check for each integer (x), which integers fall between (1.95x) and (2.05x).
Some integer rounding might or might not include numbers that are slightly off from 2x. For small (x), 5% might not add or remove any integer values. For large (x), it could add multiple integer possibilities.
The probability depends on how many numbers in the range ([1.95x, 2.05x]) remain in the deck.
A subtlety is that as (x) grows larger, the “5% margin” range can contain multiple integers near 2x. Another potential pitfall is deciding whether to handle boundary issues (e.g., if 2.05x exceeds 100, or 1.95x is below 1). You might also need to consider floating-point precision errors in an actual software implementation.
If the card values are not integers but arbitrary floating-point numbers, can the combinatorial approach still be used?
When the deck is made of real-valued or floating-point numbers, the concept of “y = 2x” must be handled differently. In principle, combinatorial formulas like (\binom{N}{2}) still apply for the total ways to pick 2 distinct “cards,” but identifying which pairs satisfy “double” might require:
Exact floating-point comparison if you literally want “y = 2.0 * x,” but that can be sensitive to floating-point precision issues (e.g., 1.999999999999 might or might not register as 2.0 times 1.0 in a computer).
Approximate matching if you allow a tolerance for floating-point representation.
This can become a source of errors or confusion if not specified clearly. Some real-world data might never contain perfect doubles, so your probability could be zero unless you set a threshold.
A pitfall is ignoring floating-point precision issues. For instance, if your floating-point representation of 2 times 0.1 is 0.20000000298023224, you might never find an exact match for 0.2. It is essential to define the matching criteria carefully.
How do we handle “one card is double the other” if negative numbers are included?
If the deck includes negative values (say from -50 to +50 excluding zero), the idea of doubling gets more intricate:
If zero is included, nothing can be exactly double zero unless it is 0. But 0 cannot be double any positive or negative integer. This typically means zero is a special case that does not produce any valid pairs, except (0,0) if duplicates were allowed.
If negative and positive values are included, then for a negative (x), its double is just (2x), which is also negative unless (x=0). This logic still holds, but you must keep track of whether doubling a negative number remains in the deck’s valid range.
The total pair counting approach is still the same: find all (x) for which (2x) is in the deck.
One subtlety arises if you do not realize negative times two is more negative, so certain pairs might not exist (for instance, if the deck stops at -30, but you have -20, then -40 is outside the deck and you cannot count that pair).
Hence the method is not that different, but you have to systematically include negative values in your checking. A common pitfall is forgetting about sign changes or zero-based special cases.
Could we interpret “one card is double the other” in terms of multiplicative group theory or a graph-based approach?
Yes, sometimes these problems can be viewed in a graph or number-theoretic context:
Graph perspective: Create a graph where each node is an integer from 1 to 100. Draw an edge between (x) and (y) if (y = 2x) or (x = 2y). Then the question of “what is the probability of drawing an edge at random from the graph?” is analogous to “what fraction of edges are double-edges?” In a uniform setting, it’s the same approach but re-framed.
Potential pitfall is conflating node-based sampling with edge-based sampling. You do not want to pick edges randomly from a graph. Instead, you are picking two distinct nodes from a set of 100 and seeing if they form an edge. This is sometimes called the “random graph sampling” approach and can help visualize the problem.
Group theory perspective might be more relevant if the numbers had cyclical properties (e.g., modular arithmetic) or some group structure that simplifies counting. But for an integer set 1 to 100, it is mostly straightforward combinatorial counting.
In an interview, referencing a graph model can demonstrate your ability to recast problems in different frameworks, but be ready to highlight that the final combinatorial counting remains the same.