
ML Interview Q Series: Proving Joint Normality for Concatenated Independent Gaussian Vectors Using Linear Combinations

Browse all the Probability Interview Questions here.
Let X=(X1,...,Xn) and Y=(Y1,...,Ym) be independent random vectors each having a multivariate normal distribution. Prove that (X,Y) has also a multivariate normal distribution.
Short Compact solution
By definition of a multivariate normal distribution, for any constants a1,...,an, the linear combination a1X1 + ... + anXn is normally distributed, and likewise, for any constants b1,...,bm, the linear combination b1Y1 + ... + bmYm is normally distributed. Because X and Y are independent vectors, these two linear combinations are also independent. The sum of two independent normal random variables is again normal. Therefore, for any constants a1,...,an and b1,...,bm, the linear combination a1X1 + ... + anXn + b1Y1 + ... + bmYm is normally distributed. Consequently, the joint vector (X,Y) must be multivariate normal.
Comprehensive Explanation
Intuitive Overview
A fundamental way to characterize a multivariate normal distribution (also called a Gaussian distribution in the multivariate setting) is this condition: A vector Z is multivariate normal if and only if for every possible linear combination of its components, the resulting one-dimensional random variable is normally distributed. Thus, to show that (X,Y) is multivariate normal, we must show that any scalar linear combination of the components of (X,Y) follows a univariate normal distribution.
Here, X has components X1,...,Xn and Y has components Y1,...,Ym. We know X on its own is multivariate normal and Y on its own is multivariate normal, with the additional assumption that X and Y are independent vectors. We leverage the facts:
Any linear combination of X’s components is normal (by X being multivariate normal).
Any linear combination of Y’s components is normal (by Y being multivariate normal).
When you take one normally distributed random variable plus another independent normally distributed random variable, the resulting sum remains a normally distributed random variable.
Key Mathematical Step
Consider any arbitrary linear combination of all the components in (X,Y). In plain text form:
a1X1 + ... + anXn + b1Y1 + ... + bmYm
where the a's and b's are real constants. We denote this entire sum as Z. Formally, we can write:
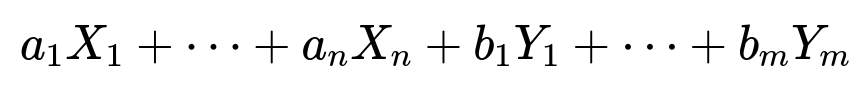
a_i (for i=1,...,n) are constants multiplying the components of X.
b_j (for j=1,...,m) are constants multiplying the components of Y.
Since X is multivariate normal, any sub-sum a1X1 + ... + anXn is univariate normal. Similarly, since Y is multivariate normal, any sub-sum b1Y1 + ... + bmYm is univariate normal. Moreover, by the assumption of independence, these two sub-sums are independent random variables. The sum of two independent normal random variables is itself normal. Hence Z is univariate normal for any choice of the constants a1,...,an, b1,...,bm.
This completes the proof that (X,Y) is indeed a multivariate normal vector because it satisfies the linear combination characterization of multivariate normal distributions.
Practical Perspective and Relation to Covariance Matrices
If X ~ Normal(μ_X, Σ_X) and Y ~ Normal(μ_Y, Σ_Y) independently, then the combined vector (X,Y) can be viewed as:
(X,Y) ~ Normal( (μ_X, μ_Y), Block-Diagonal Covariance )
Specifically, its mean vector is just the concatenation (μ_X, μ_Y), and its covariance matrix has Σ_X and Σ_Y on the diagonal blocks and zeros elsewhere (because of independence). This block structure is exactly the covariance of a larger multivariate normal distribution.
In real applications, it is often beneficial to exploit this property to simplify computations involving partitioned normal distributions. For instance, if you have a joint normal vector but you know certain blocks are independent, you can break down and reason about each piece separately.
Follow-up Question 1: Why does the sum of two independent normal random variables remain normal?
Any univariate normal random variable is completely characterized by a mean and variance. Suppose we have two independent normal random variables U and V. If U ~ Normal(μ_U, σ_U^2) and V ~ Normal(μ_V, σ_V^2), the sum U + V can be shown to have mean μ_U + μ_V and variance σ_U^2 + σ_V^2. The sum U + V is thus Normal(μ_U + μ_V, σ_U^2 + σ_V^2). This result is a well-known property of the normal distribution.
From a more formal standpoint, one can prove it via convolution of two normal probability density functions or by using the moment-generating function (MGF) argument. In MGF form, the product of two independent MGFs is again an MGF of a normal distribution with mean equal to the sum of the means and variance equal to the sum of the variances.
Follow-up Question 2: Could the vector (X,Y) be multivariate normal if X and Y were not independent?
If X and Y are not independent, (X,Y) might still be multivariate normal, but additional steps are required to verify it. The linear combination criterion for multivariate normality does not require strict independence among components; it only requires that any linear combination yields a univariate normal variable. Dependence can exist among components of a multivariate normal distribution in the form of non-zero covariances.
However, in the specific statement of this question, we used independence primarily to argue that the linear combinations a1X1 + ... + anXn and b1Y1 + ... + bmYm are also independent. If X and Y are not independent, we cannot simply say “the sum of two normal random variables is normal because they are independent.” Instead, we would have to use the definition of the joint multivariate distribution or properties of conditional distributions. In general, any combination of normally distributed components with a joint normal distribution is still normal, even with dependence, but the proof would rely on a different set of arguments.
Follow-up Question 3: Why does a linear combination of X's components remain univariate normal if X is multivariate normal?
By definition, a random vector X is said to be multivariate normal if for any constants c1,...,cn, the random variable c1X1 + ... + cnXn is univariate normal. This property can also be understood in terms of the moment-generating function (or characteristic function) approach, where the log of the MGF is a quadratic form in the exponent for multivariate normals, ensuring any linear projection results in a Gaussian distribution.
In practice, to verify X is multivariate normal, one often examines its mean vector μ and covariance matrix Σ and checks if the density function matches the well-known multivariate Gaussian density:
p_X(x) = (1 / ( (2π)^(n/2) |Σ|^(1/2) )) exp( -1/2 (x-μ)^T Σ^(-1) (x-μ) )
But from a more theoretical perspective, once you assume X is multivariate normal, the linear combination property is guaranteed.
Follow-up Question 4: How can we confirm independence of the two linear combinations a1X1 + ... + anXn and b1Y1 + ... + bmYm?
When X and Y are independent vectors, it means that for any measurable functions f and g, the random variables f(X) and g(Y) are independent. By choosing f(X) = a1X1 + ... + anXn and g(Y) = b1Y1 + ... + bmYm, we get two functions applied to X and Y, respectively. Because X and Y are independent random vectors, f(X) and g(Y) must be independent random variables. This is a well-known extension of the usual scalar definition of independence to vector-valued random variables.
Follow-up Question 5: How is this property used in practical machine learning or data science scenarios?
Dimensionality Reduction / PCA: Multivariate normal distributions often arise in PCA (Principal Component Analysis). If a data set is approximately jointly Gaussian, then PCA can be very powerful. The block structure or partitioning properties (X,Y) → independence or partial correlations help reveal latent components or reduce dimensionality effectively.
Bayesian Inference: Gaussian conjugacy properties are frequently exploited. For instance, if you have prior and likelihood that are Gaussian, the posterior is also Gaussian. Partitioning variables into X and Y that may or may not be independent can simplify deriving closed-form posterior distributions in hierarchical models.
Sampling: Generating large synthetic data sets or running MCMC (Markov Chain Monte Carlo) often requires drawing samples from (X,Y). If you know that (X,Y) is jointly Gaussian, sampling is straightforward by simply sampling X and Y from their respective Gaussians and combining them (especially if they are independent). If they are not fully independent, one uses the full covariance matrix.
Linear Regression: In linear regression, we often assume errors are Gaussian. If we treat the design matrix as part of X and the response as Y, we rely on normality assumptions to derive distributions over parameters and predictions.
In all these areas, ensuring that a joint distribution is indeed Gaussian greatly simplifies analysis, derivations, and computations. Having independence between subsets of variables (like X and Y) further simplifies many complex integrals or normalizing constants in probability models.
Below are additional follow-up questions
If X has a degenerate covariance (e.g., zero variance in some directions), is it still multivariate normal, and does the proof for (X, Y) being normal still hold?
When a random vector X has some components that are perfectly correlated or constant (i.e., zero variance), it can still be considered multivariate normal. A degenerate Gaussian distribution in n dimensions is one where the covariance matrix might be singular, meaning some linear combinations of the components always vanish. Formally, a degenerate Gaussian distribution still qualifies as a special case of a multivariate normal distribution.
In the proof that (X, Y) is multivariate normal, degeneracy does not break the logic because:
Any linear combination of X’s components remains normally distributed (it might be a constant random variable if it falls along the degenerate direction).
Similarly for Y.
If X and Y are independent, any linear combination from each is independent of the other. Summing two normally distributed variables (even if one is degenerate) is still normal or degenerate normal.
The edge case to watch out for is that, in degenerate cases, the covariance matrix for (X, Y) becomes block-diagonal with singular blocks. However, this does not violate the definition of multivariate normality. It simply means that the full joint distribution may live on a lower-dimensional subspace.
What if (X, Y) jointly follows a mixture of Gaussian distributions? Does each mixture component preserve the property that (X, Y) is Gaussian?
A mixture of Gaussians involves a latent variable, say Z, that selects which Gaussian component the sample (X, Y) comes from. Even if each conditional distribution given Z is a valid multivariate normal, the marginal distribution (X, Y) obtained by integrating over Z is generally no longer strictly a single multivariate normal—it is a sum of Gaussians weighted by the mixing probabilities.
Hence, if you only know that X and Y come from some mixture of multivariate normals but not necessarily the same single component, you cannot conclude that the overall joint distribution is a single multivariate normal. The mixture distribution could have multimodal structure. Therefore, the statement “independent X and Y each having a multivariate normal distribution implies (X, Y) is multivariate normal” holds strictly for a single Gaussian distribution. Under a mixture model, X and Y might each marginally look Gaussian but their joint distribution might have additional complexities.
A subtle real-world pitfall is assuming that marginal normality of X and Y independently under a mixture model implies joint normality. This is not necessarily correct; the mixture can introduce more complex correlations that are not captured by a single covariance matrix.
Does the same logic extend if we consider more than two independent Gaussian vectors, say X, Y, Z?
Yes, the property generalizes to any finite number of independent multivariate normal vectors. If you have k vectors: X, Y, ..., Z, each of which is multivariate normal and all are mutually independent, then concatenating them into (X, Y, ..., Z) yields another multivariate normal vector. The reasoning is exactly the same:
Each vector is individually normal.
Linear combinations of each are normal.
Independence implies sums of linear combinations from distinct vectors remain normal.
An edge case to consider is computational. When dealing with many high-dimensional Gaussian vectors in practice, forming the full covariance matrix might lead to numerical instability (large matrix sizes, potential ill-conditioning). However, the theoretical property still holds independently of numerical pitfalls.
In practical applications, how can we test or verify that (X, Y) is multivariate normal?
From an applied standpoint, especially with real data:
Visual Diagnostics:
Plot pairwise scatter plots of all components to see if they exhibit elliptical contours.
Look at marginal and bivariate distributions or Q-Q plots.
Statistical Tests:
Mardia’s Test: A popular test for multivariate normality based on multivariate skewness and kurtosis.
Henze–Zirkler Test: Another procedure for multivariate normality checking.
Shapiro-Wilk or Kolmogorov-Smirnov tests can be used dimension-wise, but this does not guarantee multivariate normality across all dimensions simultaneously.
Pitfalls:
These tests are often sensitive to sample size. With small sample sizes, tests may fail to reject normality even when the distribution significantly deviates. Conversely, with huge sample sizes, small deviations from normality might be flagged as significant even if they are inconsequential in practical modeling.
High-dimensional Challenges:
Traditional tests for multivariate normality can have low power or become computationally difficult as dimensions increase.
Practitioners often rely on approximate strategies like dimensionality reduction or further domain-specific assumptions.
How does the notion of conditional independence or conditional distributions fit into the idea that (X, Y) is multivariate normal?
Within a multivariate normal distribution, certain conditional distributions also remain normal. Specifically, if (X, Y) is a joint Gaussian vector, then the conditional distribution X | Y=y is itself Gaussian. This property extends to any partition of a multivariate normal vector. If you already know (X, Y) is jointly Gaussian, then you automatically know all these conditional distributions are Gaussian.
However, if you only know that each of X and Y individually has a Gaussian distribution, you cannot infer how X is distributed once Y is known unless you establish the joint distribution is Gaussian or you specify additional constraints (like a known covariance structure). Conditional independence in a Gaussian context typically implies particular structures in the covariance matrix (e.g., zeros in the inverse covariance matrix). One pitfall is to assume that uncorrelatedness alone implies independence in the multivariate setting; this is only guaranteed for Gaussian distributions, not for arbitrary distributions.
What are the typical computational or numerical issues encountered when manipulating the covariance matrix of (X, Y)?
When X is dimension n and Y is dimension m, the joint covariance matrix for (X, Y) becomes an (n+m) x (n+m) matrix. Common issues include:
Singularity or Near-Singularity: If any subset of variables is nearly perfectly correlated (or truly degenerate), the covariance matrix can be ill-conditioned and difficult to invert. This is frequently encountered in high-dimensional data with limited samples.
Memory Constraints: Storing and manipulating very large covariance matrices can become infeasible as n + m grows.
Stability of Factorizations: Many algorithms rely on the Cholesky decomposition (or other matrix factorizations) of the covariance matrix. Numerical instabilities may arise if the matrix is ill-conditioned, leading to inaccurate computations of densities or repeated sampling from the distribution.
A subtle pitfall is ignoring small correlations that become magnified when inverting a poorly conditioned covariance matrix. Even minor numerical round-off can lead to large errors in computing log-likelihoods or generating samples if the matrix is near-singular.
How does one handle correlation across time when (X, Y) are time series data considered at different time points?
In time series or temporal modeling, each “vector” can represent observations at certain time steps. For instance, X might represent a time series segment in one sensor or domain, and Y might represent measurements in another domain or from another sensor. Even if each time series segment is individually Gaussian, there could be cross-correlation over time between X and Y.
If X and Y are truly independent time series processes (no cross-correlation), then (X, Y) remains a valid joint Gaussian process in time.
Often in real-world signals, X and Y have some correlation at lags. In that case, they are not strictly independent, but they could still be jointly Gaussian with a certain covariance function specifying cross-lag correlations.
A potential pitfall is to treat multi-sensor data as if they were independent just because each sensor’s readings are individually well-modeled by Gaussian processes. In reality, cross-lag correlations might be significant, which influences predictions, inference, and uncertainty quantification. Proper modeling of the joint distribution in time often requires specifying a joint covariance function that accounts for how X and Y co-vary over different time points.
Does linearity of transformations apply to other common distributions beyond the normal?
In general, many distributions do not exhibit the property that an arbitrary linear combination of their components remains in the same family. For instance, the sum of two independent Poisson random variables is still Poisson only if they share the same rate parameter, but more complicated transformations (and partial independence assumptions) often break that structure. For Gamma distributions, the sum of two independent Gamma(α, β) random variables is Gamma(α1+α2, β) only if they share the same rate parameter β, and so forth.
The normal distribution is uniquely stable under linear transformations and convolution. This is one of the core reasons the normal distribution is so widely used in theory and practice. A subtle real-world pitfall occurs when one tries to assume normal-like properties with distributions that do not hold this stability under addition or convolution. The modeling consequences can be severe if the distribution is incorrectly treated as “Gaussian-like” despite clear violation of linear transformation properties.