
ML Interview Q Series: Recommending Similar Airbnb Listings Using Embedding-Based Similarity

📚 Browse the full ML Interview series here.
34. Say you are tasked with producing a model that can recommend similar listings to an Airbnb user when they are looking at any given listing. What kind of model would you use, what data is needed, and how would you evaluate it?
One effective way to address the task of recommending similar listings on Airbnb is to build a system that computes a similarity score between any pair of listings. When a user views one listing, the system ranks all other listings by similarity and returns the top recommendations.
Below is a detailed breakdown of how you might think about this problem in a production environment. We will explore multiple angles and possible approaches:
Choosing the Model Type
There are several modeling paradigms commonly used in recommendation systems. Each has unique strengths and weaknesses, and sometimes a hybrid solution is most effective.
Content-Based Filtering Approach
This approach relies on listing-specific attributes such as:
Geographic location (city, neighborhood, latitude/longitude)
Property features (number of bedrooms, bathrooms, amenities)
Price range
Textual descriptions (listing title and description)
Host information (e.g., host rating, host verification status)
Photos or images (which could be embedded or processed by deep learning)
The idea is to build a listing embedding or profile vector that captures its attributes. Then, when a user views a listing, you compute the similarity of this listing’s embedding to all other listings’ embeddings. The top-kk most similar listings (e.g., by cosine similarity) get recommended.
Collaborative Filtering Approach
In collaborative filtering, you rely heavily on user interactions with listings (bookings, clicks, reviews, wish-list saves, and so on). The intuition is that listings that are “co-visited” or “co-booked” by similar users are likely to be related.
You can build collaborative filtering models in various ways:
Matrix Factorization (e.g., using user-listing rating or implicit feedback matrix)
Deep Learning–based Embedding Approaches (e.g., using factorization machines or neural collaborative filtering)
If you have enough user-history data, collaborative filtering can capture subtle patterns that purely content-based systems might not see. For instance, if many travelers who book one listing also book or view another listing, these two listings might be very strongly “co-clustered,” even if they are not geographically close or do not share many attributes.
Hybrid Recommendation System
Often, an effective real-world system combines both content features and user behavioral signals. Such a hybrid approach might look like:
A deep neural network that takes listing attributes, user embeddings, and possibly listing interactions, and learns a joint embedding space or a relevance score.
An ensemble approach that blends content-based similarity with collaborative filtering signals to produce final recommendations.
Data Requirements
For a similarity-based recommendation, you need to collect and process data that capture both listing descriptors and user interactions:
Data for Content-Based Filtering
Listing metadata: location, amenities, property type, guest capacity.
Listing textual descriptions: titles, host-provided descriptions.
Listing images: could be used to generate image embeddings or visually similar listings.
Price and availability calendar data.
Data for Collaborative Filtering
User clickstream data: which listings each user clicked on, in what order, and how long they spent on each page.
Booking data: which listings were ultimately booked, and how many times they’ve been booked historically.
Implicit feedback signals: wish lists, favorites, star ratings, reviews, or the fact a user spent extra time viewing certain listings.
Constructing Listing Embeddings
A popular method is to embed each listing in a high-dimensional vector space. Then you measure the similarity between two listings’ embeddings. Similar embeddings imply similar listings.
Some standard approaches:
Manual Feature Vector: For each listing, create a vector encoding normalized price, number of bedrooms, number of bathrooms, location coordinates, amenity indicators, host reputation, etc. You can combine these features in a straightforward manner (e.g., concatenation) to get a listing’s feature vector.
Neural Embedding Approach:
For textual data, you can use NLP-based models (e.g., BERT, or a specialized embedding model) to turn listing descriptions into an embedding.
For images, use a CNN (e.g., a pre-trained ResNet) to get an image embedding that captures visual similarity.
Concatenate or fuse these embeddings along with structured features (like price and location).
Collaborative Filtering Embeddings: Train a matrix factorization or neural CF approach that jointly learns listing embeddings and user embeddings. This typically involves:

Combining all three types of embeddings (structured features, text-based embeddings, and collaborative embeddings) can result in a highly robust representation.
Generating Recommendations
When a user is viewing a particular listing, you retrieve its embedding (or multiple embeddings from different models, or an ensemble). Then you compute similarity scores to all other listings. The top similar listings are returned.
An example similarity function might be cosine similarity:
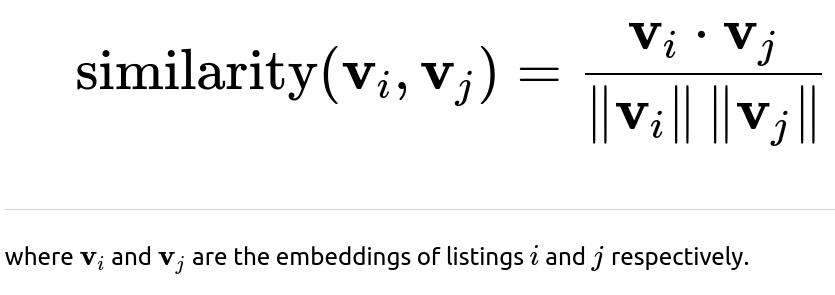
Evaluation Strategy
Evaluating a “similar listings” recommendation system can be tricky, because “similar” can be subjective and context-specific. Still, there are established methods:
Offline Evaluation
Precision / Recall / MAP@k: If you have ground-truth user interactions that indicate which listings a user eventually books, saves, or clicks after viewing a given listing, you can treat that as implicit labeled data to see if your “top-k similar” set aligns with user preferences.
Human Judgment: For a sample of listing pairs, ask human raters (or domain experts) to judge how relevant the recommended listing is to the original listing. This is especially important for discovering whether your similarity measure captures user intuition of “similar.”
Diversity Metrics: Sometimes you want a diverse set of recommendations. You can measure the average pairwise distance among your top-k recommendations to ensure you do not produce recommendations that are too redundant.
Online Evaluation
A/B Testing: Show a subset of users the new recommendation system while others see the old system. Compare metrics such as click-through rates on recommended listings, booking conversions, user satisfaction, etc.
User Engagement: Evaluate dwell times, wishlist additions, or other engagement signals.
Practical Implementation Example in Python
Below is a simplified illustration of how you might implement content-based similarity. This example uses a fictional dataset of listings in a Pandas DataFrame.
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Example data: Suppose we have listing_id, description, location, price, etc.
data = {
'listing_id': [101, 102, 103],
'description': [
"Beautiful apartment near the beach with 2 bedrooms and a balcony",
"Modern condo in city center close to nightlife",
"Cozy cottage in the countryside with fireplace"
],
'location': ["BeachCity", "Downtown", "Countryside"],
'price': [150, 200, 90]
}
df = pd.DataFrame(data)
# TF-IDF for textual description
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(df['description'])
# Combine with other features, e.g., location (one-hot encoding) and price
location_dummies = pd.get_dummies(df['location'], prefix='loc')
price_normalized = (df['price'] - df['price'].mean()) / df['price'].std()
# Convert these to numpy arrays
location_array = location_dummies.to_numpy()
price_array = price_normalized.to_numpy().reshape(-1, 1)
# Final feature matrix
content_features = np.hstack((tfidf_matrix.toarray(), location_array, price_array))
# Compute pairwise similarities
similarities = cosine_similarity(content_features)
# For each listing, get top-k similar listings
def get_similar_listings(listing_index, top_k=2):
sim_scores = similarities[listing_index]
# Sort by similarity descending
sorted_indices = np.argsort(sim_scores)[::-1]
# Exclude the listing itself
sorted_indices = sorted_indices[sorted_indices != listing_index]
return [(df.loc[i, 'listing_id'], sim_scores[i]) for i in sorted_indices[:top_k]]
# Example usage: get similar listings to the first listing
print("Listings similar to ID=101:", get_similar_listings(0, top_k=2))
This example illustrates a purely content-based approach. In a real system, you might incorporate collaborative signals, multi-modal data, or specialized deep learning models.
Possible Follow-up Questions and Detailed Answers
1) What if there is a cold-start problem for new listings?
When you have a new listing that has not yet been interacted with (e.g., no bookings, no user clicks, no reviews), collaborative filtering alone might struggle because it lacks data about user interactions for that listing. Some strategies to handle this:
You can rely on content-based features to represent the listing even before it receives any user interactions. This means:
Extract embeddings from listing text descriptions.
Use location and price as immediate signals.
Possibly analyze images for style similarity.
In a hybrid system, the model can “fall back” on content-based representations for cold-start listings. Once enough user interactions come in, the collaborative filtering signals can gradually integrate.
A deeper nuance is ensuring new listings actually surface in the recommendation pipeline. That can be addressed by:
Having a candidate generation step that always includes new listings (with partial weighting).
Using a more exploration-oriented approach or an explore/exploit strategy (multi-armed bandits) to ensure some exposure for new listings.
2) How do you deal with huge listing catalogs and real-time performance?
As Airbnb has millions of listings, computing pairwise similarity in real-time can be expensive if done naively. Some key techniques to handle this at scale:
Approximate Nearest Neighbor Search: Tools like Faiss, Annoy, or ScaNN can index listing embeddings. They allow sub-second retrieval of the top-k similar listings without scanning the entire dataset.
Precomputations and Caching:
Precompute nearest neighbors offline for each listing. You can store the top-100 or top-1000 similar listings in a table or index. Then at query time, you only need to retrieve from that precomputed structure.
Periodically refresh these indices to keep them up to date.
Distributed Infrastructure: Employ distributed systems (e.g., Spark clusters) for batch processing of new embeddings, and serve them in a highly available environment.
3) How do you ensure diversity or novelty in recommendations?
Sometimes returning only the most “similar” listings can lead to a highly homogeneous set of recommendations. Users might want variety. Solutions include:
Re-ranking: After retrieving the top candidate listings by similarity, apply a second pass that ensures diversity. You might penalize listings that are too similar to each other, or you might incorporate business rules (e.g., show at least one cheaper option and one more expensive option).
Fairness and user context: You might want to ensure fair exposure among different hosts or property types. This can be done by customizing the re-ranking step with fairness constraints.
4) How would you handle changing user preferences or seasonality?
User preferences and behaviors can shift over time. Seasonality strongly affects travel: beach destinations might surge in summer, while ski cabins might spike in winter. To handle this:
Time-Aware Models: Capture temporal patterns in user behaviors and listing popularity. For example, you can weigh recent interactions more heavily in your collaborative filtering approach.
Real-Time or Near Real-Time Updates: Update embedding representations or popularity scores frequently (daily or weekly) so that new trends are not missed.
Context-Aware Recommendations: Consider the user’s travel dates, the season, or even local events in the listing’s location. You can incorporate these as additional features or as direct filters.
5) How can you handle interpretability of the recommendations?
Interpretability is often desirable. A user might want to know why certain listings are recommended:
Feature-Based Explanations: If you use content-based methods, you can highlight that these listings are similar in location, price range, or certain amenities.
Attention Mechanisms: If you use neural networks with attention, you could display the key words or features that contributed most to the similarity.
Embedding Visualizations: Internally, you might visualize listing embeddings in 2D using dimensionality reduction (like t-SNE or UMAP) to see clusters of similar properties. This helps product managers or data scientists grasp the structure.
6) How do you validate that a new approach is genuinely better?
Even if an offline metric (e.g., recall@k) looks better, the real proof is in online user engagement.
Incremental Rollout: Roll out the new system to a small user subset first, check user satisfaction and business metrics, and then expand.
A/B Test: Compare the new system (treatment) vs. the old system (control) to see if bookings and user happiness improve meaningfully.
Statistical Significance: Ensure that you gather enough data to measure small lifts in conversion or engagement with confidence.
7) What are potential pitfalls in building such a system?
Several pitfalls can occur in practice:
Sparse Data: Many listings may have too few user interactions, making collaborative filtering unreliable for them.
Over-Emphasis on Popular Listings: The model might learn that popular listings appear everywhere, overshadowing smaller or newer hosts. This can create a popularity bias.
Lack of Diversity: Purely similarity-based recommendations can produce repetitive sets. Users might get stuck in a filter bubble.
Misalignment with Business Goals: The notion of “similar” might not always correlate with what drives bookings or revenue. Always check the business objective (e.g., do you want to maximize booking rate? user satisfaction?).
Data Leakage: If you use future data inadvertently (e.g., some booking signals you shouldn’t have yet) or if your test set inadvertently overlaps with your training set.
8) How do you incorporate user-level personalization?
While “similar listings” might first appear purely listing-to-listing, user personalization can be beneficial:
User Embeddings: If the user is logged in, you can combine user preferences or past booking behavior to personalize the ranking. For example, for the same listing, a family with children might see listings with certain amenities (cribs, extra rooms), while a solo traveler might see smaller, cheaper properties.
Contextual Re-Ranking: After generating top similar listings, reorder them based on the user’s known preferences (price sensitivity, favorite locations, or styles from their history).
9) How do you track listing similarity over time?
Listings can change: hosts can update descriptions, prices, or add new amenities. You can:
Periodically re-compute embeddings or partial embeddings (e.g., if only the text changed, you can re-run the text embedding piece).
Rebuild or refresh your nearest neighbor indices at a frequency that balances computational cost with how dynamic the data is (e.g., every 24 hours or weekly).
10) Could you combine textual, image, and tabular data in a single deep learning model?
Yes. One approach is a multi-modal neural network:
Encode text using pretrained NLP models (e.g., BERT).
Encode images with a CNN or a pretrained image model (e.g., ResNet).
Include structured metadata (price, location) as additional input features.
Concatenate or fuse these representations in a final dense layer to get a comprehensive listing embedding.
Then you compute similarity between embeddings. This usually requires a large dataset and careful training to avoid overfitting.
Additional Follow-up Questions and Answers
How do you handle user privacy concerns when collecting user interaction data for collaborative filtering?
It is crucial to ensure compliance with data protection regulations (e.g., GDPR). You might:
Anonymize user IDs so that no personally identifiable information (PII) is stored in the model.
Only collect aggregate booking/click signals rather than storing a full log of every user’s activity in raw form.
Provide users with transparency and controls (e.g., allow them to opt out of data collection or to request data deletion).
Carefully handle potential data leaks (e.g., do not inadvertently store or expose private user comments).
What if listings are extremely diverse in location, style, or price?
The system might need domain-specific adjustments, for example:
Weighted similarity: Heavier emphasis on location for short-term rentals, or heavier emphasis on price for more budget-conscious segments.
Category-based approach: Possibly separate the inventory into categories (e.g., entire home, private room, or shared space). Compute similarity only within each category if that suits the business objective.
How do you keep the model fresh?
A typical pipeline for large-scale recommendation systems at FANG-level companies:
Nightly or near real-time updates to the training dataset.
Periodic re-training or at least partial re-fitting (e.g., warm-start the model with old weights and continue training on new data).
Incremental learning systems that update embeddings for new listings and new user interactions on the fly.
How do you handle extremely skewed user behavior?
Users might be unevenly distributed (some travel frequently, while others only open the site once or twice a year). This can cause model bias. Potential solutions:
Weighted training samples: Give more weight to under-represented segments.
Bucketing or segmentation: Segment users by usage frequency and build specialized models or incorporate domain knowledge.
Could you share an example of how you’d do an offline evaluation with MAP@k?


Then you take the mean over all users:
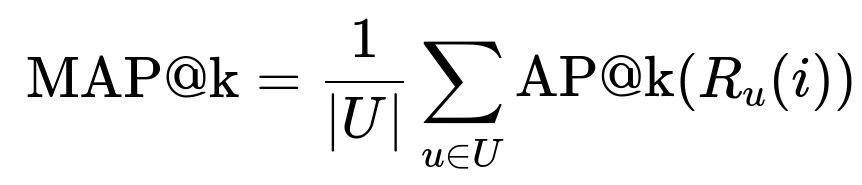
Where I[⋅] is an indicator function. This metric rewards you for placing relevant items early in the ranking.
How would you tune hyperparameters in a recommendation system?
Common strategies include:
Random search or Bayesian optimization over the embedding dimension, regularization coefficients, or dropout rates (if using neural approaches).
Cross-validation or offline hold-out sets for measuring MAP@k, nDCG, or other ranking metrics.
A/B testing to finalize the best hyperparameters in the production environment.
That addresses the main question about producing a model for recommending similar listings on Airbnb, discussing which type of model to use, what data is needed, and how it might be evaluated, as well as various subtle considerations that might arise during a real FANG-level interview process.
Below are additional follow-up questions
1) How do you handle fraudulent or malicious listings within the recommendation system?
Fraudulent or malicious listings can skew the similarity metric and negatively impact user trust. If certain hosts create listings with misleading descriptions or images, your system might inadvertently recommend them. You need strategies to identify and remove such content, or reduce its weight in the ranking.
A practical approach is to build a separate anomaly/fraud detection pipeline that flags suspicious listings based on:
Extremely low prices for properties that claim high-end amenities.
Repetitive textual patterns across multiple suspicious listings.
Negative user feedback or reports.
Once flagged, these listings:
Could be removed entirely from the recommendation index.
Could have their similarity score penalized until further review.
A subtle pitfall is that some malicious listings might become popular among users who are lured by misleading claims, producing artificially inflated interaction data. If that data is fed into your collaborative filtering model, it will incorrectly “amplify” those listings. Regular audits and robust anomaly detection are essential to mitigate this.
2) How do you adjust recommendations when a listing becomes temporarily unavailable?
A listing can be booked for a range of dates, effectively removing it from availability. If your system continuously recommends that listing, users might get frustrated. To handle this:
You can:
Dynamically filter out listings that have no availability for the user’s desired dates. If the user is planning a trip on a specific date range, only recommend listings that are actually open for those dates.
Maintain real-time or near real-time availability data. For large-scale systems, you often have a scheduling or caching layer that syncs listing calendars with the recommendation engine. This might be updated every few minutes or hours.
A pitfall is letting stale availability data linger. If you only refresh data daily, you risk recommending listings that are no longer free. That can decrease booking conversion and user satisfaction.
3) How do you handle multi-lingual or cross-lingual listings?
In many global markets, listings might have descriptions in various languages. Text-based embeddings need to handle multi-lingual data. You have several options:
Use a multi-lingual transformer model (e.g., a variant of BERT trained on many languages). This allows you to generate embeddings from text in multiple languages that reside in a shared semantic space.
Translate all non-English descriptions into English (or a chosen common language) before extracting embeddings. This can be simpler in some engineering pipelines but might introduce translation errors that degrade similarity metrics.
Maintain language-specific embeddings, and at retrieval time, detect the user’s language preference. Then, match them with listings that either share the language or have a validated translation.
An edge case is that some listings might be partially in one language, partially in another. You must detect that scenario to avoid incorrect embeddings or partial matches. Also, keep in mind cultural nuances: certain terms in one language may not map neatly to another, which can cause subtle mismatches in “similar” listings.
4) What if user feedback indicates that “similar” listings are too similar or boring?
Even though the model finds highly similar listings, user feedback might suggest they want slight variations—maybe a place that is in a new neighborhood but shares some core features. This can be addressed with diversity-boosting techniques or user preference weighting.
A specific approach:
Add a “diversity penalty” when the recommended listings are too similar to each other. For example, you can compute a pairwise distance among the top candidate listings and penalize sets whose average distance is below a certain threshold.
Provide an option for the user to refine what “similar” means. For example, if they are looking for bigger or cheaper places, the system can incorporate those signals as filters or re-ranking factors.
A subtle pitfall is that over-diversifying the list might deliver irrelevant recommendations. The art lies in balancing similarity with variety so that users remain engaged and discover new accommodations.
5) What if there are listings that are very unique and do not have obvious “similar” counterparts?
Some listings might be entirely unique—like a treehouse with a hot tub in the mountains—thus making content or collaborative filtering less straightforward. If a listing has very distinctive attributes, the system might fail to find “similar” listings that meet the user’s expectation of similarity.
Potential solutions:
Loosen similarity constraints. Instead of focusing on near-identical features, look for broader categories (e.g., “unusual experiences,” “nature-oriented properties,” or “off-grid cabins”).
Cluster listings in a higher-level category (like “glamping” or “unique stays”), and show top listings in that cluster.
Use user context signals. For instance, if the user specifically searched for “treehouse” or “nature retreat,” you can show them more conceptually similar experiences even if the physical attributes differ.
One subtlety is balancing user curiosity against the reality that few truly comparable listings exist. You might do a fallback to a broader similarity measure so that you’re always offering some recommendations, even if they’re not perfect matches.
6) How do you reconcile conflicting attributes in listings, like a listing that is both expensive but in a cheaper neighborhood?
Sometimes, the listing data might appear contradictory, e.g., “Ultra-luxury penthouse in a traditionally budget-friendly suburb.” A pure attribute-based similarity approach might get confused. You might need more sophisticated logic to weigh relevant attributes.
Strategies:
Weighted embeddings: Learn or define weights for each feature based on how reliably it predicts user preferences or how often it correlates with user interactions.
Hierarchical representation: Separate core listing features (location type, property type) from more fluid features (price, rating, style). This can help you handle complex scenarios where a single dimension is an outlier from typical expectations of the neighborhood.
Partial similarity approach: Instead of a single similarity score, break it down into multiple facets (price, style, location, user rating). Then combine them in a context-dependent manner for ranking.
A pitfall is if your system tries to treat conflicting data as missing or discards it entirely, thereby losing critical nuance. Instead, you want your model to adapt to the reality that unusual listings exist.
7) What happens if the user is not logged in or has minimal browsing history?
In such a scenario, collaborative filtering signals from that specific user are limited or nonexistent. The system may rely more heavily on:
Content-based or popular listings fallback. For example, show listings that are globally popular or that have high average similarity to many user-favored properties.
Contextual signals like the user’s geolocation (if they have granted permission) or the listing currently being viewed. If they are browsing a particular listing in Paris, you assume they might be interested in Paris-based accommodations with similar attributes.
Short-term session-based history. Even if a user is not logged in, you can store ephemeral data during their session. If they clicked on a couple of budget-friendly listings, your system can glean that they may be price-sensitive and recommend similarly priced accommodations.
A subtle real-world issue is ensuring that you do not collect or store personal data without user permission, and that ephemeral session data is handled securely and reset after the session ends for privacy compliance.
8) How do you incorporate negative feedback signals (e.g., a user repeatedly ignoring certain recommended listings)?
While positive feedback (clicks, bookings) is straightforward to incorporate, negative signals (like dwell time near zero, or the user scrolls past recommended listings) can also be informative. You can track:
Implicit negative signals: A user sees a recommended listing but never clicks. Over time, if that pattern repeats, it suggests a mismatch.
Explicit negative signals: Sometimes the user might be able to say “Not interested” or “Don’t show me this again.”
You can adapt your similarity-based model by penalizing listings that accumulate negative signals from a segment of users. For instance, you might reduce the similarity score or exposure of such listings to those or similar users in the future.
A tricky edge case is false negatives: maybe the user ignored a listing not because it was bad, but because they were simply short on time or got distracted. Over-penalizing that listing might reduce valid opportunities. Balancing negative signals against a user’s broader behavioral context is important.
9) How do you monitor and address inadvertent feedback loops?
A feedback loop can occur if the recommendation system always highlights certain listings, leading to increased clicks, which the model interprets as higher relevance, causing it to recommend them even more. This creates a cycle.
Ways to mitigate this:
Random exploration or controlled rotation. Even high-traffic listings occasionally get replaced by under-exposed listings to gather fresh feedback.
Normalizing popularity or discounting “position bias.” When you measure success, account for the fact that top-ranked items get more clicks purely due to position.
Regularly evaluate if the top recommended listings remain the same over time, ignoring potential better options.
A subtlety is that purely random exploration might degrade user experience if done too aggressively. Balancing user satisfaction with the need to mitigate feedback loops is an ongoing challenge.
10) How do you incorporate star ratings or review sentiment into similarity?
Listings often have star ratings and textual reviews. These can be rich signals of listing quality and style. You can incorporate them by:
Using average star rating or aggregated sentiment as an additional feature in the listing embedding. Possibly weigh it so that listings with extremely low ratings are deemed less similar to well-reviewed ones.
Parsing textual reviews with NLP to identify specific themes. For instance, if both listings are praised for “cozy interior” or “walkability,” that might indicate deeper similarity.
Distinguishing between overall rating and dimension-specific ratings (cleanliness, accuracy, location), then matching them in a multi-dimensional rating space.
An edge case is listings with few or no reviews. Overreliance on ratings can push those new or under-reviewed listings out of recommendations, exacerbating the cold-start problem.
11) How do you localize your model to specific regions or markets?
Different regions might have different user behaviors and listing attributes (e.g., typical size, amenity standards, price range). A single global model might perform sub-optimally if it does not account for regional variance.
Strategies:
Train region-specific or market-specific models that handle local inventory. This is common if you have sufficient data within each region.
Use a single global model but include region as an embedding or feature. The model can learn region-based differences in user preferences or listing distributions.
Weighted integration: If a user is looking at listings in Berlin, weigh interactions or listing data more from the European region than from the U.S.
A subtlety is deciding how granular to go. Training a model for every city might be overkill or result in data sparsity. Larger regions (e.g., country-level or major city clusters) is often a better compromise.
12) How do you handle updates to the underlying listing representation (e.g., if the feature schema changes)?
Over time, the data pipeline might evolve. You could add new attributes (like a new amenity type) or remove old ones. This can lead to mismatch or breakage in the embedding pipeline if not carefully managed.
Best practices:
Use a robust feature store or schema management system that tracks versioning of features. The system can gracefully handle missing or newly added features.
If an attribute is discontinued, you can retire it from the embedding. If an attribute is new, you can incorporate it and treat missing historical values with appropriate defaults.
Retrain or partially finetune the model so it adapts to the new schema.
A subtle pitfall is inadvertently changing feature definitions or data transformations in ways that make historical embeddings incompatible with newly computed embeddings. A consistent, versioned approach is key to avoiding these issues.