
ML Interview Q Series: Solving Drink Order Probability (2 Coffees, 3 Teas) Using Combinatorics.

Browse all the Probability Interview Questions here.
QuestionFive people are sitting at a table in a restaurant. Two of them order coffee and the other three order tea. The waiter forgot who ordered what and puts the drinks in a random order for the five persons. Specify an appropriate sample space and determine the probability that each person gets the correct drink.
Short Compact solution
Consider an ordered sample space of all possible 5! ways the waiter can distribute the two coffees and three teas to the five individuals. Among these 5! arrangements, exactly 2! x 3! correspond to the situation in which the correct two people receive coffee and the correct three people receive tea. Therefore, the probability is (2! x 3!) / 5! = 0.1.
Alternatively, in an unordered sample space, there are (5 choose 2) ways to select which two people get coffee. Exactly one of these ways is the correct allocation. Hence the probability is 1 / (5 choose 2) = 0.1.
Comprehensive Explanation
Defining the Sample Space
One straightforward approach is to label each of the five individuals distinctly (say Person 1, Person 2, Person 3, Person 4, Person 5). We can then imagine the waiter assigning the two coffees and three teas in a random manner.
Ordered approach: We consider every possible way to distribute five distinct beverages (two coffees, three teas) to five distinct people. Because the coffees and teas are presumably identical within their type, one way to count is to look at permutations of 2 coffees and 3 teas assigned to five distinct seats or persons. There are 5! total ways to arrange the sequence (Coffee, Coffee, Tea, Tea, Tea) if we label each position as going to a different person.
Unordered approach: We can consider the set of all ways to choose exactly two of the five people to receive coffee (and thus the remaining three get tea). In that case, the size of the sample space is (5 choose 2).
Both approaches will give the same final probability.
Counting the Favorable Outcomes
What does "favorable" mean in this context? It means exactly the scenario in which the same two individuals who originally ordered coffee actually receive coffee, and the other three who ordered tea receive tea.
In the ordered approach: Out of the 5! permutations, the number of permutations where the two people who want coffee indeed get coffee (and the other three get tea) is 2! x 3!. Here, 2! counts how we assign the two identical coffees among the two coffee drinkers (which effectively is just 1 arrangement, but if we view them as permutations among seats, we keep that 2! factor), and 3! counts how we assign the three identical teas to the three tea drinkers. Dividing by 5! gives the desired probability.
In the unordered approach: There are (5 choose 2) ways to pick which two out of five people get coffee. Only one of these ways is correct (the way that picks exactly the two original coffee drinkers). Hence the probability is 1/(5 choose 2).
Final Probability
We can express the probability in either of the two ways. They are equivalent:

or
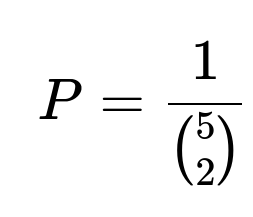
When you simplify these expressions, both evaluate to 0.1.
Why Both Approaches Are Consistent
Ordered perspective: We are enumerating all permutations of distributing five labeled positions among the identical drinks. The total permutations are 5!, while the favorable permutations match the unique arrangement that satisfies each person’s true beverage choice.
Unordered perspective: We merely count in how many ways we can choose which two people get coffee, ignoring any notion of order. Only one choice of two coffee drinkers is correct, so the probability is the reciprocal of (5 choose 2).
Intuitive Explanation
No matter how you slice the sample space (ordered or unordered), the essential combinatorial argument is that there is only one correct matching between drinks and people among all possible matchings. The fraction of correct matchings to total matchings is therefore 1 over the number of ways to match the drinks incorrectly.
Follow-up Question 1
How can we be certain that using (5 choose 2) in the unordered sample space captures all possibilities?
When constructing the unordered sample space, each outcome corresponds to a choice of exactly two people (out of the five) to receive coffee. Since the coffees are indistinguishable and the teas are indistinguishable, each selection of two people is a distinct outcome in the sample space. This precisely describes every distinct distribution of coffee/tea. Hence, there are (5 choose 2) total ways to allocate two coffees among five people, covering all possibilities without either duplication or omission.
Follow-up Question 2
Why does the numerator become 2! x 3! in the ordered approach? If the coffees are identical, shouldn’t we just have 1 way to assign them?
This counting is subtle because of how the sample space was defined. In the "ordered" version, we imagine every permutation of the five seats or people as a distinct arrangement—like assigning positions 1 and 2 to coffee, 3, 4, and 5 to tea, etc. If you think purely in terms of seat-labeled permutations, there are 5! ways for the waiter to place the items. In that viewpoint, the scenario where Person A gets coffee and Person B gets coffee is distinct from the scenario where Person B gets coffee and Person A gets coffee, if we label the seats or the “slots” differently. However, among all these permutations, to have the correct two people get the coffees, we effectively count 2! x 3! as the permutations that keep the correct people assigned to coffee vs. tea. Dividing that count by 5! then gives the correct probability of 0.1.
Follow-up Question 3
What if we wanted the probability that exactly three specific people got their correct drink, regardless of whether the other two are correct?
This is a more involved question, because you have to consider how to choose which three people will be correct and in how many ways the other two can end up incorrect. Specifically:
You first choose the three individuals out of five who get their correct drinks.
Then you must ensure the remaining two do not get their correct drinks (for instance, if the remaining two both originally ordered coffee, it’s impossible for them both to be "incorrect" if we only have two coffees or three teas total).
You would carefully enumerate the ways the remaining two can be “swapped” incorrectly and sum over all possible sets of three who are correct.
Such computations often involve the concept of derangements for the incorrectly assigned ones, especially if each drink is distinct. If the drinks are not distinct, you must factor in identical-coffee vs. identical-tea constraints, leading to a slightly more nuanced combinatorial count.
Follow-up Question 4
How would we code a quick simulation in Python to empirically verify this probability?
Below is a simple Python snippet that simulates random assignments of two coffees and three teas to five people, checking how often the assignment is correct:
import random
import math
import numpy as np
num_trials = 10_000_00
correct_count = 0
# Let's label coffee = 1, tea = 0 for convenience
actual_orders = [1, 1, 0, 0, 0] # 1 means coffee, 0 means tea
# This can be permuted but let's assume the first two are coffee, next three are tea
for _ in range(num_trials):
# Randomly shuffle the actual_orders to simulate the waiter's random assignment
shuffled = np.random.permutation(actual_orders)
# Check if all match:
if np.array_equal(shuffled, actual_orders):
correct_count += 1
empirical_probability = correct_count / num_trials
print("Empirical Probability of everyone getting correct drink:", empirical_probability)
By running this simulation with a sufficiently large num_trials, you would see the resulting estimate converge near 0.1, confirming our theoretical derivation.
Below are additional follow-up questions
If we wanted the probability that exactly one of the coffee drinkers receives coffee, how would we compute it?
When we say "exactly one coffee drinker gets their correct drink," we are focusing on the event where one of the two intended coffee drinkers ends up with coffee, while the other coffee drinker does not. In addition, the three tea drinkers can receive tea or coffee in any combination, as long as the total constraint of exactly two coffees and three teas holds across all five people.
To break it down:
Identify which one of the two original coffee drinkers will be correct. There are 2 ways to choose which coffee drinker gets coffee correctly.
That chosen coffee drinker receives coffee, but the other coffee drinker must receive tea.
Out of the remaining three tea drinkers, exactly one must receive the other coffee (since only one of the two original coffee drinkers is getting coffee, the other coffee must go to someone from the tea group).
So we pick 1 tea drinker out of the 3 to receive the second coffee, which can be done in 3 ways.
Everyone else in the tea group (the remaining 2 tea drinkers) receives tea.
Number of favorable ways = 2 (which coffee drinker is correct) x 3 (which tea drinker gets the other coffee). That is 6 possible ways to have exactly one coffee drinker correct. However, this is counting in terms of the unordered perspective (like “which two people end up with coffee?”). There are (5 choose 2) = 10 total ways to distribute the two coffees among five people. Hence the probability is 6/10 = 0.6.
A subtle pitfall here is mixing up the condition that "exactly one coffee drinker is correct" with “exactly one total person is correct.” We specifically mean exactly one of the two original coffee drinkers has coffee, but the tea drinkers are not all necessarily correct (in fact, at least one tea drinker has coffee in that scenario). Paying attention to these subtle distinctions in wording is crucial.
What if the waiter does not assign the coffees and teas uniformly at random?
The entire probability calculation hinges on the assumption that each of the possible ways the waiter distributes the two coffees and three teas is equally likely. However, in a real-world scenario, it might be that the waiter has some bias—perhaps they vaguely remember certain individuals who wanted coffee and thus is more likely to assign coffee to them. In such a case, the sample space might still contain the same 5 choose 2 outcomes, but they no longer all have equal probabilities.
To address this, we would need a probability distribution over the ways the waiter could assign coffee and tea. For instance, if the waiter assigns coffee to a certain person with probability p instead of 2/5, we would have to sum over each distribution combination weighted by its probability. The probability model might look like a multinomial or a Bernoulli trial approach across the five people, but each with a unique p. The final probability of the correct assignment would be the probability mass the distribution places on the one correct arrangement. Without uniformity, the combinatorial formula (1 / (5 choose 2)) is no longer valid.
A real-world pitfall is assuming uniform randomness when it is not actually present. In practice, data or memory cues might skew the distribution.
How does the calculation change if the two coffees are distinct and the three teas are also distinct?
The previous reasoning assumed coffees are indistinguishable from each other, and teas are likewise indistinguishable among themselves. If you label the coffees differently (say Coffee A and Coffee B) and the teas differently (Tea 1, Tea 2, Tea 3), the sample space changes drastically:
The total number of ways to distribute 5 distinct drinks to 5 distinct people is 5! = 120 in the original logic, but now each of the 5 drinks is unique. So we actually have 5! ways for distinct drinks, but they are not all the same scenario in terms of "who gets coffee vs. tea." Within that 5!, each distinct coffee assignment is a different outcome.
If we are only interested in ensuring that each of the two coffee drinkers gets “some coffee” (doesn’t matter which coffee) and each tea drinker gets “some tea” (doesn’t matter which tea), the correct arrangements are:
The 2 coffee drinkers can receive either Coffee A or Coffee B in 2! ways among themselves.
The 3 tea drinkers can receive Tea 1, Tea 2, Tea 3 in 3! ways among themselves.
Overall, there are 2! x 3! = 12 correct permutations.
Hence the probability under the assumption of distinct coffees and teas is (2! x 3!) / (5!) = 12 / 120 = 1/10 again = 0.1.
A subtlety is that enumerating all permutations 5! is now exactly correct in the sense of distinct items. The difference is that in the “all distinct” scenario, each of those 5! permutations is equally likely if the waiter is truly random in how they place each distinct item. We end up with the same probability, but the reasoning for the sample space is slightly different, and it is reassuring that it matches. In more complicated settings, e.g., if some items are more “memorable” to the waiter, or if the items themselves have unique attributes that lead to a non-uniform distribution, the result might not remain so straightforward.
How would the probability look if we accounted for partial correctness, such as awarding partial credit for each correctly assigned coffee or tea?
Sometimes we might be interested in an expected number of correct assignments, i.e. how many individuals typically receive the right beverage. In that sense, we are not just looking for the probability that everyone is correct, but rather the expected value of “number of correct matches.”
A standard approach is to use linearity of expectation. Let X be the random variable denoting how many of the five people get the correct drink. Then X = X1 + X2 + X3 + X4 + X5, where Xi is an indicator variable that is 1 if Person i gets their correct drink, and 0 otherwise. By linearity of expectation, the expected value of X is E[X] = E[X1] + E[X2] + … + E[X5].
For each Xi, the probability that Person i gets their correct drink is 2/5 if that person ordered coffee (because among five seats, two coffees are distributed randomly) or 3/5 if that person ordered tea. For the two coffee drinkers, E[Xi] = 2/5 = 0.4 each, and for the three tea drinkers, E[Xi] = 3/5 = 0.6 each. Thus, total E[X] = 2 x 0.4 + 3 x 0.6 = 0.8 + 1.8 = 2.6. On average, you expect 2.6 people to get the correct drink, even though the probability that all 5 are correct is 0.1.
A potential pitfall is confusing the expected number correct with the probability that all are correct. The probability that all five are correct is 0.1, but the average number of correct assignments (2.6) is significantly higher, simply because there are multiple ways to get partial correctness.
What happens if there are constraints, such as the waiter recognizes at least one person who had coffee?
Imagine a situation where the waiter confidently knows that Person A definitely had coffee, so the waiter always gives coffee to Person A, but distributes the other coffee and teas randomly among the remaining four people. In that scenario, the probability space changes:
Now the coffee distribution to Person A is fixed. We only randomly assign the remaining 1 coffee and 3 teas to the remaining 4 people.
The sample space for the remaining four people is (4 choose 1) = 4 ways to assign the second coffee among the remaining four people.
The correct scenario requires that the second coffee also goes to the other rightful coffee drinker among those four, which is 1 favorable possibility out of 4. So the probability that both coffee drinkers get their coffee in that situation is 1/4 = 0.25, a higher probability than 0.1 because we have some extra knowledge.
This is a real-world pitfall: partial knowledge changes the sample space or modifies probabilities, and ignoring that knowledge can lead to incorrect calculations.
How would this probability generalize to x coffee drinkers and y tea drinkers, with x + y = n?
You can extend the same reasoning:
If we have n total people, x of whom ordered coffee and y of whom ordered tea, the sample space (unordered) consists of (n choose x) ways to pick which x people out of n receive coffee. Only one of those ways is correct if we only care about each individual’s beverage type.
Hence the probability that everyone receives the correct drink is 1 / (n choose x).
Equivalently, from an ordered perspective, the total number of permutations is n!, and the number of permutations in which the correct x people receive coffee (and the other y get tea) is x! * y!. Thus, the probability is (x! * y!) / n!.
A potential pitfall in large n is forgetting that we might be dealing with very large combinatorial numbers. Directly computing factorials can lead to overflow in many programming languages, and we might need to rely on approximations or carefully use arbitrary-precision libraries.
Could there be a scenario where individuals are interchangeable, but the seats are not?
Yes, if the seats themselves are labeled differently (for instance, seat #1 is near the window, seat #2 is near the door, etc.), then from the perspective of the waiter, seat #1, seat #2, … seat #5 might form the fundamental “slots” for distributing the two coffees and three teas. If the individuals are physically moving around, or if we do not distinguish them once they’re seated, it gets trickier. Usually, in practice, each person is distinct, but sometimes the seats may be the only “identities” if we can’t tell the individuals apart. Carefully defining who or what is being labeled is essential in probability questions. A common pitfall is mixing up seat-labeled permutations with person-labeled permutations.
If we incorporate random "no-shows" or an extra person, how does that impact the probability calculation?
Imagine a scenario in which there are five orders placed, but one person leaves early, so the waiter only needs to distribute among four present guests (but still has five drinks, or forgets how many drinks remain). That changes the entire combinatorial framework, because the number of guests might not match the number of drinks. You’d have to adjust the sample space to account for the mismatch:
If the waiter is forced to leave out one drink or give a single person two drinks, the sample space would be quite different from the simple “2 coffee, 3 tea for 5 people” scenario.
The combinatorial count and probabilities need to be recalculated carefully, or the question itself might no longer be well-defined in the same sense (“correct drink for each person” might not be possible if there are more beverages than people).
A subtle pitfall is failing to update the problem assumptions when real-world constraints (like the number of people at the table vs. the number of drinks) change.
How can we adapt the logic if some people ordered the same beverage, but with different variations (for example, two people order cappuccino, one orders latte, and two order tea)?
In a real restaurant, “coffee” might not be a single type—someone might order decaf, another might order espresso, etc. If we treat each variation as distinct (cappuccino, latte, decaf, espresso, green tea, black tea, etc.), then we need to incorporate those distinctions in counting:
If each coffee type and tea type is truly distinct, we expand our sample space to permutations of five unique items (a cappuccino, a latte, etc.).
If some items are identical or partially identical, it introduces partial interchangeability in the counting. For instance, two cappuccinos are identical to one another but distinct from a latte. The logic can get intricate because we might have partial lumps of identical items.
A common pitfall is to oversimplify “coffee vs. tea” when in fact the problem might involve more nuanced real-world distinctions.
If a large number of people each order coffee or tea with some probability p, how would we estimate the probability that k people get the correct drink?
When the number of people n becomes large, it can be computationally expensive to do an exact combinatorial calculation for every distribution. Instead, you might use approaches like:
The Binomial distribution approach if you imagine each person has a probability p of having ordered coffee and the waiter randomly assigns coffee with probability p.
A normal approximation to the binomial for large n to estimate the probability that exactly k matches occur.
These approximations rely on independence assumptions: each person’s assignment is decided independently (with some probability of coffee vs. tea). If the total coffee count is constrained to exactly x, you might use a hypergeometric or a more specialized combinatorial approach. The big pitfall in large-scale scenarios is ignoring constraints or correlation in random assignments, leading to over- or under-estimates.