
ML Interview Q Series: Under what circumstances is it preferable to utilize optimizers like Adam, rather than standard stochastic gradient descent?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Stochastic Gradient Descent (SGD) updates parameters by using the average of gradients on a mini-batch. In many scenarios, especially with large datasets and well-conditioned optimization surfaces, SGD can be sufficient for training deep neural networks. However, certain architectures or data regimes can cause SGD to converge slowly or get stuck in regions with very small or highly noisy gradients. To address these difficulties, optimizers such as Adam incorporate adaptive learning-rate mechanisms.
Adam essentially keeps an exponential moving average of the gradients and their squares, enabling it to adjust the learning rates for each parameter dimension independently. By doing so, it more efficiently navigates sharp curves or ravines and can handle sparse gradients better. The algorithm’s adaptive nature is particularly beneficial in problems like NLP or CV tasks where gradients might exhibit high variance or be heavily skewed.
To see the core parameter update rule for Adam, we can write the final update expression:
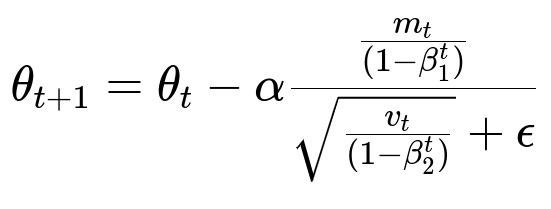
Here, theta_{t} denotes the model parameters at iteration t, alpha is the base learning rate, m_{t} is the exponentially weighted average of past gradients, v_{t} is the exponentially weighted average of past squared gradients, beta_{1} and beta_{2} are the coefficients controlling the exponential decays, and epsilon is a small constant for numerical stability. The terms (1 - beta_{1}^{t}) and (1 - beta_{2}^{t}) in the denominator correct for the initial bias because at the start of training, the running averages can be zero-initialized.
Adam, thus, automatically rescales parameter updates for each component. This is advantageous when certain parameters consistently receive large or small gradients. However, in more stable or simpler tasks, standard SGD (sometimes with momentum) can yield better generalization and a more predictable training trajectory. Hence, Adam might be most appealing in cases with sparse or noisy gradients, varying gradient magnitudes across parameters, or in contexts where manual tuning of the learning rate is non-trivial.
Key Considerations
Adaptive Rate Advantage Adam’s dimension-wise adaptive step sizes let parameters with small but consistent gradients get larger updates than they would under plain SGD. This feature is beneficial in tasks where different layers or parameter groups require significantly different learning rates, or in contexts with complex loss surfaces and high curvature directions.
Convergence Behavior SGD can converge robustly when the learning rate is carefully scheduled (for example, gradually decreasing the learning rate or using momentum). However, tuning the hyperparameters of SGD may demand more trial-and-error. Adam, by design, requires less manual scheduling of the learning rate, though it does introduce hyperparameters like beta_{1}, beta_{2}, and epsilon.
Generalization Sometimes, plain SGD with momentum can produce superior generalization performance compared to Adam in certain well-known benchmarks. Adam’s rapid convergence might occasionally skip potentially helpful plateaus or narrower minima. In practice, many developers combine different strategies, such as starting with Adam and then switching to SGD at a certain epoch.
Sparse Gradients Architectures with embeddings (e.g., NLP tasks) often have sparse gradient updates in their embedding layers. Adam shines here by giving sufficient magnitude to these sparse updates, whereas vanilla SGD might make only minimal progress if the gradient for those embeddings appears infrequently.
Potential Pitfalls and Real-World Scenarios
Excessive Reliance on Default Hyperparameters Adam’s default beta_{1}, beta_{2} might not be ideal for all tasks. If they’re set inappropriately, the optimizer may accumulate excessive momentum or variance estimates, leading to suboptimal updates.
Generalization Gaps Although Adam converges quickly, it doesn’t always yield a better final test error. In some image classification tasks, plain SGD (with momentum or Nesterov acceleration) may outperform Adam in terms of test accuracy. One workaround is to combine adaptive optimizers with carefully tuned learning rate decays or to switch to SGD after an initial training period with Adam.
Exploding Gradients Even though Adam helps mitigate some exploding gradient issues via adaptive updates, it is still possible for parameters to blow up if the overall learning rate alpha is too large or if the network initialization is unstable.
Common Follow-Up Questions
Why do we often see Adam used in NLP tasks and SGD with momentum in many vision tasks?
In natural language processing, certain weights (like embedding vectors for rare words) might receive very few gradient updates. Adam’s mechanism ensures these weights are adapted sufficiently whenever gradients do arrive, preventing them from being neglected. Meanwhile, in many computer vision tasks with huge amounts of data, the gradient flow can be relatively consistent. Here, SGD with a well-crafted learning rate schedule can generalize effectively and reduce overfitting, partly because it enforces a more uniform update rule.
Can one optimizer be universally considered “better” than the other?
No single optimizer is always superior. Adam converges quickly and requires less manual tuning but may not always yield the best final performance. SGD with momentum might demand more hyperparameter experimentation but can achieve excellent results, especially in stable tasks. The choice often depends on the dataset size, distribution of gradients, model architecture, and the time you have to tune hyperparameters.
Is it possible to switch between Adam and SGD in the middle of training?
Yes. Some practitioners start with Adam to converge rapidly in the early epochs, benefiting from large, adaptively scaled updates. Then they switch to SGD (with momentum) after a certain iteration or epoch to refine the solution and improve generalization. This hybrid strategy can harness the fast progress of Adam and the robust final convergence properties of SGD.
How does the bias-correction term affect Adam during early iterations?
In Adam’s update rules, the division by (1 - beta_{1}^{t}) and (1 - beta_{2}^{t}) corrects the biased estimates of the first and second moments of the gradients, especially during early training when t is small. Without this bias correction, the estimated moving averages for the gradient and its square might be underestimated, leading to updates that are not properly scaled. The bias-correction factor ensures that the expected values of m_{t} and v_{t} are unbiased.
Are there situations where simpler momentum-based methods outperform Adam in practice?
In well-understood tasks or datasets where gradient statistics are relatively uniform, SGD with momentum can match or exceed Adam’s performance and often yield better generalization. Because Adam adapts each parameter update, it can sometimes overfit or wander into noisier minima. On many traditional benchmark tasks (e.g., CIFAR-10, ImageNet classification), carefully tuned SGD with momentum remains a gold standard.
How to decide on a learning rate schedule for Adam?
While Adam can tolerate a relatively stable learning rate, tuning might still be beneficial. Some people employ a fixed learning rate for Adam, but others use a decay schedule, such as reducing the rate by a factor once the loss plateaus. Techniques such as learning rate warmup can also help stabilize the initial training phase, especially for large batch sizes or very deep networks.
By understanding these diverse considerations and potential pitfalls, engineers can decide when Adam is more appropriate than standard SGD, and vice versa.
Below are additional follow-up questions
How does memory usage differ between Adam and SGD?
Adam needs additional data structures to store running averages of past gradients and squared gradients for each parameter. In a deep network with millions of parameters, this can translate into a noticeable overhead. Specifically, Adam generally maintains two extra buffers for every parameter: one for the first moment (the average of gradients) and another for the second moment (the average of squared gradients). Meanwhile, plain SGD (with or without momentum) stores only a single buffer for each parameter if momentum is used (that single buffer holds the velocity or momentum term).
In memory-constrained environments (e.g., training on limited GPU memory), this overhead can become a practical bottleneck. If a practitioner wants to train larger models or use bigger batch sizes but is memory-limited, switching from Adam to a simpler optimizer may help free up memory. The trade-off is that Adam’s adaptive updates might speed up convergence or handle sparse gradients better, so there is a performance–memory trade-off to consider. Some frameworks also offer memory-optimized variants of Adam that reduce overhead, but they often require careful tuning or come with subtle performance drawbacks.
How do large batch sizes affect Adam compared to SGD?
When the batch size is large, the gradient estimates become more stable and less noisy. Under large-batch training, plain SGD can see more consistent gradient signals, making it easier to tune a decaying learning rate schedule. However, large-batch training can sometimes lose the implicit “regularizing” effect that arises from the noise of small-batch updates.
Adam often handles noisy or skewed gradients well, but with extremely large batches, its primary advantage of adaptive scaling may become less critical. Also, large batches may lead to high variance in second-moment estimates if the distribution of gradients changes significantly between updates. As a result, one might find that while Adam still works, it requires more precise hyperparameter adjustments—particularly in the learning rate and beta coefficients—because the second-moment accumulations can grow quickly and cause over-correction or slower convergence.
Can Adam cause divergence in certain scenarios where SGD remains stable?
Although Adam is robust in many circumstances, there are specific scenarios where it can diverge more easily if not tuned properly. For example, if the learning rate is too high or if the beta_{1} or beta_{2} parameters do not match the gradient characteristics, the adaptive steps can accumulate large momentum-like effects, leading to updates that jump chaotically through parameter space.
In contrast, plain SGD with a reasonably sized learning rate might still remain stable in these same conditions because it does not accumulate those adaptive per-parameter updates. In highly non-convex loss landscapes, Adam’s adaptive nature can sometimes magnify existing fluctuations instead of dampening them, especially if the network exhibits extreme gradient values in isolated regions. Careful tuning of Adam’s hyperparameters (particularly the base learning rate and the exponential decay rates for the moments) often resolves these issues.
How do partial freezing or partial training strategies differ for Adam vs. SGD?
Partial freezing involves keeping some layers’ weights fixed while only training others. This strategy is commonly employed in transfer learning scenarios where lower (feature extraction) layers might be frozen, and only the higher (task-specific) layers are updated.
With Adam, each trained parameter has its own first and second moment estimates. If you freeze a certain set of parameters halfway through training, the accumulated moments for those parameters become irrelevant because they will no longer be updated. For the layers that remain trainable, Adam continues to adapt their updates as usual.
By contrast, SGD (with or without momentum) only keeps momentum buffers for each trainable parameter. If a portion of the model is frozen, any stored momentum for those parameters typically remains unused, and only the momentum for the still-trainable layers remains relevant. The difference in practice is often minimal in terms of performance, but it’s important to note that Adam can require more memory even for those partially frozen layers unless you explicitly clear or exclude them from the optimizer’s parameter groups.
Does the adaptive nature of Adam ever degrade interpretability compared to SGD?
In some highly specialized applications, interpretability can hinge on understanding the magnitude and direction of gradient updates. Adam’s per-parameter adaptive scaling can obscure simpler relationships between gradient signals and parameter changes. If you rely on analyzing raw gradients to understand how specific features or neurons are being adjusted, Adam’s updates may be less straightforward to interpret.
With SGD, each parameter is updated by a relatively uniform rule, so you can directly interpret the scale of a gradient’s effect on that parameter. Adam modifies each parameter’s effective learning rate dynamically, which might make direct gradient analysis more complex. In most mainstream applications, this difference is negligible because interpretability often focuses on model activations and outputs rather than the step-by-step weight updates. But in research contexts that involve analyzing gradient behavior, this might matter more.
Are there unique considerations for sequence models (e.g., RNNs) when deciding between Adam and SGD?
Sequence models such as RNNs (including LSTMs or GRUs) can exhibit complicated gradients (especially with long sequences) where vanishing or exploding gradients may occur. Adam’s adaptive updates can provide more stable training early on, helping to mitigate exploding gradients by automatically adjusting step sizes. It is also beneficial in the presence of sparse updates (for instance, when many timesteps do not contribute significantly to certain parameters).
However, in tasks where you have well-tuned gradient clipping mechanisms or specific architectures that address exploding and vanishing gradients (like certain gating mechanisms), SGD with momentum or a carefully tuned learning rate schedule might be enough. Some practitioners find that once an RNN model is well-initialized and gradient clipping is in place, plain SGD yields better final performance or generalization.
When training very deep networks, do we need to tweak Adam’s hyperparameters differently than for shallow networks?
Extremely deep architectures (like ResNets of hundreds or thousands of layers, or large Transformer models) can exhibit gradients of widely varying magnitudes across different layers. Adam’s default beta_{1}, beta_{2} values might work adequately in many cases, but very deep networks can make the second-moment estimates (v_{t} in Adam’s formulation) grow large for certain layers if the gradient distribution is skewed. This can reduce the effective learning rate for those layers significantly, sometimes too aggressively.
As a result, some practitioners lower beta_{2} or introduce warmup phases so that the optimizer does not over-accumulate the squared gradient too soon. Additionally, applying layer-wise learning rate scaling or weight decay can help maintain stable convergence. Such tweaks can be more critical in Adam than in SGD because Adam’s second-moment adaptation might be prone to over-correcting in extremely deep networks.
What are the challenges in hyperparameter selection for Adam vs. SGD under tight resource constraints?
Under tight resource constraints (such as limited compute time or memory), you might have fewer iterations available for hyperparameter tuning. Adam’s default parameters are often considered “safe” starting points, but these still might not be optimal for every problem. If your training budget allows only minimal tuning steps, using Adam’s defaults can be acceptable for quick convergence.
On the other hand, SGD with momentum typically requires more careful scheduling of the learning rate (e.g., step decay, cosine annealing). If done right, this can yield strong results but demands time to find the best schedule. In resource-constrained environments, the inability to experiment with different schedules might mean suboptimal performance. Therefore, a practical approach might be to start with Adam to get a decent baseline quickly. If time permits, you can then explore SGD with different schedules to see if there’s a performance boost.
How does Adam behave under distributed training compared to SGD?
In distributed training settings (e.g., data-parallel or model-parallel approaches), synchronizing the additional moment vectors required by Adam can introduce extra communication overhead. Every worker maintains its local estimates of the first and second moments, and these must be periodically aggregated or synchronized across the cluster to ensure consistent updates.
SGD with momentum also needs synchronization of velocity terms, but that is typically a single buffer, which may be simpler to integrate. With Adam, the complexity doubles because you have two separate moment estimates. The difference in overhead might be negligible for small to medium-sized models, but at massive scale, it can become a real factor. Practitioners sometimes switch to simpler optimizers or variants of Adam that reduce communication overhead (e.g., using mixed-precision or block-wise quantization of moment buffers).
Can Adam cause overfitting more quickly than SGD in certain cases?
Adam’s faster adaptation might lead the model parameters to fit peculiarities of the training set more aggressively. This can be seen as beneficial when you have noisy or sparse data, but it also risks locking onto idiosyncrasies of the training examples. By contrast, SGD’s slower and more uniform approach can act as a mild regularizer, delaying overfitting.
In practice, controlling overfitting often relies more on factors like early stopping, regularization (L2 weight decay, dropout, data augmentation), and carefully scheduling the learning rate. But it is true that in tasks where you have limited data or highly noisy datasets, Adam’s strong adaptivity can hasten a move toward local minima that overfit. It is always advisable to monitor validation performance closely and apply robust regularization strategies to mitigate these effects.