
ML Interview Q Series: Under which circumstances can a diagonal matrix be inverted?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
A diagonal matrix can be inverted if and only if each of its diagonal entries is nonzero. In general, a matrix is invertible only if its determinant is nonzero. For a diagonal matrix, the determinant is the product of its diagonal elements. If any of those diagonal elements is zero, the determinant will be zero, and the matrix will not be invertible.
Below is the core formula for the determinant of a diagonal matrix D with diagonal entries d_{11}, d_{22}, ..., d_{nn}:
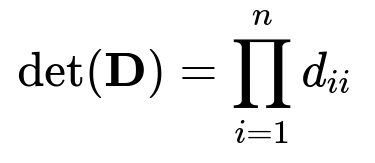
All factors d_{ii} must be nonzero for the product to remain nonzero. Consequently, this matrix’s inverse, when it exists, is simply a diagonal matrix of reciprocal entries. In other words, if diagonal matrix D is invertible, each diagonal element d_{ii} can be replaced by 1/d_{ii} in the inverse. The formula for the inverse of a diagonal matrix D with diagonal entries d_{11}, d_{22}, ..., d_{nn} (all nonzero) is:

Within this expression, d_{ii} refers to the i-th diagonal entry of the original matrix, and 1/d_{ii} is its reciprocal in the inverse. This compact representation provides a fast way to compute the inverse without requiring more expensive matrix decomposition methods.
In practice, when dealing with floating-point arithmetic (e.g., in deep learning frameworks like PyTorch or TensorFlow), you also have to watch out for very small diagonal entries which can cause numerical instability. Although small entries are not strictly zero, they may lead to large numerical errors when taking the reciprocal.
Potential Follow-Up Questions
How do we handle numerical issues if some diagonal entries are extremely small?
One approach is to add a small positive constant to the diagonal entries before inverting (sometimes referred to as a “regularization” term or “Tikhonov regularization”). For instance, in many machine learning and deep learning scenarios (such as covariance matrix inversion), a small term lambda may be added to each diagonal entry to ensure all entries stay above a safe threshold. This prevents the issues of blowing up a near-zero element and helps stabilize training.
For example:
import numpy as np
D = np.diag([1e-10, 2.0, 3.0])
lambda_ = 1e-3
# Regularized diagonal:
D_reg = np.diag([d + lambda_ for d in D.diagonal()])
# Now invert the regularized diagonal
D_inv_reg = np.diag([1.0/(d + lambda_) for d in D.diagonal()])
print("Regularized Inverse:\n", D_inv_reg)
This kind of approach is particularly common in algorithms that involve inverting covariance matrices to avoid near-singularities.
Can a non-square diagonal matrix have an inverse?
No. A rectangular matrix (even if its off-diagonal elements are all zero) does not possess an inverse in the standard sense. The concept of an inverse specifically applies to square matrices. For rectangular matrices, one can consider pseudoinverse methods (like the Moore-Penrose inverse), but that is a different concept altogether.
If some diagonal entries are zero, is there an alternative to a direct inverse?
When a diagonal matrix has zero entries, it is singular in the usual sense, meaning it does not have a classical inverse. However, one may use a pseudoinverse. For a diagonal matrix with zero entries, the Moore-Penrose pseudoinverse can be formed by taking the reciprocal of all nonzero diagonal entries and keeping zeros in the places corresponding to zero diagonal entries. The pseudoinverse still allows certain linear algebra operations but does not function as a full inverse in the conventional sense.
Why do we use diagonal matrices in machine learning and deep learning?
Diagonal matrices often appear in:
Covariance matrices with certain simplifications (e.g., assuming independence among features).
Preconditioning, where a diagonal matrix is used to scale gradient components differently.
Regularization contexts, where diagonal matrices might represent simple or approximate transformations.
These uses exploit the efficiency of diagonal matrix operations, which are much faster than operations with full matrices.
What happens if a small floating-point rounding error makes a diagonal element exactly zero?
Floating-point errors can cause an element intended to be extremely small to become zero. This is dangerous because even a single zero diagonal entry means the overall matrix is not invertible. A practical workaround is to set a minimum threshold (known as epsilon or machine epsilon) such that any diagonal element below this threshold is automatically raised to that threshold before inversion. This ensures that the matrix remains invertible for computational purposes and mitigates the blow-up from dividing by a near-zero number.