
ML Interview Q Series: Using AUC-ROC, how would you evaluate, verify, compare three binary classifiers and choose the best?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
One standard way to assess the performance of a binary classifier that outputs probability scores (or confidence scores) is to use the Receiver Operating Characteristic (ROC) curve and compute the Area Under this Curve (AUC). Below is a detailed explanation of how to construct and interpret the AUC-ROC metric, followed by insights on evaluating the three models.
ROC Curve Construction
An ROC curve is a plot of the True Positive Rate (TPR) against the False Positive Rate (FPR) at various threshold settings. If we have a set of true labels and a set of predicted probabilities for class 1, we vary a threshold t from 0 to 1 and compute:
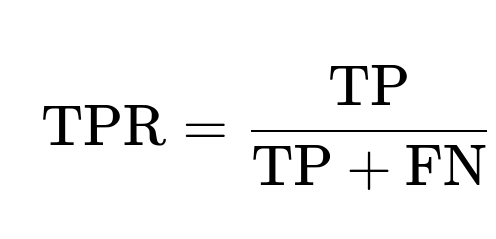
Here, TP is the number of true positives, FN is the number of false negatives. TPR is often called recall or sensitivity. It shows how many of the actual positive samples (class 1) were identified correctly by the classifier.

Here, FP is the number of false positives, TN is the number of true negatives. FPR indicates how many of the actual negative samples (class 0) were incorrectly classified as positive.
Each time we choose a different threshold t, we end up with a different pair of TPR and FPR. Plotting TPR (y-axis) versus FPR (x-axis) for all possible thresholds gives us the ROC curve.
Definition of Area Under the Curve (AUC)
Once we have the ROC curve, we measure the area under it. The AUC is a value between 0 and 1, with 1 being a perfect classifier that separates classes with zero error. Formally, the AUC can be expressed as:

This integral indicates that we are summing up all the TPR values over small increments of FPR from 0 to 1. In practice, we often compute the AUC using numerical approximation such as the trapezoidal rule, rather than doing this integral directly.
Verifying the Metric
To verify that the AUC-ROC metric is correctly implemented, you can perform the following steps:
Create a synthetic dataset where you know the ground truth probabilities or have perfect knowledge of separable classes.
Compute the predicted probabilities from a simple classifier (for example, a trivial classifier that always predicts the same probability, or a perfect classifier).
Manually calculate TPR and FPR at the key thresholds (0 and 1, and possibly midpoints) to see if your ROC curve is as expected.
Compare the manually computed AUC with the programmatic approach (such as scikit-learn) to ensure they align.
Applying to the Three Models
When you apply your AUC-ROC metric to three different models, you might see results such as:
Model A: AUC = 0.85
Model B: AUC = 0.72
Model C: AUC = 0.50
A higher AUC typically indicates better performance in terms of ranking positive instances ahead of negative ones. An AUC of 0.50 is equivalent to random guessing, whereas values closer to 1.0 suggest stronger discriminative power.
If your three models produce these AUC scores, you would likely conclude that Model A performs best overall (since 0.85 is higher than 0.72 and 0.50). However, you should also consider other aspects such as:
Model calibration (whether predicted probabilities reflect true likelihoods).
Precision-Recall curves if the dataset is imbalanced.
Interpretability and computational cost of each model.
Which Model to Choose
If all three models appear robust in terms of overfitting, hyperparameter tuning, and data assumptions, you would generally pick the model with the highest AUC—in this example, Model A. This choice is under the assumption that you are optimizing for the metric that best aligns with your business requirements (for instance, if you need high recall on the positive class, you might also consider trade-offs in the confusion matrix).
Example Code Snippet (Python)
Below is a simple example of how one can compute ROC curves and AUC in Python using scikit-learn:
import numpy as np
from sklearn.metrics import roc_curve, auc
# Example: Assume y_true are binary labels, and y_scores are predicted probabilities.
y_true = np.array([0, 0, 1, 1, 1, 0])
y_scores = np.array([0.1, 0.4, 0.35, 0.8, 0.9, 0.2])
fpr, tpr, thresholds = roc_curve(y_true, y_scores)
auc_value = auc(fpr, tpr)
print("FPR:", fpr)
print("TPR:", tpr)
print("Thresholds:", thresholds)
print("Computed AUC:", auc_value)
Possible Follow-Up Questions
How would you handle an imbalanced dataset when using AUC?
AUC alone can sometimes be misleading if the dataset is heavily imbalanced. In such scenarios, you might want to look at metrics like Precision-Recall AUC. A high AUC might not necessarily indicate high precision for the minority class, so exploring more class-specific metrics is often crucial. Additionally, using techniques such as oversampling, undersampling, or adjusting class weights can help address imbalanced data.
Can a model with a high AUC still perform poorly in practice?
Yes. A model might rank predictions reasonably well, resulting in a high AUC, yet its predicted probabilities could be poorly calibrated. For instance, it might predict a high probability for nearly all instances, ranking positive examples above negative ones but leading to incorrect estimations of the actual probability. In real-world settings, decisions often rely on accurate probability estimates, so a high AUC model might still need further calibration (e.g., using Platt scaling or isotonic regression).
Is there a confidence interval for the AUC?
Yes. The AUC is typically estimated from a finite sample, so it is subject to sampling variability. Several methods (such as bootstrapping) allow you to compute a confidence interval for the AUC. In critical applications, you might want to confirm that your observed AUC advantage over another model is statistically significant.
How do you decide on the optimal threshold for deploying the model?
The ROC curve and the AUC do not directly specify a single best threshold. Instead, you usually pick a threshold that best meets your goals. For example:
If you need to minimize false negatives, you might pick a threshold that gives you high TPR.
If avoiding false positives is crucial, you might pick a threshold that yields a lower FPR even if the TPR drops.
Techniques like the Youden’s J statistic (maximizing TPR + TNR - 1) or cost-based analysis can help determine an appropriate operating threshold.
Could you compare AUC with other metrics like Accuracy or Log Loss?
AUC focuses on ranking positives higher than negatives and is threshold-independent. Accuracy depends on a fixed threshold and might give a misleading picture if classes are imbalanced. Log Loss evaluates the correctness of predicted probabilities in a continuous manner, punishing confident but incorrect predictions more heavily. Which metric to prioritize depends on your objectives. In practice, multiple metrics are often examined together to get a well-rounded view of model performance.
These considerations help ensure that simply choosing a model based on a single statistic like AUC is not done in isolation. However, as a broad measure of a model’s ability to rank positives and negatives correctly, AUC-ROC remains one of the most widely used metrics in binary classification tasks.
Below are additional follow-up questions
What if multiple models have the same AUC score? How do you choose among them?
When several models yield nearly identical AUC values, you need additional criteria to break the tie:
Evaluate Calibration: Check if the probability estimates match the true likelihood of the positive class. You can use calibration curves or reliability diagrams to see if predicted probabilities reflect the real frequencies of outcomes.
Look at Other Metrics: You might examine metrics such as Log Loss, Precision-Recall AUC, or F1-score. Even if the AUC is the same, these alternate views might reveal differences in performance under certain operating conditions.
Complexity and Interpretability: If two models have the same AUC, you could prefer the simpler or more interpretable one, which tends to be easier to maintain and explain.
Statistical Significance: Use techniques such as bootstrapping to see if the difference in AUC is genuinely negligible or if the tie is due to variance in smaller datasets.
Potential Pitfall:
Over-reliance on AUC can mask subtle but important differences. For example, if one model’s performance is great at high-recall regimes and the other model’s performance is only good at moderate thresholds, they might end up with similar AUCs but differ significantly in real-world impact.
Is AUC still reliable for very small datasets?
Small datasets can make any performance metric less robust due to high variance in the estimates. Specifically for AUC:
High Variance in TPR/FPR Estimates: With fewer data points, a single misclassification has a larger impact on TPR and FPR, causing the ROC curve to fluctuate significantly.
Confidence Intervals Become Wider: You might observe wide confidence intervals for AUC, making it difficult to trust the exact numeric value.
Cross-Validation: To mitigate the small sample size, repeated cross-validation can help provide a more stable average AUC, though you still must be cautious about overfitting.
Potential Pitfall:
Overfitting can happen quickly when tuning models on a small dataset. An inflated AUC might not generalize well. Careful validation and possibly collecting more data or using transfer learning can help.
Does the ROC curve lose significance if probabilities are poorly ranked?
Yes. If the model’s predicted probabilities do not properly rank positive samples higher than negative samples, the ROC curve might look suboptimal (low TPR for many thresholds or steep increases in FPR).
Ranking Quality: The AUC is fundamentally about how well the model orders positive instances relative to negative instances. Poor ranking translates to a low AUC.
Misleading Probability Outputs: Even if your model produces probabilities, they might not reflect the actual ordering if it is poorly trained or if the data is not representative.
Possible Remediation: Techniques like recalibration, better model architectures, or additional data collection might be required if the ranking is severely misaligned.
Potential Pitfall:
In high-dimensional or noisy environments, even a well-designed model can struggle to learn an informative ranking. You might see an unexpectedly low AUC that doesn’t improve with hyperparameter tuning alone, indicating a need for more feature engineering or data cleaning.
How does the shape of the ROC curve itself help you diagnose model behavior?
Beyond the AUC number, the ROC curve’s shape can provide deeper insights:
Sharp Initial Rise: If the curve quickly reaches a high TPR at a low FPR, it suggests the model can confidently identify a proportion of true positives with few false positives. This is typically desirable.
Diagonal Sections: Parts of the curve that run parallel to the 45° line imply that increasing TPR requires adding a similar or higher proportion of false positives, indicating less discriminative power in those threshold ranges.
Long Flat Regions: If the curve is flat in certain places, it suggests that changes in threshold do not significantly alter TPR or FPR, possibly indicating insufficient separation between classes for that range.
Potential Pitfall:
Relying only on a single summary metric like AUC can hide these nuances. Two models might have identical AUC but very different curves—one might do well in the very low FPR region, while the other requires a higher FPR for similar TPR gains.
How do cost-sensitive considerations affect the interpretation of AUC?
The standard ROC curve and AUC assume that false positives and false negatives carry equal cost. In many real-world problems, that assumption doesn’t hold:
Different Misclassification Costs: For example, in medical diagnosis, missing a positive case (false negative) is usually more costly than incorrectly flagging a negative (false positive).
Weighted ROC Curves: Some variations of ROC analysis incorporate different costs by placing higher penalty on certain types of misclassification. Alternatively, you might shift the operating threshold accordingly.
Alternate Metrics: Cost-sensitive metrics (like Weighted Accuracy or custom cost functions) can be more relevant if the default AUC does not reflect the actual penalty distribution.
Potential Pitfall:
Blindly maximizing AUC could lead to suboptimal decisions if false negatives are extremely costly, because a model that ranks well overall might still produce too many false negatives under certain threshold selections.
What if you care only about a specific region of the ROC curve?
In certain applications, you might only be interested in very low FPR or very high TPR domains:
Partial AUC: Sometimes, you restrict the integration to a specific region of FPR (e.g., FPR from 0 to 0.1). This partial AUC quantifies performance in the range that matters the most to you.
Focused Metrics: You might prefer metrics like Precision at a certain recall level, or TPR at a small FPR. These targeted evaluations capture the performance that aligns with your practical needs.
Oversight: A good overall AUC does not guarantee top-tier performance in your region of interest.
Potential Pitfall:
If you only optimize for a small region, you might fail to see broader performance trade-offs. A model that is strong for extremely low FPR might degrade quickly if conditions change or the threshold drifts slightly.
Can you use AUC-ROC for multi-class classification problems?
The ROC curve is inherently a binary classification concept. For multi-class scenarios:
One-vs-Rest Extension: You can plot and compute the AUC for each class considered as “positive” vs. all other classes. Then you can average these AUCs across classes (macro-average or weighted-average by class frequencies).
One-vs-One Approach: Alternatively, compute AUC pairwise among classes and then average.
Complexities: Interpretation becomes less straightforward because you get multiple curves, and combining them into a single metric might lose per-class performance details.
Potential Pitfall:
If the data is skewed among multiple classes, the aggregated AUC may obscure issues in minority classes. You might need to use confusion matrices or other class-specific metrics in parallel.
How do you validate whether the AUC differences are statistically significant?
When comparing multiple models:
Pairwise Comparisons: Compute the confidence intervals or perform statistical tests (like DeLong’s test) to see if the difference in AUC is significant.
Bootstrap Methods: Re-sample the data many times to estimate a distribution for the AUC difference, then calculate p-values or confidence intervals.
Practical vs. Statistical Significance: Even if a difference is statistically significant, it might be negligible for real-world application. Always interpret results in context.
Potential Pitfall:
Relying on p-values alone might push you to over-interpret small differences that are not meaningful in practical scenarios. It’s crucial to tie statistical findings back to domain-specific costs and benefits.
In online learning or streaming data, how do you maintain an up-to-date estimate of AUC?
For datasets that arrive in a streaming fashion:
Incremental Computation: Storing all data and recalculating the AUC from scratch can be expensive. Instead, some algorithms approximate the ROC curve incrementally as more data arrives.
Sliding Window: You may keep a moving window of recent data and recalculate AUC to reflect current performance. This approach helps adapt to concept drift (i.e., when the relationship between features and labels changes over time).
Challenges: Maintaining large buffers for streaming data, ensuring balanced representation over time, and managing concept drift all require careful system design.
Potential Pitfall:
If concept drift is significant, the previously accumulated data might mislead your current AUC estimate. You may need adaptive forgetting mechanisms or drift detection methods to ensure that the metric reflects recent patterns accurately.
Does AUC help identify overfitting?
AUC by itself does not guarantee that a model isn’t overfitting:
Train vs. Validation AUC: Compare the AUC computed on training data to that on a validation or test set. If the train AUC is significantly higher, overfitting is likely.
Cross-Validation Stability: Evaluate how consistent the AUC is across multiple folds. Large variance in AUC across folds can indicate overfitting.
Learning Curves: Plot AUC against the size of the training set to see if more data improves or stabilizes performance.
Potential Pitfall:
A high AUC on test data might still be a random fluke if the test set is too small or not representative. Relying solely on AUC without investigating broader generalization metrics and data sampling strategies can lead to false confidence.