
ML Interview Q Series: What are some key limitations of Decision Trees, and how can they be effectively addressed?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Decision Trees are straightforward to interpret, handle both categorical and numerical data well, and do not require extensive data preprocessing. Despite these advantages, they present several notable drawbacks. The primary issues include overfitting, high variance, sensitivity to minor fluctuations in the training set, and challenges in capturing complex decision boundaries without growing overly large structures.
Overfitting and High Variance
Decision Trees are notorious for growing very deep and segmenting the training data into increasingly small subsets. As a result, they may create overly complex models that perform poorly on unseen data. When a tree is fully expanded, it tends to memorize the training dataset, reflecting high variance. This situation can lead to weak generalization capabilities.
Sensitivity to Small Perturbations in Data
A minor alteration in the training set can significantly shift the structure of a Decision Tree. This happens because each split depends on the local optimum choice of a particular feature and threshold. Such instability can reduce model reliability, especially for noisy or small datasets.
Bias Toward Dominant Features
Decision Trees typically split based on measures like Gini impurity or entropy to quantify the quality of a split on a feature. If one feature with many distinct values dominates the dataset, the tree may repeatedly pick that feature for splitting, potentially ignoring other relevant attributes.
One of the common splitting criteria for classification is the Gini impurity measure:
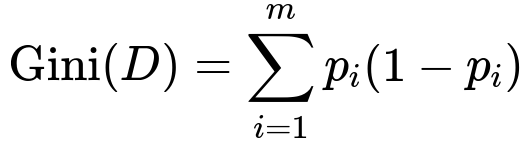
where p_i is the fraction of samples belonging to class i in dataset D, and m is the number of classes. If one class dominates, the splits rapidly reduce impurity, causing the tree to favor that feature.
Pruning to Prevent Overgrowth
Tree pruning (either pre-pruning or post-pruning) helps avoid excessively deep trees. Pre-pruning stops the tree growth prematurely, while post-pruning starts with a maximal tree and prunes back subtrees that do not improve validation accuracy.
Using Ensembles to Reduce Variance
Ensemble techniques like bagging (in particular Random Forests) and boosting (Gradient Boosting) are powerful methods for mitigating high variance and improving performance:
Bagging: Involves creating multiple Decision Trees on bootstrap samples from the training set and averaging their predictions to lower variance.
Random Forest: A special case of bagging that introduces randomness in feature selection. This approach improves decorrelation among individual trees and further decreases variance.
Boosting: Sequentially refines weak learners by focusing on misclassified examples in each iteration. Gradient Boosting and AdaBoost are popular algorithms that produce highly robust models.
Hyperparameter Tuning
Decision Tree hyperparameters (like maximum depth, minimum samples per leaf, minimum impurity decrease) can curb the tree’s tendency to overfit by limiting growth. Optimal tuning typically requires cross-validation to find the best balance between tree complexity and generalization performance.
Handling Imbalanced Data
When classes are heavily imbalanced, the splits are driven by majority-class patterns, potentially ignoring minority classes. Techniques such as class weighting or oversampling can help address this issue. For example, you might adjust the class_weight parameter in many Decision Tree implementations or use synthetic minority oversampling (SMOTE) before training.
Handling Continuous or Missing Values
Decision Trees can naturally handle continuous data by choosing threshold-based splits. For missing values, some implementations can learn surrogate splits to handle incomplete data during prediction, although data preprocessing (such as imputation) is still a common strategy.
Below is a simple Python snippet illustrating Decision Tree training and pruning strategies:
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
# Load example dataset
data = load_iris()
X, y = data.data, data.target
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Decision Tree with some hyperparameter tuning
param_grid = {
'max_depth': [None, 5, 10],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 5]
}
clf = GridSearchCV(DecisionTreeClassifier(random_state=42), param_grid, cv=5)
clf.fit(X_train, y_train)
best_tree = clf.best_estimator_
y_pred = best_tree.predict(X_val)
print("Best hyperparameters:", clf.best_params_)
print("Validation accuracy:", accuracy_score(y_val, y_pred))
This example demonstrates how to set a search grid for different pruning-related hyperparameters (like max_depth and min_samples_leaf). By using cross-validation, you can discover an optimal combination that balances complexity and accuracy.
How Does Pruning Alleviate Overfitting?
Pruning discards less relevant splits and branches to restrict the size of the tree. Rather than letting the tree fully expand, it uses various criteria (like minimal gain in impurity reduction) to decide when to terminate or cut branches. This is effective in improving generalization since it prevents the tree from fitting random noise in the training data.
Why Do Ensemble Methods Improve Stability?
Ensemble methods combine multiple trees and average (or sum) their predictions. By training distinct learners on different portions of the dataset or with different subsets of features, you create uncorrelated (or less correlated) models. Averaging reduces variance, making predictions more reliable than any single tree would produce.
Could You Elaborate on Pre-pruning vs. Post-pruning?
Pre-pruning stops the tree-building process early if adding a split does not reduce impurity by a sufficient margin. This approach can be computationally less expensive but might occasionally halt tree growth prematurely. Post-pruning, on the other hand, grows a complete tree and then prunes it back, which can yield a more optimally sized tree at the cost of higher computational overhead.
What Happens When Features Have Many Unique Values?
If a feature has many unique values, the tree might repeatedly split on this feature, leading to shallow yet highly branched splits that are not necessarily useful. Using criteria like minimum_samples_leaf or min_impurity_decrease can force the model to look for more meaningful splits, balancing the distribution of samples across leaves.
How Do You Mitigate Decision Tree Instability?
Decision Tree instability arises due to small fluctuations in data that dramatically alter the resulting splits. Techniques to mitigate this include using robust cross-validation strategies to ensure splits are representative, employing bagging or boosting for more stable overall predictions, and carefully tuning pruning parameters to avoid highly specific splits that reflect noise.
When Should You Prefer Simpler Models Over Deep Trees?
A simpler model like a shallow tree or linear model might suffice when the dataset is small or if interpretability is crucial. Very deep trees can become too complex, hindering interpretability and sometimes providing no tangible benefit in predictive performance. Cross-validation can reveal whether deeper, more complex models genuinely improve accuracy enough to warrant reduced interpretability.
Could Overfitting Still Occur With Pruned Trees?
Even pruned trees can overfit if hyperparameters are not well chosen or if the dataset is extremely noisy. Pruning only mitigates the risk of overfitting; it does not eliminate it entirely. Ensemble-based approaches or stronger regularization mechanisms might still be needed for very complex tasks.
Final Thoughts on Decision Tree Drawbacks
Decision Trees are intuitive and powerful for many problems. However, they may overfit, show high variance, and be sensitive to minor data changes. By employing pruning, hyperparameter tuning, and ensemble methods, you can manage these drawbacks and produce stable, high-performing models suitable for various real-world applications.