
ML Interview Q Series: What are some key characteristics of the distance from a point to its centroid?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
The distance from any individual point to the centroid (also called the mean or center of mass in a Euclidean space) plays a critical role in a wide range of areas: clustering (k-means), statistics (variance analysis), and geometry (center of mass computations). The centroid of a set of n points x_1, x_2, ..., x_n (each x_i in R^d) is simply the average of those points. When distances are measured in the Euclidean sense, the centroid has some distinctive properties that give insight into many machine learning and data analysis methods.
Centroid Definition
A fundamental property of the centroid is that it is computed as the mean of all the points. If each x_i is a d-dimensional vector, the centroid x_bar is given by
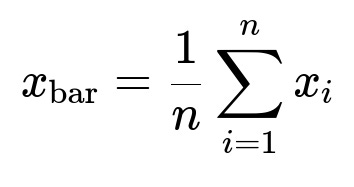
Here:
n is the number of points.
x_i is the i-th point in R^d.
x_bar is also known as the center of mass or mean vector.
Minimizes Sum of Squared Distances
One of the most important properties is that the centroid minimizes the total sum of squared Euclidean distances between each point and that centroid. Formally:
In other words, if you pick any other point c in the same space and sum up the squared distances from every x_i to c, that sum cannot be smaller than the sum you get when c = x_bar. This is exactly why k-means clustering re-computes cluster centroids using the mean of all points assigned to each cluster—because it minimizes the within-cluster sum of squared distances.
Geometric and Statistical View
From a statistical perspective, the centroid x_bar coincides with the sample mean of the points. As a result, the distance of each point to the centroid connects directly to concepts like variance. In fact, the variance in each dimension can be interpreted through how far individual points are from that dimension’s mean.
From a purely geometric perspective, if you imagine a collection of masses located at each of your points x_i, the centroid is the "balancing point" or center of mass. In physical problems, the sum of distances (or sum of squared distances) from that balancing point has minimal total moment compared to any other point.
Relation to Variance Decomposition
When you compute the distances of points to the centroid in a single-dimensional case, you can interpret the sum of squared distances as the total variance of the data. For higher dimensions, you often see an interpretation involving “sum of squared errors” to the mean. This leads to decomposition techniques such as the ANOVA decomposition in statistical analysis.
Computational Aspects
In practice, calculating the distance from each point to the centroid is straightforward with a vectorized approach. For instance, in Python with NumPy:
import numpy as np
# Suppose we have n points in a 2D space
points = np.array([
[1, 2],
[3, 4],
[5, 6]
])
# Compute the centroid
centroid = np.mean(points, axis=0)
# Compute the Euclidean distances from each point to the centroid
distances = np.linalg.norm(points - centroid, axis=1)
print("Centroid:", centroid)
print("Distances:", distances)
Each element of distances shows how far a point is from the centroid, providing a measure of how spread out the points are around their center.
Impact of Outliers
A known subtlety is that the centroid (mean) is sensitive to outliers. A single very large or extreme point can significantly shift the centroid and thus alter the distribution of distances. Alternative measures (like the median or geometric median) might be used if the goal is to minimize the sum of absolute distances or to be robust against outliers.
High-Dimensional Interpretations
In higher dimensions, the concept remains the same: the centroid is the vector formed by taking the arithmetic mean of each coordinate separately. The Euclidean distance in high-dimensional spaces is still the norm of (x_i - x_bar). However, distance metrics in high-dimensional spaces can behave in unintuitive ways: points can appear to be almost equidistant from each other when the dimension is very large (sometimes referred to as the “curse of dimensionality”). Still, the fundamental property that the centroid minimizes the sum of squared distances remains valid no matter the dimension.
How Does This Relate to k-Means Clustering?
In k-means clustering, each cluster’s centroid is recalculated as the mean of the points assigned to that cluster. The reason for using the centroid in this algorithm is directly tied to that minimization property of the sum of squared distances. This ensures that at every step, when you update the cluster centers, you are locally optimizing the within-cluster sum of squares.
Follow-up Questions
Could you explain why the centroid (mean) is more sensitive to outliers compared to other measures like the median?
When an outlier is present, the mean is pulled toward it because it is computed through a direct summation of all values divided by n. One single large value in any dimension has a direct (and sometimes large) impact on the mean. In contrast, the median depends on the middle value(s) in the sorted order of points in that dimension, so a single extreme outlier does not shift the median much, if at all.
What if we replace Euclidean distance with another metric?
If we use another distance metric such as the Manhattan distance (L1 norm), the point that minimizes the sum of absolute deviations is the median (sometimes referred to as geometric median in multiple dimensions, though the concept of a true geometric median can also extend to arbitrary norms). The centroid (mean) specifically minimizes squared Euclidean distances (L2 norm). Choosing a distance metric is context-dependent and depends on the distribution and nature of your data.
How does the centroid help in variance or sum-of-squares decomposition?
When you compute the total sum of squares (TSS) of a dataset, that quantity can be decomposed into the sum of squares within clusters (WSS) plus the sum of squares between clusters (BSS). The reason the centroid is so useful in this decomposition is that it is the reference point that minimizes TSS for the dataset as a whole. In clustering scenarios, each cluster’s internal sum of squares is minimized by referencing its centroid.
What happens in very high-dimensional spaces?
As the dimension grows, distances can become less informative because points can become “far” from each other in nearly all directions. Although the centroid remains the best minimizer for the sum of squared distances, clustering and distance-based methods can become more challenging to interpret and can suffer from the curse of dimensionality. Often, dimensionality reduction (PCA, autoencoders, etc.) is employed before clustering to mitigate these issues.
Can you discuss numerical stability concerns when computing the centroid for very large n?
If n is huge or the feature values are extremely large, summing them all might lead to floating-point overflow or accumulation of numerical errors. One practical workaround is to use a running mean calculation in a streaming manner, which updates the mean incrementally without requiring summation of extremely large intermediate values. Many scientific libraries handle this internally, but it can still be a concern in edge cases with very large or very precise data.
Why is the centroid concept central to k-means specifically, rather than the median?
k-means is fundamentally an algorithm that partitions data by minimizing the sum of squared distances within each cluster. Because the centroid (mean) is the unique point that achieves this minimization for squared Euclidean distances, it is the natural choice for cluster representation. If you were minimizing sum of absolute distances, you would choose the median or medoid instead, which leads to variations like k-medians or k-medoids clustering.
These considerations underscore the special status of the centroid in Euclidean geometry and statistics: it serves as an optimal reference point for squared distance measures, ties directly to fundamental concepts like variance, and forms the basis for many clustering algorithms and analytical methods in machine learning.