
ML Interview Q Series: What are the two principal categories of techniques for reducing dimensionality, and in what ways are they distinct?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Dimensionality reduction is an important process in machine learning and data analysis, primarily used to simplify models, mitigate overfitting, and deal with the curse of high dimensionality. The two fundamental approaches are typically referred to as feature selection and feature extraction.
Feature Selection
Feature selection focuses on selecting a subset of the most relevant original variables from the dataset without transforming them. The central idea is to remove redundant or irrelevant features, so the reduced dataset still maintains sufficient information about the outcome of interest. This process often involves domain knowledge or data-driven statistical methods to determine which features should remain. The advantage is interpretability because the selected features retain their original meaning, making it easier to trace how the final model depends on each chosen variable.
There are several types of feature selection methodologies:
• Filter-based methods rely on statistical measures (like correlation) between each feature and the target to rank and select features. • Wrapper-based methods evaluate subsets of features by training models and comparing their performance, often employing search strategies like forward stepwise, backward elimination, or genetic algorithms. • Embedded methods integrate feature selection directly within the model training process (such as L1 regularization or tree-based models that naturally weigh features by their splitting importance).
Feature Extraction
Feature extraction creates new, lower-dimensional representations of the data by projecting the original features into a new space. Unlike feature selection, the resulting components or features often lose direct interpretability as they become linear or non-linear combinations of the original variables. However, these newly derived features can be more effective at representing essential data structure, especially when the original variables have correlations or align with lower-dimensional manifolds.
Among all feature extraction methods, Principal Component Analysis (PCA) is a classical linear approach. It attempts to find orthogonal directions of maximum variance in the data. If we let X be our data matrix with dimensions (n samples x d features), PCA seeks a projection matrix W (with dimensions d x k) that captures the directions of highest variance. The transformed data matrix X_proj will then be (n x k). One way to express the projection in mathematical terms is shown below.
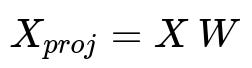
Here, X is the original data of dimension n x d. W is the matrix of the top k eigenvectors (each of dimension d x 1) of the covariance matrix of X, stacked side by side to form a d x k matrix. X_proj is the data transformed into k principal components. The parameter k is typically chosen to capture a large percentage of variance (for example, 95%), trading off reduced dimensionality against preserving information.
Beyond PCA, there are many other feature extraction approaches. Some are linear (like Linear Discriminant Analysis) while others are non-linear (like t-SNE, UMAP, or kernel PCA). They aim to find low-dimensional manifolds or embeddings that reflect the structure of data, often revealing more nuanced patterns than linear methods, though sometimes with increased complexity or reduced interpretability.
Potential Follow-Up Questions
How do you decide whether to use feature selection or feature extraction?
One must consider interpretability requirements, the nature of the data, and performance goals. If interpretability is vital or domain context heavily revolves around specific variables, feature selection can be ideal because it preserves the meaning of the selected variables. If the dataset has strong correlations, non-linear relationships, or complex manifold structures, feature extraction might capture essential patterns more efficiently.
What are the possible pitfalls when performing feature selection?
If a filter-based method is used without considering interactions among features, the process might eliminate features that appear unimportant in isolation but are actually crucial when combined with others. Wrapper-based methods can be computationally expensive, especially for high-dimensional datasets, because they might evaluate many subsets. Embedded methods can sometimes lead to overemphasis on certain features if the regularization or feature importance measure is not carefully tuned.
What is the intuition behind PCA?
PCA looks for directions in which the data has the largest variance. By focusing on directions that preserve the most variance, the data can be compressed with minimal loss of information. The top principal components correspond to the eigenvectors of the data’s covariance matrix associated with the largest eigenvalues. Each eigenvalue quantifies the variance captured by its corresponding component.
How do you handle large-scale datasets in feature extraction?
Algorithms like PCA might require computing and storing large covariance matrices. Techniques such as randomized PCA or incremental PCA can be used in these scenarios. Randomized PCA employs randomized algorithms to estimate the principal components efficiently. Incremental PCA processes data in mini-batches, reducing memory load and computational overhead.
What does non-linear dimensionality reduction offer that linear methods cannot?
Non-linear methods can better capture complex structures, such as curved manifolds. Linear methods like PCA are restricted to finding straight lines or hyperplanes of maximum variance. Techniques such as kernel PCA, t-SNE, and UMAP are designed to preserve local or global neighborhood structures that traditional PCA might overlook.
Example Using Feature Extraction (PCA) in Python
import numpy as np
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# Load example dataset
data = load_iris()
X = data.data
y = data.target
# Initialize PCA with 2 components
pca = PCA(n_components=2)
# Fit and transform the data
X_reduced = pca.fit_transform(X)
print("Original shape:", X.shape)
print("Reduced shape:", X_reduced.shape)
# Optionally, you can examine the explained variance ratio:
print("Explained variance ratio:", pca.explained_variance_ratio_)
This code demonstrates how to reduce dimensionality from 4 features to 2 principal components using PCA. It also shows how much of the total variance is captured by these new components. Such a technique can be vital for data visualization, noise reduction, or preprocessing prior to feeding data into other machine learning models.