
ML Interview Q Series: What criteria can be used to determine when to stop iterating in k-Means clustering?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
k-Means clustering is an iterative algorithm that alternates between assigning data points to their nearest centroids and then updating those centroids based on the newly formed clusters. There needs to be a clear condition for terminating this iterative process. Several criteria exist for stopping the algorithm, and these often depend on monitoring either the changes in cluster assignments or a convergence measure on the centroids or objective function.
Objective Function Convergence
k-Means seeks to minimize the total within-cluster variance. This can be expressed as the sum of squared distances from each data point to its assigned cluster centroid. One popular convergence criterion is to check whether this objective function no longer improves significantly with further iterations.
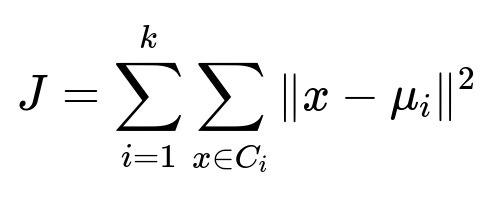
Here, i runs from 1 to k, representing each of the k clusters, x denotes any data point belonging to cluster C_i, and mu_i is the centroid of cluster i. Each iteration attempts to reduce J, and when the reduction in J from one iteration to the next falls below a certain threshold, we can decide the algorithm has converged.
Stability of Centroid Positions
Another common stopping condition involves measuring how much the centroid positions shift from one iteration to the next. After re-assigning points to clusters and recalculating each centroid, the new positions might be compared to the old positions using a distance metric. If these centroids move very little (for example, below a predefined tolerance), it indicates the algorithm is no longer making substantial progress.
Consistency in Cluster Assignments
Sometimes, monitoring the actual assignment of data points to clusters is more intuitive. If, after an iteration, the cluster membership of every data point does not change compared to the previous iteration, then the solution has converged. This criterion halts further computation once the assignment pattern is stable.
Maximum Number of Iterations
Even if the algorithm has not fully stabilized, in practice we often set a cap on the number of iterations as a safeguard against excessive runtime. This is useful when dealing with large datasets where small improvements after many iterations might not be worth the extra computational cost. It also helps in preventing the algorithm from entering a scenario where tiny fluctuations prevent it from strictly converging within a reasonable time frame.
Combination of Criteria
In real-world situations, many implementations of k-Means use a combination of these criteria. For example, the algorithm might terminate when both a maximum iteration limit is reached or when improvement in the objective function is below a small threshold, whichever happens first. This approach balances computational efficiency with the desire to find a stable clustering.
How is the Objective Function Computed at Each Step?
After each reassignment of points to centroids, the objective function J is recalculated by summing the squared distances of each data point to the centroid of the cluster to which it belongs. If this sum does not decrease significantly from the previous iteration, it often indicates k-Means has reached a near-optimal configuration.
Why Might We Need a Maximum Iteration Limit?
Although k-Means usually converges quickly, pathological cases can arise where the updates keep oscillating, especially if the data is peculiar or if there are points that hover between multiple centroids. Limiting the number of iterations ensures the algorithm eventually stops. In practice, if the assigned cluster memberships keep changing without settling, it might be more effective to run k-Means again with different initial centroids or to examine the dataset for outliers.
Could a Very Tight Threshold Cause Issues?
Yes, if the threshold for change in centroid positions or in the objective function is extremely tight, k-Means might do many unnecessary iterations seeking negligible improvements. In high-dimensional or very large datasets, this can be time-consuming. Thus, many practitioners pick a small but sensible threshold to balance computational cost and the quality of convergence.
How Do We Implement These Criteria in Code?
In many Python libraries like scikit-learn, the default stopping criterion checks if the centroids barely move or if an iteration limit is reached. An example of a custom approach might be:
import numpy as np
def kmeans_stop_criteria(old_centroids, new_centroids, iteration, max_iters, tolerance):
# Check if max iteration is reached
if iteration >= max_iters:
return True
# Calculate centroid movement
shift = sum(np.linalg.norm(old - new) for old, new in zip(old_centroids, new_centroids))
if shift < tolerance:
return True
return False
This code shows how you might check both an upper bound on the number of iterations and a tolerance-based stopping condition for centroid movement.
What If the Objective Function Increases at Some Iteration?
In standard k-Means, the objective function typically decreases or stays the same after each update. However, due to floating-point issues or certain unusual data arrangements, minor increases might appear. If this happens frequently, it might be worth examining the initialization or normalizing the data to ensure stable convergence. An occasional negligible increase can be ignored if the general trend is a decrease in the objective function.
Can We Combine Different Stopping Criteria for Better Reliability?
Yes, combining multiple conditions usually provides more robustness. For instance, checking both minimal shift in centroid positions and minimal improvement in J, along with an upper bound on the number of iterations, covers a broad range of convergence behaviors. This layered approach ensures that if one criterion fails to detect convergence (or fails to prevent endless looping), another one can step in to conclude the process.
What Happens After Convergence?
After k-Means converges (i.e., after it stops), the final centroids and cluster assignments are used for downstream tasks. These might include data exploration, dimensionality reduction, or as input for subsequent models. Sometimes multiple initializations with different random seeds are run, and the solution with the smallest objective function is selected for even better clustering performance.