
ML Interview Q Series: What does it indicate if we say an algorithm is characterized by O(n!) time complexity?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
When the complexity of an algorithm is described as O(n!), it means that as the input size n increases, the time required by the algorithm grows on the order of the factorial of n. In more concrete terms, factorial growth dominates every other polynomial and even exponential function for sufficiently large n. This complexity is extremely high and is generally associated with algorithms that enumerate or exhaustively check all permutations or combinations of a problem space.
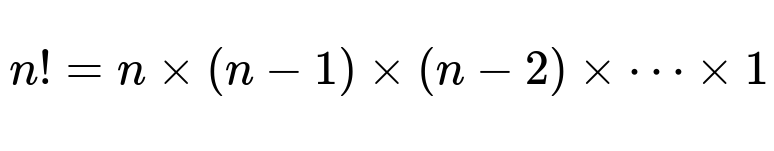
Here, n is the size of the input (often the number of items to permute). Factorial n is defined as the product of all positive integers from n down to 1. For instance, if n=5, then 5! = 5×4×3×2×1=120.
An O(n!) algorithm typically appears in problems such as generating all permutations of a list, brute-forcing certain combinatorial configurations, or performing exhaustive searches in problems like the Traveling Salesman Problem without any optimization or pruning. These algorithms are often considered intractable for large n because the number of operations quickly becomes enormous. Even for moderately sized n, running times can become prohibitively large.
Why O(n!) Occurs in Practice
This level of complexity is closely tied to tasks involving permutations. For example, suppose you need to generate every possible ordering of a list of items. If you have n items, there are exactly n! ways to arrange them. A naive algorithm that explicitly visits each possible arrangement will thus make a number of steps proportional to n!.
In optimization or decision problems where all permutations must be examined to guarantee finding a correct or optimal solution, the worst-case runtime can be factorial. However, modern methods often avoid brute force through heuristics, pruning strategies, or dynamic programming approaches to reduce the practical runtime.
Memory Usage Considerations
While O(n!) usually refers to time complexity, it can sometimes imply high space requirements as well, especially if the algorithm attempts to store all permutations for further processing. If the algorithm just processes each permutation on the fly, the space complexity may be more reasonable, but the time cost remains the dominant factor.
Example in Code
Below is a Python example of a naive function that generates all permutations of a list. Its runtime complexity is O(n!) because it enumerates all n! permutations.
def generate_permutations(lst):
if len(lst) <= 1:
return [lst]
# For each item in the list, generate permutations of the remaining and add the current item in front
permutations = []
for i in range(len(lst)):
current = lst[i]
remaining = lst[:i] + lst[i+1:]
for perm in generate_permutations(remaining):
permutations.append([current] + perm)
return permutations
# Example usage:
items = [1, 2, 3]
all_perms = generate_permutations(items)
print(all_perms) # Prints [[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]]
Even for a small input size like n=10, the total permutations become 3,628,800, making the algorithm expensive. For slightly larger n, it becomes computationally infeasible to generate every permutation.
Potential Optimizations and Pruning
In many scenarios, we do not truly need to explore all possible permutations. For example, if we only need to find the best solution under certain criteria (such as the shortest route in a graph), algorithms like branch-and-bound or dynamic programming (e.g., Held-Karp for Traveling Salesman) can prune large portions of the search space. Even then, these methods might still scale poorly, but they often perform much better than pure O(n!) solutions in practice.
Relationship to Exponential and Polynomial Time
A factorial function grows faster than any exponential function of the form a^n for constant a, and it dwarfs any polynomial p(n). This means that if an algorithm is truly O(n!), it becomes impractical very quickly as n increases. That is why most real-world applications resort to approximation algorithms, heuristics, or problem-specific optimizations to avoid factorial runtimes on bigger inputs.
Follow-up Questions
Could there be situations where O(n!) is acceptable?
In rare cases where n stays extremely small (for example, n=5 or n=6), an O(n!) approach may be acceptable, particularly when accuracy is paramount and we can afford the time. Another scenario is if we only need to do this factorial computation once, and n is small enough that the user can wait. Outside of these constrained conditions, factorial-time solutions are usually not scalable.
How can we handle O(n!) complexity in larger problems?
One common strategy is to seek approximate or heuristic algorithms that avoid enumerating all permutations. Methods like genetic algorithms, simulated annealing, branch-and-bound pruning, and other optimization techniques can reduce runtime drastically. Sometimes, it is also about reframing the problem to circumvent the need for enumerating every permutation.
Are there any typical pitfalls when dealing with factorial-time algorithms?
A frequent pitfall is misunderstanding the jump from n=10 to n=11. While 10! is already over three million, 11! is over 39 million, which is a more than ten-fold increase. Another pitfall is forgetting that additional overhead (like copying arrays) can further multiply the time cost beyond n! itself.
Is there a difference between O(n!) and, say, O((n/2)!) or O(n^n)?
All these notations suggest extremely large growth as n increases, but factorial typically becomes unmanageable at a comparatively lower n than n^n. Nonetheless, once the complexity reaches factorial or super-exponential (like n^n), the problem size you can feasibly handle remains very limited, and the difference often becomes academic for real-world problems.
Can we apply space-time tradeoffs to mitigate O(n!)?
Space-time tradeoffs usually help when we can store intermediate results. However, in factorial-time problems that explore permutations, memoization or caching might not reduce the overall complexity if you truly must visit each unique arrangement. Pruning or problem-specific heuristics tend to be more effective than standard memoization in such scenarios.
Below are additional follow-up questions
Are partial permutations or subsets a way to reduce factorial complexity?
Partial permutations or subsets can reduce the total number of arrangements that need to be explored. Instead of considering every permutation of n items, you might look at a subset of size k (with k much smaller than n) or generate permutations only up to a certain point and apply heuristics or pruning to stop early. The factorial complexity then applies to k rather than n, and if k is significantly smaller, the runtime becomes more tractable.
A subtle pitfall emerges if k eventually grows to approach n. In that scenario, you might still face close to n! permutations, undoing any benefit. Another challenge is deciding which subset or partial permutation to explore. If you choose subsets randomly or without a good heuristic, you could miss critical permutations that affect the final solution. So, while partial permutations are a valid approach, care must be taken to ensure the subset selection still captures the problem’s essence or yields a sufficiently accurate solution.
Are there real-world algorithms that degrade to O(n!) in worst-case scenarios but run faster in practice?
Many backtracking or constraint-satisfaction algorithms (like certain puzzle solvers or branch-and-bound methods) have a worst-case time that can blow up to factorial levels if every permutation of choices must be explored. However, these algorithms typically employ pruning or heuristics in practice, which drastically reduces the search space for most inputs.
A significant pitfall is the “pessimistic scenario,” where the data or constraints align in a way that offers minimal pruning opportunities. In such cases, an algorithm can degrade to its worst-case O(n!) performance. Real-world systems can sometimes be designed to avoid or detect these pathological cases, but if that’s not feasible, the risk remains that an unlucky input might cause extreme runtimes.
How does parallelization or distributed computing help in handling O(n!) tasks?
Parallelization can sometimes reduce the runtime in cases where you can split the set of permutations among multiple processors or machines. Each node can handle a smaller batch of permutations, potentially cutting down the wall-clock time. This approach is straightforward in tasks that are embarrassingly parallel, where each permutation is independently evaluated.
A subtle pitfall arises from coordination overhead. Managing communication and combining results can introduce extra time complexities, and if n is large, the factorial growth can outpace the benefit of adding new processors beyond a certain point. Another complication is that if you need to share partial results or prune effectively across nodes, the synchronization or message-passing can negate the gains of parallel processing. Therefore, while distributed computing helps in theory, in practice you might still struggle for large n.
Can randomization help mitigate factorial complexity in certain practical scenarios?
Randomized approaches can mitigate factorial complexity by sampling a fraction of all permutations rather than enumerating them exhaustively. Monte Carlo methods, for example, pick random permutations to estimate a solution. This can offer a quick approximation when enumerating the entire factorial space is impossible. You often apply randomization to complex optimization tasks, such as approximate solutions in scheduling or combinatorial optimization.
A tricky pitfall arises if the underlying space is uneven or if important permutations are very rare. Random sampling might miss crucial configurations entirely. Another subtlety is balancing the number of samples taken. Too few samples might yield poor approximations, while too many approach the full factorial enumeration. Careful design of randomness strategies and stopping criteria can address these concerns.
Could approximate or heuristic-based dynamic programming reduce the effective complexity from factorial to something more feasible?
Dynamic programming approaches can sometimes cut down factorial complexity if there is overlapping substructure or if you can systematically reuse intermediate solutions. For instance, in problems like the Traveling Salesman Problem, a naive brute force has factorial complexity, but a dynamic programming approach (Held-Karp) reduces it to O(n^2 * 2^n). While 2^n still grows quickly, it is usually far smaller than n! for large n.
A subtle pitfall here is that even a seemingly big reduction from n! to 2^n might still be too large for very big n. Another challenge is ensuring your problem indeed has subproblems that can be combined or reused effectively. If the problem’s structure does not lend itself to dynamic programming (i.e., there’s no overlapping substructure), a DP approach may not reduce the complexity. Additionally, approximate DP might rely on heuristics for cutting corners in state-space exploration, which can compromise accuracy if not done carefully.
What guidelines would you follow to decide if a factorial-time approach is ever appropriate in production?
One key factor is the maximum possible input size. If n never exceeds a small number, a factorial-time approach might be acceptable and simpler to implement than more complex alternatives. You might also accept the factorial approach if exact correctness is critical and domain constraints keep n small. Another reason might be that a single run of the problem can justify a high runtime if the payoff is large enough, and it’s performed infrequently.
A subtle edge case is the unpredictable nature of input growth. Even if you plan for small n, business requirements can shift, and the problem might need to scale to bigger sizes. If that happens, your factorial algorithm quickly becomes unmanageable. Another issue is user experience or real-time constraints that demand answers within strict time limits. In those scenarios, adopting a factorial solution can be a major liability. Always consider potential changes in the problem domain, future input sizes, and whether approximations or heuristic solutions are viable alternatives.