
ML Interview Q Series: What influence does the chosen batch size have on SGD's convergence properties, and what fundamentally drives this effect?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
One of the most important aspects of Stochastic Gradient Descent (SGD) is how the batch size affects both the speed and the quality of the convergence. When you use a single large batch, you are approximating the true gradient over the entire batch more accurately but you perform fewer update steps for a fixed epoch. Conversely, when the batch size is very small (e.g., batch size = 1 for pure SGD), you update more frequently but each gradient estimate is much noisier.
A key concept behind this phenomenon is how the variance of the gradient estimate changes with batch size. The smaller your batch, the more noise there is in the gradient estimate, which can influence how smoothly or chaotically the parameters move during optimization.
Effect of Batch Size on Variance of Gradient Estimate
When the batch size is m, the variance of the mini-batch gradient estimate is proportional to 1/m (assuming the underlying per-sample gradient variance is sigma^2). In more formal terms:
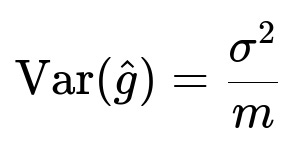
Here, Var(\hat{g}) is the variance of the gradient estimate for a single mini-batch. The parameter sigma^2 is the inherent variance of the sample-level gradients, and m denotes the batch size. As m increases, the variance of the mini-batch gradient decreases, leading to more stable updates but fewer total updates per epoch.
Why It Matters for Convergence
When the gradient variance is very high, parameter updates are more stochastic, allowing the optimizer to bounce around and possibly escape sharp local minima. However, that same stochasticity can also make the learning process less stable and potentially slower to converge to a minimum, since you might need smaller learning rates to maintain stability. A larger batch, with lower variance in the gradient estimate, leads to more stable convergence steps but might reduce the ability to jump out of certain basins and local minima. It can also mean fewer parameter updates if you process the same dataset with fewer, larger batches.
In practical terms, smaller batches can converge in fewer epochs because you take more gradient steps per epoch, but each step is noisier. Larger batches take fewer gradient steps but with less noise in each step. Depending on the learning rate schedule and the model’s structure, you might see faster or slower wall-clock time performance for a particular batch size, and the final generalization can also vary based on the interaction between batch size, learning rate, and the inherent noise in SGD.
Practical Balancing Factors
When deciding on the batch size, engineers often consider:
Hardware constraints: Larger batches are more memory-intensive, while smaller batches make more frequent updates but do not fully leverage modern parallel hardware efficiently.
Time to convergence: Small batches can be computationally slower if each update does not efficiently utilize GPUs/TPUs. Very large batches might converge in fewer epochs but require sophisticated learning rate tuning (such as warm-up schedules).
Generalization behavior: Some reports suggest that moderate levels of stochasticity (i.e., small or medium batch sizes) can help the model generalize better because the noisy updates act like a regularizer.
Follow-up Questions
What if the batch size is extremely large—equal to the entire dataset?
When your batch size is as large as the entire dataset, you effectively perform full-batch gradient descent. This removes almost all noise in the gradient estimate, making updates very stable but also reducing your number of updates per epoch to exactly one. You often need a smaller learning rate to avoid large, destabilizing updates. Moreover, any implicit regularization benefits from noisy mini-batch gradients disappear.
What if the batch size is extremely small?
Using very small batch sizes (like batch size = 1) means each update is highly noisy. You can often get away with a slightly larger learning rate because stochastic variance helps you escape some minima. However, training can be slower in wall-clock time if you’re not exploiting hardware parallelism. Also, extremely noisy updates can require special heuristics (like momentum or adaptive optimizers) to keep the optimization process stable.
How does the batch size influence generalization?
Many practitioners report that models trained with slightly noisy gradients (medium or small batches) can generalize better. The noisy gradient updates can be viewed as a regularization mechanism. That said, this effect depends on the dataset, architecture, and overall hyperparameter setup. Some modern strategies (e.g., large batch training with carefully tuned adaptive optimizers and well-designed learning rate schedules) can still achieve good generalization, but it requires more intricate tuning.
How do you choose the batch size in practice?
In real-world applications, batch size is typically selected based on:
Memory constraints of the accelerator (GPU/TPU).
Efficiency: Larger batches can be more efficient on modern architectures, but only up to a point where the GPU/TPU is fully utilized.
Performance trade-offs: Experimentation with validation accuracy versus training iteration speed often guides the final choice. Many start with a moderate batch size (like 32, 64, or 128), then adjust based on GPU memory usage and model performance.
Does the batch size matter if using momentum or adaptive optimizers?
Even with momentum-based optimizers (like SGD with Momentum, Adam, RMSProp), batch size can still impact both stability and final results. Momentum and adaptive algorithms smooth out some variance, but they do not completely eliminate the stochastic noise from mini-batch estimates. Large-batch training under Adam can still face issues such as needing more tuning and risking convergence to flatter or sharper minima, depending on the situation.
Example Code Snippet for Specifying Batch Size
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# Sample data
X = torch.randn(1000, 10) # 1000 samples, 10 features
y = torch.randn(1000, 1)
# Create Dataset and DataLoader
dataset = TensorDataset(X, y)
batch_size = 32 # Adjust this to see how it affects training
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# Simple model
model = nn.Sequential(
nn.Linear(10, 50),
nn.ReLU(),
nn.Linear(50, 1)
)
# Loss and optimizer
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Training loop
for epoch in range(5):
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
preds = model(batch_X)
loss = criterion(preds, batch_y)
loss.backward()
optimizer.step()
In this snippet, changing batch_size directly impacts how frequently the optimizer performs parameter updates and how noisy each gradient step might be.
Overall, the batch size is a powerful hyperparameter that affects convergence speed, stability of updates, and even generalization. The right balance depends on a combination of theoretical considerations (gradient variance, learning rate) and practical constraints (hardware and time budget).
Below are additional follow-up questions
How does batch size interact with Batch Normalization, and can it negatively influence the layer statistics?
When you use Batch Normalization layers, the mean and variance are typically computed over each mini-batch. If your mini-batch is extremely small, the computed mean and variance can become very noisy, leading to unstable training and poor convergence. On the other hand, if your mini-batch is extremely large, the per-batch statistics might be very stable but could fail to capture sufficient variability across different sub-distributions of the data. This can make the model less robust if the underlying data distribution has significant variance.
A subtle pitfall occurs when models are moved to inference mode, where fixed running averages are used in place of per-batch statistics. If the batch size is so large that these running averages overfit to a narrow portion of the data, your model could underperform on real-world data whose distribution deviates from the training set’s overall distribution.
Does changing the batch size necessitate re-tuning the learning rate schedule?
In many practical cases, changing the batch size requires adjustments to the learning rate schedule. If you suddenly increase the batch size, the gradient estimates become more stable, and you can often increase the initial learning rate. However, without careful tuning, you might see either divergence (if the learning rate is too high for a large batch) or slow convergence (if the learning rate is too low).
A hidden pitfall is that even a well-chosen base learning rate might need a modified warm-up or decay schedule when scaling batch size. Overlooking these details can cause suboptimal convergence or prolonged training times. There’s also a risk of overshooting if you rely on naive scaling rules (for example, linearly scaling the learning rate with batch size) without conducting smaller validation experiments.
How can batch size choices influence the reproducibility of experiments?
Smaller batch sizes induce higher variance in gradient updates, which can lead to slightly different convergence paths even with the same random seed, especially across different hardware configurations or libraries. Conversely, very large batch sizes tend to reduce this randomness, but might expose numerical precision issues if floating-point accumulations become too large.
A real-world edge case arises if you switch hardware—say from a single GPU to multiple GPUs in parallel—and alter your effective batch size as you replicate or split computations. Small numerical discrepancies can arise from the order of floating-point summations, making experiments non-reproducible bit-by-bit, even if the random seeds are the same. Ensuring consistent data partitioning and accumulation strategies is essential to maintain as much reproducibility as possible.
What are the memory-related pitfalls when trying to increase batch size?
An obvious pitfall is running out of GPU/TPU memory. Large batches can cause out-of-memory errors or force you to reduce your model size (for instance, using fewer layers or smaller embeddings). Another more subtle pitfall is that as you approach the hardware limits, you might need specialized memory optimization techniques like gradient checkpointing. However, gradient checkpointing can slow down training because certain intermediate activations must be recomputed during backpropagation.
Additionally, if you push the batch size too large to maximize GPU utilization, you might neglect the trade-off that not all models benefit from giant batches. Sometimes, an optimal sweet spot exists between batch size and gradient variance that yields better generalization and faster wall-clock convergence.
How does the structure of your dataset affect batch size selection?
When data is highly varied—such as images from multiple classes in a computer vision problem—moderately sized batches can capture enough diversity to form a representative gradient without requiring huge sample counts. However, in scenarios where data is relatively homogeneous or includes many near-duplicate samples, increasing the batch size might not reduce gradient variance as much as you expect, since you are effectively sampling many similar points.
A tricky edge case appears in time-series or sequential data, where dependencies between consecutive samples can invalidate the assumption of independence within a mini-batch. If your dataset has strong temporal correlations, even a moderately sized batch might not represent the entire data distribution well. Overlooking this can degrade convergence or mislead your validation metrics if your train/validation splits are also impacted by these correlations.
What is the effect of partial batches at the end of an epoch?
Partial batches occur when the size of your dataset is not a multiple of your chosen batch size, so the final batch might be smaller. This can lead to slightly different gradient statistics for that last batch, potentially introducing small inconsistencies in training. Modern frameworks often handle partial batches gracefully, but they can still cause minor variance in the parameter updates compared to the other batches.
An edge case is if your partial batch is extremely small (say you have a dataset of 101 samples with a batch size of 64, leading to a last batch of 37). This might introduce enough additional noise in the gradient that, combined with certain learning rate scheduling steps (like step-based decay), changes training dynamics near epoch boundaries. If not carefully handled, it could cause spurious instability or overfitting to those last few samples.
How does batch size impact distributed training scenarios?
In distributed setups—such as training across multiple GPUs or across multiple machines—your effective batch size is often multiplied by the number of parallel workers. If each worker processes a mini-batch of size m, and there are N workers, your total batch size becomes N*m. This changes the gradient variance and can drastically shift the dynamics of training compared to a single-worker scenario.
A pitfall is not accounting for synchronization overhead or communication bottlenecks. Although you can aggregate larger gradients in parallel, you might also face latency issues if you frequently synchronize across workers. Another issue is that different workers might see different distributions of data, especially if you have not properly shuffled or balanced your dataset across nodes, causing skewed gradient estimates.
Why might large batch sizes lead to “sharp minima” vs “flat minima” debates?
Some researchers hypothesize that small-batch training inherently finds flatter minima, which could generalize better to new data. Larger batch sizes, with less noise, might settle into sharper minima, which can yield worse generalization. The notion is that the random fluctuations from small batches push the parameters to more robust “basins” in the loss landscape.
A subtlety here is that the definition of sharp vs flat minima can be context-dependent and may vary with scaling in parameter space or with the level of regularization. Even if large-batch training appears to converge to sharper regions, the practical difference in test error might be small when combined with advanced regularization techniques (e.g., weight decay, dropout) or well-tuned learning rate schedules.
Does the batch size impact how you perform hyperparameter searches?
Since batch size affects gradient variance and required learning rate scales, each batch size might demand a different set of hyperparameter values (learning rate, momentum coefficients, regularization strength). A direct pitfall is applying a “one-size-fits-all” approach—using, for example, the same hyperparameters that worked for a batch size of 32 when switching to 1024.
Another subtlety is that hyperparameter tuning might become more sensitive at larger batch sizes. You might find narrower optimal ranges for certain parameters. Automated tuning methods like Bayesian Optimization or population-based training can help, but they must be re-run if you significantly alter the batch size, which increases computational cost.
How would you troubleshoot if training stalls or diverges after changing batch size?
Monitor Loss and Gradient Norms: If you see the loss oscillating wildly, your learning rate might be too high for the new batch size. If the loss is not decreasing at all, the learning rate might be too low or you might not be utilizing enough gradient variance.
Check for NaNs or Inf in Gradients: Very large batch sizes can lead to large gradient accumulations, especially in deep architectures, which could overflow floating-point ranges.
Experiment with Gradient Accumulation: If you cannot fit a large batch into memory but still want to approximate a large-batch gradient, you can accumulate gradients over multiple smaller sub-batches before making an update.
Compare Different Logging Intervals: Sometimes, your metrics appear to stall just because you are not observing the small improvements that come with very large or very small batch updates. Checking logs at more granular intervals can reveal progress you might otherwise miss.
These troubleshooting steps help isolate whether the issue is hyperparameter misconfiguration, software/hardware limitations, or an inherent mismatch between your batch size and the model’s training dynamics.