
ML Interview Q Series: What is the significance of applying non-linear activation functions in neural networks, and why is it essential to use them instead of only linear transformations?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Neural networks rely on activation functions to introduce non-linearity into their computations. Without a non-linear component, a multi-layer neural network would simply collapse into a single linear transformation, regardless of how many layers it has. This would severely limit the model’s ability to capture complex relationships and patterns in the data.
When a neuron processes its inputs, it typically does so by computing a weighted sum and then applying a non-linear activation. The core representation of a simple neuron can be expressed as:
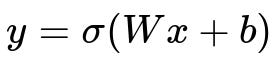
Here, W is the weight matrix that transforms the input x into a weighted sum, b is the bias term (a scalar or vector that shifts the weighted sum), and sigma(·) denotes the non-linear activation function. The output of sigma(·) then allows the network to approximate non-linear mappings between the input and output.
Non-linear activation functions enable neural networks to:
Capture complex input-output relationships. Allow deeper architectures to represent hierarchical features and abstractions. Serve as universal function approximators, making them powerful for tasks such as classification, regression, and representation learning.
Common activation functions include ReLU, sigmoid, tanh, softplus, and others. Each has its advantages and disadvantages. However, they all share the core property of introducing a non-linear aspect into the neuron’s output.
Why Purely Linear Transformations Are Insufficient
When you combine multiple linear layers without a non-linear activation, the entire composition is just another linear function. For instance, if a network applied a function f(x) = A x + b in the first layer and then a function g(x) = C x + d in the second layer, combining them would yield C(A x + b) + d, which can be re-expressed as (C A) x + (C b + d). In other words, multiple linear layers boil down to a single linear equation. This means that no matter how many layers are stacked, you cannot gain additional representational power if all activation steps remain linear.
Non-linear activations rectify this issue by introducing curves, thresholds, or other transformations to the data, enabling the network to model far more complicated relationships. In practice, certain activation functions like ReLU further help mitigate issues with vanishing gradients, thus empowering deeper architectures to be trained more reliably.
The Role of Non-Linearities in Universal Approximation
Deep neural networks are often called universal approximators. This attribute is fundamentally tied to the presence of non-linear activation functions. If the activation were linear, the universal approximation property would be lost, leaving the model incapable of representing complex functions. It is the combination of multiple layers of weights and biases, interleaved with non-linear transformations, that allows neural networks to approximate a wide array of functions as the depth and width of the network increase.
Potential Follow-Up Questions
How do non-linear activations help in practical scenarios, such as image classification or natural language processing?
Non-linear activation functions allow networks to learn abstract features. In image classification, early layers might learn edges or simple shapes, while deeper layers combine those shapes to learn complex structures. In natural language tasks, they help form meaningful embeddings and capture semantic or syntactic relationships. Without non-linearities, these deep layers would not provide increased representational power and would fail to capture the complex variations present in real-world signals.
Could we just use more layers of linear transformations to achieve the same effect?
No. Even with many linear layers, the composition remains linear. This provides no benefit in terms of complexity or expressiveness. Non-linearity breaks this limitation by transforming the linear sums in ways that allow the network to fit non-linear decision boundaries, making deeper architectures worthwhile and substantially increasing model capacity.
What would happen if we used a linear activation function in a deep network?
Using a linear activation would cause every additional layer to be redundant in terms of representational power. The network would effectively behave as a single-layer linear model, making it incapable of modeling non-linear patterns. This drastically reduces its potential to solve complex tasks like image recognition, language modeling, or speech recognition, where data patterns are far from being linearly separable.
How do we choose between different non-linear activation functions (e.g., sigmoid, tanh, ReLU, leaky ReLU)?
The choice of activation depends on various factors:
Data characteristics: Sigmoid or tanh might be suitable if outputs need to be constrained in certain intervals (like probabilities). However, sigmoid and tanh can saturate, which might cause gradients to vanish when inputs are very large or very small.
Computational efficiency: ReLU is simpler to compute compared to other non-linear functions, and it often trains faster. But ReLU can suffer from “dying ReLU” syndrome when neurons output zero constantly. Leaky ReLU or Parametric ReLU address this issue by allowing small non-zero gradients even in the negative input region.
Network depth: For very deep networks, specialized functions like ELU, SELU, or Swish can sometimes deliver better performance by helping control the vanishing or exploding gradient problem. However, ReLU remains a default choice in many practical scenarios.
How do non-linear activations relate to vanishing and exploding gradients?
Vanishing and exploding gradients occur when backpropagated error signals diminish or blow up as they propagate back through multiple layers. Activation functions like sigmoid or tanh can saturate for large magnitude inputs, resulting in near-zero gradients and causing vanishing gradients. Conversely, certain weights or activations can trigger large gradients (potentially leading to exploding gradients). Strategies such as careful weight initialization, batch normalization, and using ReLU variants help keep gradients within a manageable range.
What is the impact of non-linearities on interpretability?
Non-linear layers make models more complex, which can make them harder to interpret. However, the performance gain is generally considered worthwhile because interpretability techniques have evolved to cope with non-linear components. Methods like Layer-wise Relevance Propagation or Grad-CAM for convolutional networks can reveal which parts of the input most influenced a model’s prediction, even when non-linear activations are involved.
How might advanced activation functions like Swish or GELU improve performance?
Functions like Swish (x * sigmoid(x)) or Gaussian Error Linear Units (GELU) address some of the limitations of ReLU by enabling smoother transitions and sometimes better gradient flow. Empirical research has shown that these functions can improve training stability and final accuracy, especially in deep architectures like those used in large-scale language models or vision transformers. However, the gains can be architecture-dependent, and ReLU remains a strong baseline due to its simplicity and computational efficiency.
What should one consider when deciding on a specific non-linear activation for a large language model?
Typical considerations include:
Computational cost: Activation functions that are simple (like ReLU) are attractive for large-scale models where efficiency is critical.
Gradient behavior: Some functions are more stable during training, leading to fewer exploding or vanishing gradients.
Empirical results: Ultimately, experiment results often drive the choice of activation function. Researchers might try ReLU, GELU, Swish, or others and observe which yields the best performance while balancing complexity and training speed.
High-level architecture: Transformers, for instance, often use GELU or similar variants that have shown good results in language modeling tasks.
When implementing large-scale models, it’s practical to start with commonly used activations known to work well in that domain, then iterate based on validation performance and training stability.
Below are additional follow-up questions
How do activation functions with a saturation region (like sigmoid or tanh) affect gradient-based optimization, and what are possible strategies to mitigate any challenges?
When activation functions saturate for very large or very small input values, their gradients approach zero. This can slow down learning significantly because backpropagation relies on gradients to update model parameters. For example, a sigmoid function saturates near 0 and 1, causing the gradient to shrink. If inputs consistently fall in the saturation region, the neuron’s parameters barely update, making training more difficult.
One common strategy to mitigate this problem is careful weight initialization. Techniques such as Xavier or He initialization attempt to keep the variance of layer outputs at a suitable level, so that values do not quickly enter the saturated zone. Another approach is to use batch normalization or layer normalization, which centers and normalizes the activations to keep them in a range that avoids saturation. Some practitioners also switch to alternative activations (like ReLU variants) that do not saturate, except at negative inputs, thereby reducing the risk of vanishing gradients. However, even ReLU can lead to “dying ReLU” neurons if many inputs are negative, indicating that each activation function has its own pitfalls requiring tailored strategies, such as leaky ReLU, to keep gradients from becoming zero.
In practice, how do you address the “dead neuron” issue commonly associated with ReLU activation, and when does it become especially problematic?
A “dead” neuron in a ReLU-activated network outputs zero for most inputs, effectively ceasing to learn because the gradient through it is also zero. This often arises when large negative updates to weights force subsequent inputs into the negative side of ReLU. Once a neuron becomes consistently negative, it no longer contributes to the model.
One way to address this is to use leaky ReLU, parametric ReLU, or ELU, where a small slope or shift exists for negative inputs. This ensures that gradients remain non-zero, reducing the likelihood of neurons “dying.” Another strategy is to monitor the distribution of activations during training, possibly applying techniques such as batch normalization to maintain a well-balanced spread of values that do not consistently drift into the negative regime. Dead neurons can become especially problematic in deeper networks, where small weight changes can propagate through layers and drastically affect activation distributions, so paying attention to initialization and distribution shifts is crucial in large-scale or deep architectures.
What role does the activation function play when designing the output layer for a regression task, and how can an improper choice lead to inaccuracies or constraints on predictions?
In regression tasks, the output can be unbounded, negative, or take any real value. Using a non-linear activation that inherently restricts the range, such as a sigmoid, confines predictions to (0, 1), which may be inappropriate for unbounded targets. Even a tanh activation restricts the model’s output to (-1, 1). This limitation can cause difficulties in learning the correct mapping, especially when true target values lie outside these ranges.
As a result, many regression networks use a linear activation (i.e., no non-linear function in the last layer) to allow the output to cover the entire real number line. If the problem domain is restricted (for example, positive-only outputs) or has a bounded range, a carefully chosen activation (like ReLU for non-negative targets or a scaled sigmoid/tanh for specifically bounded intervals) can help. However, if a model’s output is unintentionally constrained, training may converge to suboptimal solutions, highlighting how critical it is to match the output activation function to the nature of the target variable.
In specialized scenarios, can linear activations be beneficial, and why might one intentionally remove non-linearities in a neural network?
Although non-linear activations are generally crucial for most deep learning tasks, there are select cases where linearity may be beneficial. For instance, in certain simplified models or when interpretability is a key requirement, researchers might prefer linear outputs or even end-to-end linear transformations to keep the model straightforward. Linear networks are also easier to analyze mathematically, which can be helpful in theoretical explorations or in constrained hardware environments where non-linear computations might be too costly.
A purely linear network might also be used for initial rapid prototyping or debugging: one can strip away non-linearities to confirm that the rest of the training pipeline (data loading, loss function, etc.) is functioning properly. By comparing a purely linear setup to a non-linear architecture, researchers often get insights into whether performance gains come from adding complexity or from other aspects of the network design.
What are the trade-offs between using polynomial expansions or kernel methods vs. using non-linear activation functions within the network?
Polynomial expansions or kernel methods can introduce non-linear relationships in models without explicit non-linear activation functions. They do so by mapping inputs into higher-dimensional spaces where linear separation might be more feasible. However, these expansions can lead to very large feature spaces, which can be computationally expensive and difficult to scale for large datasets.
Neural networks with non-linear activations incorporate the non-linear mapping directly through learned parameters, typically requiring fewer explicit feature transformations. This approach tends to be more flexible, as the network can learn which regions of the input space benefit most from non-linear transformations. In contrast, polynomial expansions apply a uniform transformation to every part of the input space, which can be either too coarse or too fine, depending on the application. Therefore, while kernel methods or polynomial features may work well for smaller-scale problems, neural networks with carefully designed activation functions often excel in large-scale tasks due to their learnable nature and more efficient representations.
Why do certain network architectures, such as those used for autoencoders or generative models, rely heavily on the choice and placement of non-linear activations?
Autoencoders and generative models (e.g., Variational Autoencoders, Generative Adversarial Networks) often use non-linear activations to compress and reconstruct high-dimensional data. The encoder in an autoencoder compresses input data into a latent representation, and the decoder reconstructs the original input from this latent code. Non-linear activations throughout this process allow for complex transformations that map high-dimensional inputs into a meaningful, typically lower-dimensional, latent space.
If the network were purely linear, the encoder-decoder combination would at best learn simple transformations akin to Principal Component Analysis (PCA). By applying non-linear activations, the model can capture intricate structures in data—leading to richer latent representations. Similarly, in GANs, the generator must produce realistic samples from random noise, a process heavily dependent on non-linearities to shape arbitrary distributions. Failure to choose appropriate activation functions can yield blurry reconstructions, mode collapse, or other training instabilities, highlighting how critical non-linear design choices are for generative tasks.
What happens when batch normalization or layer normalization is paired with various activation functions, and how does it influence model performance?
Batch normalization and layer normalization help stabilize the distributions of intermediate outputs, reducing internal covariate shift. When used with activation functions like ReLU, these normalization techniques can keep the activations in a healthier range, mitigating saturation or dead-neuron issues. For instance, after batch normalization, the input to ReLU is less likely to be extremely negative or positive, improving gradient flow.
However, certain activation functions have interactions with normalization that must be monitored. For example, if the chosen activation saturates at large values, but normalization shifts the input distribution, the layer might consistently operate near saturation unless parameters are tuned carefully. Additionally, some activation functions (like SELU) can be paired with specific normalization techniques designed for them (like AlphaDropout) to preserve certain self-normalizing properties. In practice, the synergy between a normalization scheme and an activation function can significantly affect training speed, stability, and final accuracy—suggesting careful experimentation is often needed.
How do different non-linearities alter the shape of the loss landscape, and what are potential pitfalls in initializing or optimizing these networks?
Non-linear activations can reshape gradients and output distributions layer by layer, affecting the local curvature of the loss surface. Functions with sharp saturation regions (like sigmoid) might create flat areas in the loss landscape, making optimization more challenging because gradients can vanish. ReLU-based networks typically have piecewise linear regions that can help gradient-based methods navigate more easily, although large negative updates might push values into dead neuron zones.
These shape differences mean that weight initialization schemes must be tailored to the chosen activation function. For instance, ReLU-based networks often need “He” initialization, while tanh networks might need Xavier initialization. An inappropriate initialization can exacerbate vanishing or exploding gradients, especially in very deep architectures. Another pitfall can be ignoring how non-linearities behave at different scales of inputs—leading to either saturated or mostly inactive neurons. Proper initialization, combined with either normalization or gradient-clipping techniques, can help keep the optimization trajectory on a productive path through the loss landscape.