
ML Interview Q Series: What is the significance of pruning a decision tree, and why is it generally necessary?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Pruning a decision tree is often essential to control overfitting. A raw decision tree grown to its full depth can begin to model random noise rather than the general underlying pattern. This happens because the tree keeps splitting until each leaf node may correspond to very few data points, capturing not just the main trends but also idiosyncrasies specific to the training set. By pruning the tree (removing branches or sub-trees that do not contribute to better predictive performance on unseen data), we enhance the model’s generalization ability and reduce variance.
Pruning strategies often rely on a trade-off between model complexity and accuracy on a validation set. A typical approach is to introduce a penalty term for the complexity of the tree. The simplest way to understand complexity is by looking at the total number of nodes or leaves. When we remove branches, we lose some of the model’s complexity and hence reduce overfitting. However, we risk increasing bias because we might be discarding some potentially informative splits. Consequently, there is a delicate balance between these two extremes.
One widely recognized technique is cost complexity pruning. It relies on finding a good compromise between the tree’s misclassification or impurity measure and its complexity. The core concept for cost complexity pruning is that each possible subtree has an associated cost, given by a function that combines the tree’s fit and a penalty for its size. The cost function can be expressed as follows.
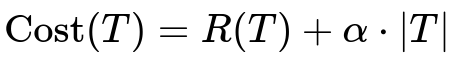
Here, T refers to a particular subtree, R(T) is the empirical risk (or impurity) of T on some evaluation set, |T| is the number of leaf nodes or total nodes in the subtree, and alpha (the complexity parameter) controls the penalty for adding more nodes. A smaller alpha places less emphasis on penalizing the tree complexity, which can lead to deeper trees, while a larger alpha favors simpler trees. The pruning algorithm searches for the subtree that minimizes this cost.
Pre-pruning is stopping the tree growth early based on certain criteria (such as a minimum number of samples per split), while post-pruning grows the tree first and then prunes it afterward. In both cases, the end goal is to find a tree structure that avoids capturing excessive noise.
When the model is pruned properly, it not only resists overfitting but is also simpler, easier to interpret, and typically has better predictive power on unseen data. In real-world scenarios, it is common to choose pruning hyperparameters (like minimum samples split, maximum depth, maximum leaf nodes, or cost complexity parameter alpha) based on cross-validation performance.
How Pre-pruning Differs From Post-pruning
Pre-pruning is also known as early stopping. In pre-pruning, we impose criteria while growing the tree. For instance, we can stop splitting a node if the number of samples in that node is below a certain threshold or if the improvement in splitting no longer exceeds a minimum threshold of impurity decrease. This helps to keep the tree small in the first place rather than having to cut it back afterward.
Post-pruning (or just pruning) involves growing the full tree and then removing sections (branches) that fail to yield a tangible improvement based on a validation set. Although post-pruning can be more computationally intensive, it often captures the structure of the training set more completely before systematically pruning away noisy splits. In practice, both techniques can lead to better generalization, but post-pruning with cost complexity tends to be more principled since it explicitly accounts for a trade-off between accuracy and complexity.
Implementation Details in Python
In Python’s scikit-learn library, cost complexity pruning can be applied via the ccp_alpha parameter in DecisionTreeClassifier or DecisionTreeRegressor. You can explore different alpha values and pick the one that yields the best cross-validation results. Here is a simplified code snippet illustrating this approach.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score
import numpy as np
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# We can retrieve potential alpha values through the pruning path
clf = DecisionTreeClassifier(random_state=42)
path = clf.cost_complexity_pruning_path(X_train, y_train)
alpha_values = path.ccp_alphas
# We can then run a simple grid search to pick the best alpha
parameters = {'ccp_alpha': alpha_values}
grid_search = GridSearchCV(DecisionTreeClassifier(random_state=42),
param_grid=parameters, cv=5)
grid_search.fit(X_train, y_train)
best_alpha = grid_search.best_params_['ccp_alpha']
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
print("Best alpha:", best_alpha)
print("Test Accuracy:", accuracy_score(y_test, y_pred))
In this example, we first derive the path of possible alpha values via cost_complexity_pruning_path. Then we run a grid search over those alpha values to find the one that yields the highest cross-validation score. This best alpha is used for final pruning.
Potential Pitfalls and Key Considerations
One major challenge is tuning alpha (or other relevant pruning parameters) carefully. If alpha is too low, the model may remain very large and can still overfit. If alpha is too high, the model might be underfit because too many branches are pruned away.
Another subtlety is the difference between various impurity measures. Pruning might behave slightly differently depending on whether we are using the Gini index, entropy, or mean squared error (for regression trees). The overall principles, however, remain consistent.
Pruning is important for both interpretability and generalization. Deep, unpruned trees can be unwieldy to interpret, especially in high dimensions, and are more prone to fitting noise. A good pruning strategy will keep the model’s predictive performance robust across different data sets and time periods.
How to Handle Very Large Data Sets
When the data set is huge, even constructing the full decision tree can be expensive, not to mention performing a detailed post-pruning procedure. In such scenarios, setting constraints like max_depth, min_samples_split, and min_samples_leaf upfront (pre-pruning) can help reduce computational costs. Sometimes, sampling or approximate methods are employed to make tree construction more efficient.
How Pruning Interacts With Ensemble Methods
When using ensemble methods like random forests or gradient boosting, each individual tree might be grown fully or partially. Random forests typically grow very deep trees without pruning but rely on the wisdom of the ensemble to avoid overfitting. Gradient boosting also tends to use shallow trees for each booster iteration. In these ensemble settings, pruning might not be as crucial at the level of individual trees. However, if you are using a single stand-alone decision tree, pruning is a primary way to ensure strong generalization.
Follow-up Questions
Can Pruning Increase Bias?
Yes, pruning can introduce additional bias. By removing branches, you might lose some features or splits that were helpful for capturing subtle patterns. The trade-off is that you typically decrease variance more significantly than you increase bias, leading to an overall improvement in expected predictive performance. This is why cross-validation is often used to strike an optimal balance.
Is There a Recommended Technique for Choosing a Pruning Strategy?
Most practitioners rely on data-driven methods such as cross-validation to select pruning hyperparameters. Cost complexity pruning is a common default approach since it offers a systematic way to trade off the tree’s error against its size. Alternatively, minimal depth constraints or other criteria can be chosen based on domain knowledge or computational constraints.
How Can We Check If a Tree Is Overfitting Before Pruning?
One approach is to monitor the performance on both training and validation sets (or through cross-validation). Overfitting is indicated if the training accuracy (or any performance measure) is significantly higher than what you observe on the validation set. If the gap between training and validation performance grows, it is likely that the tree is memorizing training data details.
When Might You Not Prune?
If your primary concern is maximum accuracy on the training data and interpretability is not critical, you might not prune. This is more common in ensemble methods where multiple unpruned or lightly pruned trees can be combined to reduce overall variance. However, for a single decision tree whose generalization and clarity are important, pruning almost always helps.
What if the Tree Is Already Shallow?
Sometimes the data is simple, or the features do not allow the tree to grow very deep. If the tree is inherently shallow and does not exhibit a significant drop in validation performance, you may not need extensive pruning. In such a scenario, it might be overkill to devote too much effort to pruning adjustments that do not significantly affect overall performance.
These considerations and follow-up questions illustrate the essential concepts around why pruning is typically needed and how you might implement and tune it in real-world applications.