
ML Interview Q Series: What key metrics should be tracked to detect and prevent fraud, and how do they improve security?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
Designing a robust fraud detection system involves identifying key metrics that both capture the likelihood of fraudulent behavior and allow for timely intervention. Below is an in-depth perspective on which metrics to track and how they contribute to real-time fraud detection and overall platform security.
Precision, Recall, and Their Importance
Precision and recall are two critical measures of a fraud detection system’s effectiveness. Since fraud detection often deals with heavily imbalanced data (with legitimate transactions outnumbering fraudulent ones), it’s essential to focus on how many true fraud cases are being caught and how many legitimate transactions are erroneously flagged.
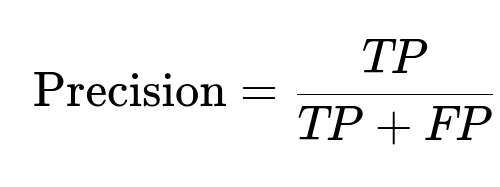
Where:
TP stands for true positives, meaning transactions correctly classified as fraudulent.
FP are false positives, meaning legitimate transactions incorrectly marked as fraud.
A high precision means that when the system flags a transaction, it is likely to be truly fraudulent, which helps reduce unnecessary disruption to valid customers.

Where:
FN represents false negatives, meaning fraudulent transactions not caught by the system.
A high recall is crucial for catching the maximum number of fraudulent instances. In practice, there is often a trade-off between precision and recall: overly aggressive thresholds may lead to high recall but lower precision, while conservative thresholds can yield high precision but might miss too many fraudulent cases.
F1 Score
To balance precision and recall, the F1 score is frequently used:

A robust fraud detection system generally tries to optimize the F1 score, ensuring a compromise between catching a sufficient number of fraudulent transactions (recall) without creating too many false alarms (precision).
False Positive Rate and True Positive Rate
Sometimes, analyzing the broader pattern of detection performance is essential. False positive rate (FPR) and true positive rate (TPR) can inform an operator on system bias.

(Which is the same as recall, measuring the proportion of actual fraud that is caught.)

Where:
TN are true negatives, meaning legitimate transactions correctly identified.
Monitoring TPR and FPR at various thresholds helps determine the best operating point, depending on how aggressively or conservatively you want to label transactions.
Receiver Operating Characteristic (ROC) and AUC
The ROC curve plots TPR against FPR at different threshold settings. The area under the ROC curve (AUC) is a single-value measure to compare different models or thresholds. AUC near 1.0 suggests that the model has excellent separation capacity between fraud and non-fraud events. This metric can be helpful when you want to evaluate the overall ranking capability of your model.
Real-Time Metrics
Real-time scenarios demand more than just offline metrics. Systems often track:
Throughput: The speed at which transactions are processed.
Latency: Time taken from the moment a transaction is initiated to when a decision (fraud or not) is returned.
Alert Volume: The number of alerts generated within a time window. Spikes in alert volume often indicate an attack or possibly an adjustment needed in detection thresholds.
User Session Anomalies: Sudden surges in the number of transactions from a single user or location can be monitored for anomalies.
How Metrics Enable Real-Time Fraud Detection
Immediate Alerts: By continuously monitoring TPR and FPR in a streaming environment, the system can raise immediate alerts and dynamically adjust thresholds if FPR becomes too high (resulting in customer dissatisfaction) or if TPR drops (indicating more fraud slipping through).
Adaptive Thresholds: Real-time monitoring of precision and recall allows the fraud model to update threshold decisions on-the-fly, balancing the risk tolerance (e.g., strict detection to minimize fraud or more lenient detection to improve customer experience).
A/B Testing: In a real-time setting, different fraud detection methods or thresholds can be tested in a controlled manner. Their F1 score or AUC can be tracked in near real-time to see which approach yields a better detection rate with minimal disruption.
Practical Example (Python)
Below is a simplified example of how one might set up a batch fraud detection routine using Python with scikit-learn. For real-time detection, you would typically stream the transactions into a system (like Apache Kafka) and score them as they come in.
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import precision_score, recall_score, f1_score, roc_auc_score
# Synthetic dataset
X_train = np.random.rand(1000, 10)
y_train = np.random.randint(2, size=1000) # 0 = legit, 1 = fraud
X_test = np.random.rand(200, 10)
y_test = np.random.randint(2, size=200)
# Train a Random Forest Classifier
model = RandomForestClassifier(n_estimators=50, random_state=42)
model.fit(X_train, y_train)
# Predict
y_pred = model.predict(X_test)
y_proba = model.predict_proba(X_test)[:, 1]
# Calculate key metrics
precision_val = precision_score(y_test, y_pred)
recall_val = recall_score(y_test, y_pred)
f1_val = f1_score(y_test, y_pred)
auc_val = roc_auc_score(y_test, y_proba)
print("Precision:", precision_val)
print("Recall:", recall_val)
print("F1 Score:", f1_val)
print("AUC:", auc_val)
In a real-time scenario, you would keep these calculations updated in a streaming fashion, recalculating metrics on the latest batches of transactions or within a rolling time window.
Improving Overall Platform Security
Feedback Loops: Continuously retraining or updating models with recent fraud labels ensures that the system stays current against new fraud patterns.
Feature Engineering: Incorporating user behavioral patterns, session-level analytics, and device fingerprinting features can significantly improve detection rates.
Multi-Layered Checks: Combining supervised approaches (Random Forests, Gradient Boosted Trees, Deep Neural Networks) with unsupervised or semi-supervised anomaly detection (autoencoders, isolation forests) can boost robustness against novel fraud vectors.
Human in the Loop: For high-value or ambiguous cases, escalating to a manual review team reduces the cost of missed fraud while preventing an excessive number of incorrect blocks.
Potential Follow-up Questions
How would you handle the highly imbalanced nature of fraud data?
Fraudulent transactions are typically only a small fraction of overall transactions. This imbalance can cause standard classification algorithms to be biased toward predicting the majority class. Techniques include:
Oversampling the minority class (fraud).
Undersampling the majority class.
Generating synthetic samples (SMOTE).
Using advanced loss functions or class weights that penalize incorrect predictions on the minority class more heavily.
These methods help the model learn minority fraud patterns more effectively.
Which metrics are most crucial when cost of misclassification varies?
Different organizations assign different monetary losses to false positives vs. false negatives. In cases where failing to detect fraud (false negative) is extremely costly, recall might be prioritized. If legitimate transactions must not be blocked too often, precision or FPR might be more critical. In practice, a cost-based metric or a custom scoring function can be used to weigh different types of errors.
How can you detect new, unseen fraud patterns?
Fraudsters constantly evolve their tactics, so supervised learning on historical data alone might not always catch emerging patterns. Approaches include:
Unsupervised Anomaly Detection: Models like isolation forests, clustering, or autoencoders that detect unusual transactions based on learned patterns of normal activity.
Semi-Supervised Learning: When labeled examples of fraud are scarce, these methods leverage large amounts of unlabeled data to model normal transactions and detect outliers.
Feature Engineering for Emerging Signals: Continually introducing new features reflecting novel tactics (e.g., new device types, suspicious IP addresses) and retraining models to maintain relevance.
What steps would you take to operate and maintain a real-time fraud detection system?
Data Pipeline Setup: Use streaming platforms (e.g., Apache Kafka) to gather transaction data in near real-time.
Model Serving Layer: Leverage frameworks like TensorFlow Serving or TorchServe to provide low-latency inference.
Monitoring and Alerting: Implement continuous monitoring of system metrics (FPR, throughput, etc.) and trigger automated alerts if thresholds are exceeded.
Regular Model Refresh: Schedule frequent retraining or incremental learning using the latest data. This ensures the model stays updated with recent fraud tactics.
Failover and Redundancy: Make sure the system has fallback rules or simpler ML models to handle downtime or performance issues in the primary model.
These components, combined with vigilant data governance, form a robust real-time fraud detection pipeline that safeguards the platform without overly burdening legitimate users.
Below are additional follow-up questions
How can you handle concept drift in real-world fraud patterns?
Concept drift refers to the phenomenon where the statistical properties of the target variable or features change over time. In fraud detection, fraudsters continually adjust their tactics, causing your model's assumptions to become obsolete.
To handle concept drift, it is common to maintain a rolling window of recent transactions and regularly retrain or fine-tune models on this latest data. Another option is to use online learning techniques that update model parameters incrementally as new labeled data arrives. Monitoring changes in key metrics such as precision, recall, and false positive rate over time helps you detect the onset of drift. Once drift is observed (e.g., a sudden drop in recall), you can initiate more frequent retraining or adjust thresholds to accommodate new fraud patterns.
A significant pitfall is assuming the historical feature distribution remains stable. In real-world scenarios, user behavior (both legitimate and fraudulent) can shift seasonally or due to external events. A system that is not regularly monitored and updated may degrade and fail to catch emerging fraud schemes.
How do you address the interpretability of complex fraud detection models, such as deep neural networks?
Highly complex models like deep neural networks or ensemble models (e.g., gradient boosting) often exhibit high predictive performance but can appear as “black boxes.” In many regulated industries (finance, healthcare, etc.), it is important to explain why a particular transaction was flagged or not flagged as fraudulent.
Interpretability techniques such as Integrated Gradients, LIME (Local Interpretable Model-agnostic Explanations), or SHAP (SHapley Additive exPlanations) can be employed. These methods provide local explanations around individual predictions, showing which features contributed most to the fraud classification.
In real-world operations, it helps to have a dashboard that displays these explanations to risk analysts, so they can manually review ambiguous cases. One potential challenge is that the high dimensionality of transaction data, combined with constant updates in user behavior, can make explanations complex or inconsistent. Nonetheless, partial interpretability is often sufficient to meet regulatory or business requirements and build stakeholder trust in the system.
Can you combine rule-based approaches with machine learning models in fraud detection?
Yes. Combining rule-based systems with machine learning often yields a more robust solution. Rule-based systems can quickly capture domain knowledge or compliance regulations, such as country-level restrictions, blacklisted IP ranges, or transaction velocity rules. Machine learning models, on the other hand, can learn nuanced patterns from historical data and generalize better to subtle fraud behaviors.
In practice, the rules might serve as a first filter. Transactions that violate explicit business constraints can be flagged immediately, reducing the load for the machine learning model. More ambiguous cases can then be analyzed by a data-driven model. This approach maintains transparency for certain high-risk, well-defined conditions while leveraging model-based insights for all other aspects.
A potential edge case arises if your rule-based engine and model disagree frequently. For example, the rules might be too lenient or contradictory to the model's predictions. Ensuring that these two mechanisms align and do not cause confusion or excessive false positives requires carefully tuning both the rule sets and the model thresholds. Regular audits are essential to ensure older rules do not become obsolete over time and clash with new model outputs.
How would you detect coordinated or ring-based fraud activity?
Coordinated fraud, or collusion, occurs when multiple users or accounts conspire to defraud the system, often sharing resources or transactions in ways that individually may not appear suspicious. Traditional single-transaction classification might miss these patterns.
Graph-based methods can help detect interconnected entities. Constructing a graph where nodes represent users or devices and edges represent shared characteristics (e.g., IP addresses, email domains, device fingerprints) can reveal clusters of suspiciously linked accounts. Community detection algorithms or network-based features (like centrality measures) can highlight rings of accounts that frequently transact with each other in abnormal ways.
One pitfall is the potential for false positives in shared-resource environments (e.g., multiple legitimate users logging in from the same public Wi-Fi). To address this, it's important to incorporate additional signals (e.g., transaction timing, user behavior profiles) before labeling a connected component in the graph as fraudulent. Human domain expertise, combined with advanced data engineering to ensure consistent linking of entities, is critical.
How do you ensure minimal impact on legitimate users when deploying real-time fraud checks?
Real-time checks must not create friction for the majority of honest users. Excessive false positives can drive customer dissatisfaction and churn. Systems typically employ a multi-tier or risk-based approach to ensure that only high-risk transactions undergo additional verification. Lower-risk transactions, determined by model scores or domain rules, can proceed with minimal disruption.
One strategy is adaptive risk scoring. Each transaction is assigned a fraud risk score; transactions exceeding a certain threshold might trigger a step-up authentication (e.g., one-time password, biometrics). This balance limits friction to only the small subset of users whose behavior appears suspicious.
A subtle edge case is when the risk threshold is set too low and too many customers must endure second-factor checks, especially during peak transaction times like a holiday sale. This can cause system latency and might reduce customer satisfaction. Monitoring the proportion of transactions subject to extra verification in real time helps you dynamically tune the threshold based on business needs and fraud pressure.
How do you safeguard against adversarial attacks on the fraud detection model?
Fraudsters sometimes attempt “model probing,” where they repeatedly submit slightly varied transactions to deduce the model’s internal logic and identify ways to evade detection. This is a form of adversarial attack aimed at circumventing your detection thresholds.
You can deploy rate-limiting and behavioral analytics to detect suspiciously repetitive or systematic queries, even if they are not outright fraudulent transactions. Another tactic is to use adversarial training, where you augment your dataset with artificially perturbed examples that mimic potential evasion attempts, improving model robustness.
A potential challenge is balancing performance with security. Making a model robust to adversarial examples often requires additional training time, more data, and refined hyperparameters. Moreover, purely machine learning approaches might not be enough. Defensive measures—like blocking IP addresses engaged in repeated suspicious attempts or employing CAPTCHAs—may be necessary to prevent automated probing.
How do you handle data privacy and compliance (e.g., GDPR, CCPA) when building a fraud detection system?
Fraud detection can involve storing and analyzing sensitive personal or financial information. Compliance with regulations like GDPR or CCPA requires transparent data usage and implementing the principle of data minimization (collecting only what is necessary). It also requires secure data storage with strong encryption at rest and in transit.
Privacy-preserving techniques, such as differential privacy or federated learning, can help in situations where data sharing is restricted. For example, if multiple financial institutions share fraud patterns, they may do so via secure enclaves or cryptographic techniques that preserve user anonymity.
One pitfall is failing to manage data retention carefully. Regulatory frameworks often stipulate time limits on storing user data, especially when it is no longer necessary for operational purposes. Thus, your data pipeline must support secure deletion or anonymization of records. Failing to do so can expose the organization to substantial legal risk, even if your technical detection system is effective.
How would you handle dynamic thresholds for real-time alerting in large-scale systems?
In high-volume environments, a fixed threshold may not adapt well to sudden changes in transaction volume or typical user behavior. For instance, a holiday sale or major sporting event can significantly alter transaction characteristics, potentially spiking the false positive rate.
By analyzing past seasonal or event-based data, you can model a baseline of “normal” activity. Then, thresholds can be adjusted relative to expected variations. One approach is to compute statistical bounds (e.g., mean ± k*standard_deviation) for real-time features like transaction velocity or average transaction size. The system can dynamically adjust these bounds as new data streams in.
The main concern with dynamic thresholds is avoiding oscillations—frequent threshold changes might cause instability. Implementing smoothing or a hysteresis mechanism ensures that small fluctuations do not overly shift the threshold. Continual monitoring of key performance indicators like the false positive rate and user complaint volume helps tune the dynamic threshold mechanism.
What is the difference between pre-authorization fraud checks and post-transaction monitoring?
Pre-authorization checks evaluate the transaction at the point of initiation, before funds are transferred. This approach stops fraud in real time, preventing potential financial losses. However, the time window is shorter, and any additional checks must be completed quickly to avoid user dissatisfaction.
Post-transaction monitoring involves analyzing transactions after they have been authorized. This allows for more in-depth scrutiny and advanced analytics but typically requires a reconciliation or chargeback mechanism if fraud is detected. Real-world systems often incorporate both: rapid, lightweight checks at the point of sale, followed by ongoing analysis of transactional data to catch patterns that only become visible over time (e.g., repeated suspicious behavior in a short window).
A subtle challenge arises with the possibility of chargeback fraud, where a user might dispute transactions after receiving goods. If only post-transaction monitoring exists, you risk losing inventory or incurring large processing fees before detection. Balancing pre- and post-authorization checks depends on the tolerance for user friction and the typical amounts at stake.
How do you handle incomplete or noisy data in fraud detection?
Real-world datasets often have missing entries or inconsistencies. For example, a user’s address might be partially filled, or device fingerprinting might fail for certain browsers. You can handle missing data via imputation, using either statistical methods (like mean/median replacement) or more advanced methods like k-nearest neighbors or model-based imputation.
Another approach is to engineer specific “missingness indicators” as additional features, which can sometimes correlate with fraudulent behavior (e.g., repeated partial addresses might be intentional obfuscation by fraudsters). Data cleaning pipelines that identify corruption or inconsistent transaction timestamps can also reduce spurious alerts.
An edge case arises when legitimate but atypical behavior is labeled as incomplete data, inadvertently boosting false positives. For instance, a legitimate user might have a privacy plugin that blocks certain device attributes. Rather than treating all unknown attributes as high risk, calibrate your system to distinguish malicious omission from legitimate privacy choices.