
ML Interview Q Series: What sets Maximum Likelihood Estimation apart from Gradient Descent?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Maximum Likelihood Estimation (MLE) typically refers to a framework for estimating parameters of a statistical model by maximizing the probability of the observed data, under the assumption that the model parameters fully explain how the data was generated. In contrast, Gradient Descent is an optimization procedure or algorithm used to minimize or maximize a function by iteratively moving in the direction of steepest descent or ascent with respect to the parameters.
In MLE, we define a likelihood function that quantifies how likely the observed data is, given a set of model parameters. The fundamental task is to figure out which parameters make the observed data most probable. This approach is rooted in probability theory, and it often leads to closed-form solutions in simple scenarios.
Gradient Descent, on the other hand, is not specifically tied to a probabilistic interpretation by default. Instead, it is a generic numerical method to optimize a function. When the objective function is a negative log-likelihood, Gradient Descent directly translates to maximizing the likelihood by minimizing the negative log-likelihood. However, one can also use Gradient Descent to optimize functions that have no direct link to likelihood or probability.
A critical difference is that MLE is a principle (a criterion) for parameter estimation, stating "choose the parameters that make the data most likely," whereas Gradient Descent is a technique (an algorithm) for actually finding the optimal parameters that maximize or minimize some objective. Sometimes, if the likelihood function is analytically tractable, you can solve for the parameter values by setting partial derivatives to zero. In more complex models (like deep neural networks), you typically do not have a closed-form analytical solution for MLE, so you end up applying Gradient Descent (or a variant) to approximate the solution.
Mathematical Formulation of MLE
Suppose we have observed data x_1, x_2, ..., x_n which are assumed to be drawn independently from a distribution parameterized by theta. The likelihood function is the product of the probabilities of each data point:
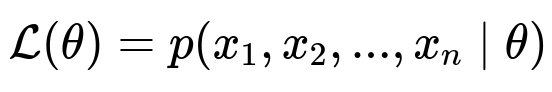
Here, p(x_1, x_2, ..., x_n | theta) represents the probability of observing the data x_1, x_2, ..., x_n given the parameters theta. For convenience, we often take the log-likelihood, log L(theta), because products turn into sums, which is typically easier to handle when taking derivatives.
To find the MLE solution, we can take the derivative of the log-likelihood with respect to theta, set it to zero, and solve for theta. This yields the parameter values that maximize the likelihood.
When the log-likelihood is difficult to optimize analytically (as in many deep learning applications), we rely on numerical optimizers such as Gradient Descent.
Mathematical Idea of Gradient Descent
Gradient Descent is a more general concept. Imagine you have a function J(theta) that you want to minimize. This function might be the negative log-likelihood if you're doing MLE-based training of a model. The algorithm updates theta iteratively using the gradient of J(theta):
theta := theta - alpha * gradient(J(theta))
where alpha is the learning rate. This is repeated until convergence or until a specified number of iterations is reached. Although you can directly apply Gradient Descent to carry out MLE by treating J(theta) as the negative log-likelihood, it is also used in any situation where you have an objective function that you want to optimize, regardless of whether or not it arises from a probability model.
Key Distinctions
MLE is an estimation principle focusing on maximizing the probability of observed data based on a statistical model. Gradient Descent is a general numerical optimization method that can be used to find the maxima or minima of any differentiable function, including, but not limited to, likelihood functions.
Practical Implications
In simpler statistical models (for example, fitting a Gaussian distribution's mean and variance), you can apply MLE analytically without any iterative method. In more complex neural network models, you do not typically have a closed-form solution, so you implement MLE by using Gradient Descent on the negative log-likelihood objective (or similar).
Both concepts are important: MLE provides the theoretical underpinning of how to choose parameter values under a probabilistic framework, and Gradient Descent is the de facto algorithmic workhorse for performing the heavy lifting when no closed-form solutions exist.
What If the Log-Likelihood Is Non-Convex?
In more complex models, like deep networks, the log-likelihood surface can be non-convex, meaning Gradient Descent does not guarantee a global optimum. Nonetheless, it remains a practical approach for large-scale problems, often yielding good solutions even if they are local optima or saddle points.
Follow-Up Questions
How do you interpret the solution you get from MLE versus one obtained from Gradient Descent when the objective function is not a likelihood?
When the function you are optimizing is not a likelihood (or a negative log-likelihood), you are no longer operating in a strict MLE paradigm. You might instead be in a scenario like minimizing mean squared error or some other loss function (for instance, cross-entropy in classification tasks). Although cross-entropy is closely related to the negative log-likelihood, for different loss definitions (like custom loss functions), you do not have that same "probability of data" interpretation. The solution reached via Gradient Descent in these cases has no direct probabilistic interpretation as the "most likely" parameters. Instead, it is merely the set of parameters that optimize the chosen metric (e.g., minimize reconstruction error in autoencoders or maximize margin in a hinge-loss scenario).
What are some potential pitfalls of using Gradient Descent to perform MLE in very high dimensions?
In high-dimensional parameter spaces, Gradient Descent can face challenges such as getting stuck in poor local minima, converging to saddle points, or moving extremely slowly if the learning rate is not well tuned. Additionally, the gradient might become very small (vanishing gradients), or it can explode if the function landscape is steep in certain directions. These difficulties can sometimes be mitigated by using advanced optimizers like Adam, RMSProp, or employing techniques like batch normalization and residual connections in neural networks. Still, even with these techniques, high-dimensional optimization can be tricky, and ensuring a stable convergence often requires careful hyperparameter tuning, architecture design, and regularization.
Would you always need Gradient Descent for MLE?
No. If the model you are using has a log-likelihood function that can be differentiated and solved for parameters in closed form, you do not need an iterative solution like Gradient Descent. A classic example is fitting the mean of a Gaussian distribution with known variance, where you can directly derive the MLE for the mean without needing iterative procedures. However, in most modern deep learning architectures, a closed-form solution does not exist, so we rely on Gradient Descent-based approaches.
Why is MLE popular in machine learning?
MLE aligns with many foundational statistical theories like the asymptotic properties of consistency and efficiency. Under certain regularity conditions, MLE is consistent, meaning as the sample size grows large, the MLE converges to the true parameter values. Moreover, it often has desirable variance properties. Its connection to information theory, especially via the cross-entropy loss, makes it a natural choice for training classification and language models. The conceptual simplicity (maximizing the probability of observed data) also helps unify many machine learning methods under one statistical framework.
Below are additional follow-up questions
How do you handle constraints on parameters (for example, parameters that must be positive) when performing MLE or using Gradient Descent?
When certain parameters have to lie within specific bounds, the unconstrained approach of standard Gradient Descent or pure MLE can violate those constraints. One common strategy is to perform a re-parameterization. For instance, if a parameter must remain strictly positive, you can model it as exp(alpha), where alpha spans the real line. Then you apply Gradient Descent or MLE on alpha instead of directly on the parameter, thereby naturally ensuring positivity.
Another approach might be to use constrained optimization techniques, such as projected Gradient Descent. In projected Gradient Descent, you update parameters as usual but then project them back into the feasible region if they step out of bounds. Optimizers like L-BFGS-B can handle box constraints as well.
A subtle issue arises if your parameter space is restricted but you do not carefully design your model or transformation. You might end up with local optima near the boundaries or fail to converge if the optimization landscape along the boundaries is steep. Moreover, the re-parameterization can change the geometry of your optimization problem in ways that impact how quickly the parameters converge.
How do you diagnose and address potential underflow or overflow when computing likelihoods in MLE?
Underflow or overflow can happen when dealing with very small or very large probabilities in MLE. For example, when computing the product of probabilities for numerous data points, these products may become vanishingly small, leading to numerical underflow. One standard remedy is to work with the log-likelihood rather than the likelihood directly. Because sums of logs are more numerically stable than products of probabilities, this helps avoid extreme underflow or overflow.
Even then, some likelihood terms might be extremely large or extremely small. If you see NaN (not a number) values during training, it might indicate that certain computations exceeded floating-point limits. Mitigation strategies include gradient clipping (to keep updates controlled), using higher-precision data types (like float64 instead of float32), or carefully normalizing data. Sometimes, you may restructure your model to reduce large magnitude updates, for instance by factoring out scaling parameters or standardizing your inputs.
In what scenarios would MLE become ill-posed or unidentifiable, and how does this affect Gradient Descent?
MLE can become ill-posed if there is insufficient information in the data to uniquely identify the parameters. This can occur when:
You have too few data points relative to the number of parameters.
Certain parameters do not significantly influence the likelihood (e.g., they are perfectly collinear or redundant).
The model is too flexible (overparameterized) and can fit noise or produce multiple equally optimal solutions.
In such cases, Gradient Descent may fail to converge to a unique solution; it could wander among many near-optimal solutions or get stuck in flat regions of the parameter space. To mitigate this:
Regularization methods (like adding a penalty to the likelihood or using Bayesian priors) can help encourage unique solutions.
Dimensionality reduction or pruning techniques can reduce the effective parameter space.
Gathering more data or focusing on simpler models can make the estimation problem better posed.
An unidentifiable model also makes interpretation challenging because multiple parameter sets could generate nearly identical likelihood values. This can be especially problematic if the goal is to interpret parameters rather than merely make predictions.
How do outliers influence MLE, and can Gradient Descent help mitigate their effects?
With MLE, outliers can disproportionately affect parameter estimates, particularly when the model assumes a certain error distribution that assigns small probabilities to outlier points. For example, in a Gaussian-based likelihood, a single extreme outlier can significantly shift the estimated mean or inflate the variance.
Gradient Descent itself is just an optimization algorithm—it does not intrinsically solve the outlier problem. If your objective (negative log-likelihood) is sensitive to outliers, Gradient Descent will faithfully find a solution that tries to accommodate them, often to the detriment of the overall fit.
To reduce the effect of outliers, you might consider:
More robust loss functions or likelihood models (e.g., using a Laplace distribution or heavy-tailed distributions).
Weighting schemes that downplay extreme residuals.
Outlier detection and removal in pre-processing steps (though removing data must be done cautiously).
Additionally, using methods like stochastic Gradient Descent can sometimes reduce the impact of outliers if they appear in a small fraction of the batches, but it is not a guaranteed solution. The best safeguard is to ensure your likelihood assumption matches the reality of your data distribution as much as possible or to opt for robust alternatives if outliers are anticipated.
How would you incorporate domain knowledge or prior beliefs into the MLE framework, and how does that differ from applying Gradient Descent?
In classical MLE, the approach is purely data-driven: you select the parameters that maximize the likelihood of the observed data. If you have extra information or strong priors, you might shift to a Bayesian framework. Instead of maximizing p(data | parameters), you maximize p(data | parameters) * p(parameters), where p(parameters) encodes prior beliefs.
To incorporate priors in a Bayesian setting, you typically maximize the posterior distribution. This is known as Maximum A Posteriori (MAP) estimation, which modifies the MLE objective by adding a log-prior term to the log-likelihood. Gradient Descent can still be used in this scenario, but the objective now reflects both the likelihood and the prior:
MLE objective: maximize log-likelihood or minimize -log-likelihood.
MAP objective: maximize log-likelihood + log-prior or minimize -log-likelihood - log-prior.
The difference is conceptual: MLE tries to find the parameter set best supported by data alone, while MAP balances data with your existing beliefs. Numerically, both can be solved via Gradient Descent. The main difference is the form of the loss function, which now includes a term reflecting the prior.
How does MLE compare to methods like Method of Moments or Bayesian estimation in practice, and does Gradient Descent affect this comparison?
Method of Moments matches sample moments (like sample mean or variance) to the theoretical moments of the distribution to solve for parameters. It is often less statistically efficient than MLE, but it can be simpler for certain problems, especially if the likelihood is cumbersome.
Bayesian approaches add priors and focus on the posterior distribution. You might use sampling methods (like Markov Chain Monte Carlo) or variational methods to approximate the posterior, which can be more computationally intensive than MLE. Gradient Descent might be used as part of a variational approach, or in MAP estimation, but in pure Bayesian sampling you often rely on different algorithms (e.g., Gibbs sampling or Hamiltonian Monte Carlo).
In real-world settings, the choice depends on data size, computational resources, interpretability needs, and how strongly you want to incorporate prior knowledge. MLE is often faster to compute with Gradient Descent (especially in large-scale machine learning), whereas Bayesian methods can give richer information about uncertainties at the cost of extra computation. Method of Moments might be chosen when the structure of the model is simple, or you want a quick approximate solution.
How do you tune hyperparameters such as learning rate, batch size, or regularization coefficient when using Gradient Descent for MLE in deep learning models?
When applying MLE through Gradient Descent in deep learning, tuning hyperparameters is crucial for stable and efficient training:
Learning Rate: A learning rate that is too large can lead to divergence or oscillation; one that is too small makes training painfully slow. Adaptive methods (Adam, RMSProp) help manage these pitfalls by scaling learning rates dynamically based on gradient statistics.
Batch Size: Using very large batches can lead to more stable but slower parameter updates, and might potentially converge to different minima than smaller batches. Very small batches can introduce too much variance in the gradient estimates. A moderate batch size is often a practical compromise.
Regularization Coefficients: These can include weight decay (L2), dropout rates, or other forms of penalty. Insufficient regularization can lead to overfitting, while excessive regularization can lead to underfitting or poor representation learning in neural networks.
Hyperparameter tuning typically relies on a separate validation set or cross-validation. Automated methods like grid search, random search, or Bayesian optimization can be employed. One edge case arises when the model capacity is extremely large relative to the data size, making it easy to overfit. Another edge case is when the data distribution shifts over time; static hyperparameter settings might become suboptimal, requiring dynamic tuning or continued training with new data.
How do you handle non-differentiable or piecewise-defined likelihood functions where Gradient Descent might fail?
Gradient Descent relies on computing gradients of your objective. If you have a non-differentiable likelihood, or if it is piecewise-defined and not differentiable at boundaries, standard Gradient Descent may fail or behave erratically.
Approaches to handle this include:
Subgradient or Proximal Methods: For piecewise-linear or convex objectives, you can use subgradient techniques that generalize Gradient Descent for non-smooth functions.
Smoothing the Likelihood: In some cases, you can approximate discontinuous points with a smooth function that closely mimics the original function.
Specialized Optimization Algorithms: If your likelihood has a combinatorial flavor or discrete components, algorithms such as Expectation-Maximization (EM) or discrete optimization methods might be more suitable.
Pitfalls include getting stuck in points where the subgradient does not provide informative direction or the approach diverges if the non-differentiable regions dominate the parameter space. Careful design or selection of the objective and model structure can help avoid these complications altogether.
How do you decide when to stop Gradient Descent when performing MLE, given that global optima might be hard to verify?
Stopping criteria in Gradient Descent can be tricky when the objective is non-convex or complex:
Validation-Based Early Stopping: Monitor validation log-likelihood (or validation loss if you minimize negative log-likelihood). Once it stops improving for several iterations, you can stop training to avoid overfitting.
Gradient Norm: You can stop when the magnitude of the gradient becomes sufficiently small, indicating a flat region or near-stationary point.
Parameter Norm or Change: Stop if parameter updates become negligible between iterations, suggesting convergence.
A subtlety arises because not every small gradient norm is a global optimum. You could be at a local minimum or a saddle point. Additionally, in large-scale deep learning, the concept of “global optimum” can be less critical if you just need parameters that generalize well. As a result, practical heuristics (like early stopping and patience counters) tend to be more common than waiting for a formal proof of optimality.
How do you approach regularizing an MLE objective, and are there pitfalls in combining regularization with Gradient Descent?
Regularizing an MLE objective means adding penalty terms to the log-likelihood to avoid overfitting or to guide solutions toward specific parameter values. This effectively shifts the MLE toward a MAP estimation perspective if you interpret the penalty as a log-prior. Common regularizers include L2 (weight decay), L1 (lasso-like penalty), or group-sparse penalties.
Pitfalls include:
Over-regularization, which might bias parameters so heavily that you lose critical signal from the data.
Inconsistent or mismatch penalty scale, causing numerical instability in Gradient Descent. For example, if the regularization coefficient is extremely large, the parameter updates might be dominated by the penalty.
Complex penalty terms that introduce additional local minima or non-differentiable points (e.g., absolute value in L1).
Despite these challenges, properly tuned regularization is essential in large-scale modeling scenarios for controlling complexity and improving generalization.