
ML Interview Q Series: When are regularization methods and cross-validation most appropriately applied to boost a machine learning model’s performance?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
Regularization and cross-validation serve different but complementary roles in machine learning. Both techniques address the challenge of producing well-generalized models that perform robustly on unseen data, but they accomplish this in distinct ways.
What Regularization Does
Regularization is a strategy to reduce overfitting by penalizing large or overly complex parameter values in the model. The central idea is to keep the model as simple as possible, without losing too much predictive power.
A common way to represent regularization for linear or logistic regression is to add a penalty term to the loss function. For instance, in L2 (Ridge) regularization, the penalty is the sum of squares of the model's parameters. The objective might look like:

Here, w is the vector of parameters, n is the number of data points, y^(i) are the true labels, and hat{y}^(i) are the predictions. The term lambda is the regularization strength: a larger lambda places more emphasis on keeping the parameters small, while a smaller lambda focuses on fitting the training data more closely.
Similarly, L1 (Lasso) regularization sums the absolute values of the parameters:
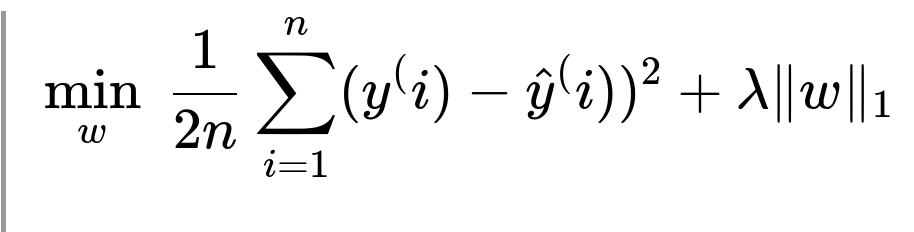
This also includes a term lambda that controls the trade-off between fitting the data and enforcing sparsity in the parameters. By setting some parameter values to zero, L1 regularization can perform feature selection.
Regularization is typically used whenever the model is complex or the dataset has many features. It also addresses multicollinearity issues. It is especially important in situations where data is limited, or where there is a risk that the model could “memorize” spurious patterns.
What Cross-Validation Does
Cross-validation is a technique to assess how well a model generalizes to unseen data and to tune hyperparameters. It partitions the dataset into a number of “folds” and iteratively trains on some folds while validating on the remaining fold(s). A common approach is K-fold cross-validation:
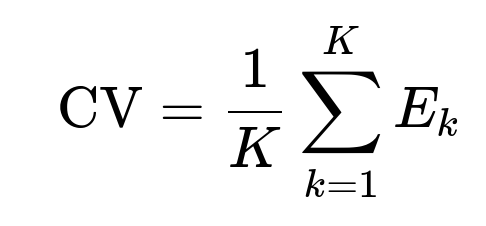
Here, K is the number of folds, and E_k is the validation error obtained by training on the other K-1 folds and testing on the k-th fold. This process creates multiple train-validation splits, providing a more reliable estimate of model performance than a single split.
Cross-validation is appropriate whenever we want a stable estimate of how well our model might perform in real-world scenarios and when we need to decide on hyperparameters (including regularization strength lambda, learning rates in neural networks, or the depth of decision trees). It is particularly crucial when data is limited because it makes efficient use of every data sample for both training and validation.
When to Use Regularization Versus Cross-Validation
Regularization directly modifies the model by adding constraints that reduce overfitting. Cross-validation checks how well a model generalizes by repeatedly training on subsets of the data and evaluating on complementary subsets. In typical practice, both are used together rather than viewed as alternatives, because they serve different purposes:
Use regularization when there is a clear risk of overfitting or the dataset is high-dimensional. By imposing a penalty on large parameter values, you help ensure the model finds a simpler function that generalizes better.
Use cross-validation to reliably select hyperparameters (e.g., strength of regularization), compare different models, or estimate the expected model performance on unseen data. Cross-validation helps you detect if your model is overfitting or if certain hyperparameters are helping or hurting performance.
They often work in unison: for instance, you might use cross-validation to select the optimal lambda for regularization. This combined approach is common in a wide range of machine learning applications.
What If the Dataset is Very Large?
Regularization is still valuable for large datasets to keep model complexity in check. However, a large dataset can sometimes reduce the risk of overfitting on its own, though not always. Cross-validation on a massive dataset can be computationally expensive but remains valuable. Often you can resort to techniques such as randomized subsampling or using fewer folds if K-fold is too time-consuming.
How to Implement Both in Practice
In Python, you might use scikit-learn’s Ridge, Lasso, or ElasticNet for regularization, combined with cross-validation utilities like GridSearchCV to find the ideal hyperparameter settings. A typical code snippet for Lasso with cross-validation might look like:
from sklearn.linear_model import Lasso
from sklearn.model_selection import GridSearchCV, KFold
X, y = ... # your features and labels
param_grid = {'alpha': [0.001, 0.01, 0.1, 1, 10, 100]} # regularization strengths
lasso = Lasso()
cv = KFold(n_splits=5)
grid_search = GridSearchCV(estimator=lasso, param_grid=param_grid, scoring='neg_mean_squared_error', cv=cv)
grid_search.fit(X, y)
print("Best alpha:", grid_search.best_params_['alpha'])
This grid search uses cross-validation to pick the best alpha (which corresponds to the lambda notation above) for the Lasso model.
Follow-up Questions
Could you elaborate on how elastic net regularization works?
Elastic Net regularization is a combination of L1 and L2 penalties. It controls the trade-off between the two penalties via an additional parameter that sets the proportion of each penalty to apply. You can adjust it to take advantage of both L1’s feature selection ability and L2’s smooth penalty on parameter values, often leading to more stable models when features are correlated.
How would you pick the best number of folds K for cross-validation?
Choosing K involves a trade-off. A larger K, such as 10, can produce a less biased estimate of model performance because you train on a larger fraction of the dataset in each fold. However, it can be more computationally expensive. Smaller K, such as 5, is faster but can have slightly higher variance in the performance estimate. In practice, 5-fold or 10-fold cross-validation is quite common because it balances computational cost and a reasonably good estimate of performance.
In what scenarios would I not rely on cross-validation?
Cross-validation can be skipped if you have an extremely large dataset and you can afford a simple train-validation-test split without sacrificing too much data for validation. Similarly, if you have time constraints that make repeated training prohibitively expensive, you might rely on a single validation set. Still, in most professional settings, cross-validation is regarded as one of the most robust methods to evaluate and fine-tune models.
What role does regularization play in neural network training?
In neural networks, regularization can take forms like weight decay (analogous to L2 penalties), dropout, or batch normalization. Dropout randomly “drops” a subset of neurons during each training iteration, preventing units from co-adapting too strongly. Weight decay penalizes large weights. Batch normalization can also have a stabilizing effect and indirectly regularize the model. These methods help keep the network from memorizing the noise in the training data, much like how L2 or L1 regularization aids simpler linear models.
Below are additional follow-up questions
Is it ever beneficial to combine multiple types of regularization within a single model?
Combining multiple types of regularization can be helpful in certain scenarios. One example is using both L1 (which promotes sparsity) and L2 (which promotes smoothness) simultaneously, often referred to as Elastic Net. This approach offers the benefits of feature selection (from L1) while still gently penalizing large parameter values (from L2). A potential pitfall arises if you choose poorly balanced hyperparameters for each penalty. For instance, an overwhelmingly large L2 component might overshadow the intended sparsity effect from L1, or vice versa. Another subtlety is that adding too many different types of regularization might overly constrain the model, leading to underfitting. In practice, one should experiment with cross-validation to tune these penalties, ensuring that each component brings genuine value.
What challenges arise when applying cross-validation to very noisy data?
With very noisy data, each fold in cross-validation can produce quite different performance metrics. The data splits may contain different “outlier” points, leading to higher variance in the validation scores. This makes selecting hyperparameters more difficult because results might be less stable across folds. A strategy to mitigate this variability is to increase the number of folds, allowing more stable estimates. However, more folds can amplify computational costs. Another edge case is if the noise is class-dependent (in classification tasks) or if there is label noise. In such cases, carefully cleaning or weighting certain examples can prove beneficial. Ignoring these issues might yield a model that appears inconsistent or overly sensitive to small shifts in the data.
How can you adjust cross-validation methods for time series or sequential data?
In time series problems, standard K-fold cross-validation can violate the temporal ordering of data. Using random folds might cause “future” information to leak into “past” training segments. A safer approach is time-series cross-validation, where folds respect chronological order. For example, you might train on data from days 1 to 100, validate on days 101 to 110, then train on days 1 to 110, validate on days 111 to 120, and so forth. A subtle pitfall arises when the time-series exhibits non-stationarity (trends or seasonality). If future data shifts significantly, performance estimates from any past-based validation might be less informative. Practitioners often incorporate a rolling window approach or treat known seasonality patterns differently to reduce mismatches between training and validation windows.
How should we handle cross-validation in extremely imbalanced classification scenarios?
When the dataset is highly imbalanced (e.g., 1% positive class, 99% negative class), a naive cross-validation split might not represent all folds equally well. Some folds could end up with very few positive examples, skewing performance metrics. Stratified cross-validation helps maintain class ratios in each fold, preserving a representative distribution for both training and validation sets. However, even stratification can be insufficient if the minority class is extremely rare or if the dataset is very small. One solution is to employ techniques like SMOTE (Synthetic Minority Over-sampling Technique) or class weights within each fold to give minority samples more influence. Beware of data leakage if the synthetic data generation references validation samples. Ensuring the synthetic examples are created only from the training set is essential to avoid overstating performance.
What if cross-validation indicates a particular model is best, but a separate hold-out test set disagrees?
This discrepancy can occur if the cross-validation procedure is not representative of the final hold-out set. Potential reasons include:
Different distributions: The test set might come from a slightly different distribution than the training data used in cross-validation.
Data leakage during cross-validation: Some information might have inadvertently seeped into the training folds, inflating validation performance.
Insufficient data: If each fold or the final test set is too small, statistical variance in performance estimates can be high.
A best practice is to design cross-validation folds to mimic as closely as possible the final hold-out scenario. Techniques such as nested cross-validation or employing multiple random splits might be used to gain a more robust understanding. If the discrepancy remains large, it might indicate the need for more data or that the model has specialized too closely to the cross-validation splits.
How do we ensure our regularization hyperparameters are robust in a production environment where data distribution can shift over time?
Data distribution shifts (also referred to as concept drift) can make previously well-tuned hyperparameters suboptimal. A common solution is periodic re-training or re-tuning. For instance, you could automatically run a cross-validation routine on the most recent data batches every few weeks or months. A subtle pitfall arises if the shift is gradual yet continuous—waiting too long to re-tune can lead to stale hyperparameters. Conversely, re-tuning too frequently might overreact to short-term fluctuations. In production systems, some companies implement automated pipelines that trigger re-training once certain performance metrics degrade beyond a threshold. Monitoring these pipelines is crucial, as abrupt data shifts can still require more immediate manual intervention.
Could improper regularization lead to underfitting, and how do we detect it?
Yes, if the regularization strength is too high, the model's parameters might be over-penalized, causing underfitting. This can manifest as consistently high training error, not just validation error. A common detection strategy is to look at both training and validation performance. If both are poor, it’s often a symptom of underfitting. Another sign is when you compare performance across different regularization strengths: if the model’s performance deteriorates markedly as the penalty grows, it suggests you might be suppressing important features or relationships. Monitoring coefficient values or feature importances can also help reveal whether the model is being forced to ignore too much of the data.
In which situations would you refrain from applying regularization altogether?
Regularization might be unnecessary if:
The model is inherently simple (e.g., a single decision stump) and the dataset is sufficiently large to avoid overfitting.
Domain knowledge assures us that certain features must carry large or non-sparse coefficients, and penalizing them would be detrimental.
The dataset is so large that the risk of overfitting is minimal compared to the harm of biasing the model.
However, a subtle edge case is that even seemingly large datasets can contain complex structures or rare subpopulations, so one shouldn’t dismiss overfitting concerns prematurely. Always validate your assumption by checking if a non-regularized model truly maintains stable performance across multiple data splits or over time.
How do kernel-based methods (e.g., SVM with RBF kernel) incorporate regularization, and are there any pitfalls?
In kernel-based methods like SVM with an RBF kernel, the regularization concept appears in two places: the C parameter (penalizing misclassifications) and sometimes parameters like gamma in the RBF kernel. C controls the trade-off between achieving a low training error and keeping the margin wide, effectively a regularization knob. A high C tries to correctly classify most training examples (risking overfitting), while a low C promotes a simpler decision boundary. If gamma is too large, the decision boundary can become overly complex. Pitfalls include the interplay between these hyperparameters: a small C but large gamma can still overfit, while a large C but small gamma might underfit. Cross-validation is essential to find a balance, and a typical trap is ignoring one of the parameters, resulting in suboptimal performance.
How should I monitor and maintain a cross-validation approach when the dataset grows continuously?
When data is continuously collected (as in streaming or incremental learning scenarios), re-running an entire K-fold cross-validation each time new data arrives can be computationally intense. One solution is incremental retraining with partial cross-validation on the newly added chunk of data. A potential pitfall is that ignoring older data can cause drift in the model if older patterns remain relevant. Conversely, if the distribution of new data changes dramatically, older data might become less relevant. Defining a sensible window of data to include in each re-training cycle is crucial. Some teams maintain a rolling buffer of data, discarding data older than a certain horizon. Others implement adaptive weighting schemes, giving more recent data higher importance while not ignoring historical patterns that may recur.