
ML Interview Q Series: When are SVMs better than deep learning, and how do they compare to logistic regression models?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
Support Vector Machines (SVMs) can excel in scenarios where dataset size is moderate, the feature space is well-defined, and the risk of overfitting is significant with deep learning. When data isn’t extremely large or doesn’t necessarily include high-dimensional raw inputs (like unprocessed images, audio, or text), an SVM can be more cost-effective and simpler to train than a deep neural network. Furthermore, it can deliver solid performance with fewer hyperparameters to tune and lower computational overhead if the kernel trick is used wisely. On the other hand, when data is vast, richly structured, and inherently suitable for hierarchical representation (such as images or language), deep learning models often outperform SVMs. Below are further details.
Mathematical Foundation of SVM
The primal optimization objective of a soft-margin SVM can be summarized through the following core formula:
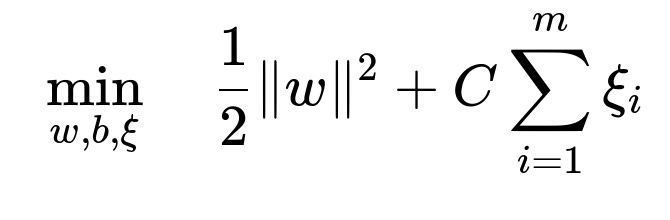
Where w is the weight vector learned by the SVM, b is the bias term, xi are the slack variables that allow some misclassification or margin violation, m is the number of training samples, and C is the regularization parameter controlling the trade-off between maximizing the margin and minimizing classification errors. The key objective is to find a hyperplane (defined by w and b) that separates classes in a high-dimensional space while maintaining the largest possible margin. The slack variables xi help handle non-linearly separable data by allowing certain data points to lie within or beyond the margin boundary.
Kernel Methods vs. Deep Models
An SVM can utilize different kernels to transform input data into a higher-dimensional space where classes are more easily separable. Popular kernels include the RBF (Radial Basis Function) kernel, polynomial kernel, and linear kernel. This notion is conceptually somewhat parallel to the representation learning in deep neural networks: a kernel function is a way of obtaining a more discriminative feature representation of the data, but it does so in a more controlled and mathematically direct manner.
Deep learning, by contrast, learns multi-layer, hierarchical representations from raw data. While this is immensely powerful in tasks like image classification or language modeling, it requires large annotated datasets, substantial computational resources, and careful hyperparameter tuning. If such resources or data are unavailable, a properly configured SVM can sometimes produce results that rival or surpass shallow neural networks and might also be much faster to train.
When SVMs Are Preferable
Limited Training Data If the dataset is not large enough for the deep network to learn stable representations, SVMs (possibly with an appropriate kernel) can generalize well with fewer training samples.
High Accuracy on Medium-Sized Datasets SVMs can achieve high accuracy on moderately sized datasets where the dimensionality is not excessively large, especially if the kernel trick is relevant for mapping data into a separable feature space.
Smaller Computational Budget Deep neural networks often require specialized hardware (e.g., GPUs) and a lot of memory; an SVM may be simpler to deploy and run on standard hardware.
Well-Engineered Feature Space If domain experts can craft or extract meaningful feature representations from the data beforehand, an SVM can effectively use these features without complex architecture searches and optimization.
Pros and Cons of SVM vs. Deep Learning Models
Pros of SVM
Strong Theoretical Underpinnings Their optimization objective is convex, leading to a global optimum solution in many formulations.
Works Well with Small/Medium Data Often more stable than large neural networks when the training set is not huge.
Kernel Trick Can handle non-linear classification without explicitly mapping to high-dimensional spaces.
Less Tendency to Overfit with Proper Regularization With correct selection of C and kernel parameters, overfitting risk can be mitigated.
Cons of SVM
Scalability to Very Large Datasets The training complexity can become prohibitive if the data is very large, especially with non-linear kernels.
Less Suited for Unstructured Data Deep learning architectures can automatically learn representations from images, text, and speech, whereas SVMs need manual feature extraction or suitable kernels.
Parameter Tuning Kernel choice and hyperparameters (C, kernel coefficients) can be tricky to optimize. Although simpler than choosing layers in a neural network, it still can be time-consuming.
Pros of Deep Learning
Representation Learning Learns its own features from raw data, which can be extremely beneficial if you have large labeled datasets.
Highly Scalable Utilizing GPUs/TPUs allows training on massive datasets with minimal user intervention in feature engineering.
Flexibility for Complex Data Modalities CNNs, RNNs, Transformers, and other architectures can handle images, text, audio, or multi-modal data better than traditional SVMs.
Cons of Deep Learning
Requires Large Datasets Performance can be subpar on smaller datasets due to high variance and overfitting.
Expensive to Train and Maintain Demands significant computational resources, and hyperparameter tuning can be complex and time-consuming.
Interpretability Challenges Deep models often function as black boxes, making it harder to understand how they arrive at predictions.
SVM vs. Logistic Regression
Decision Boundary Logistic regression tries to find a single linear boundary that best separates classes by maximizing the likelihood under a logistic function. SVM tries to find the maximum margin hyperplane, focusing on correctly classifying the most “hard-to-separate” points (support vectors).
Loss Function Logistic regression uses a log loss, whereas SVM often uses hinge loss. In low-dimensional or linearly separable scenarios, SVM can exhibit robust performance against outliers, while logistic regression can be more stable in the presence of noise if well-regularized.
Computational Complexity Both can be trained relatively quickly on smaller data. Logistic regression often is simpler and more interpretable, but SVM might yield higher accuracy for complex boundaries with an appropriate kernel.
Sample SVM Implementation in Python
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
# Create synthetic dataset
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize SVM with RBF kernel
svm_model = SVC(kernel='rbf', C=1.0, gamma='scale')
# Train the model
svm_model.fit(X_train, y_train)
# Predict on test set
y_pred = svm_model.predict(X_test)
# Evaluate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("SVM Test Accuracy:", accuracy)
Follow-up Questions
How would you approach tuning an SVM’s hyperparameters (e.g., C, kernel parameters)?
Tuning SVM hyperparameters typically involves systematic approaches like grid search or random search over a parameter space. You vary parameters such as C, which controls the regularization strength (a lower C focuses more on the margin but might allow more misclassifications), and gamma for an RBF kernel (which determines how far the influence of a single training example reaches). You can use cross-validation on each candidate parameter combination to estimate performance. The pair (C, gamma) that achieves the best cross-validation metric is often chosen as the final model.
One pitfall is the computational cost if you try too many parameter combinations, especially with large datasets. In practice, you can adopt a coarse-to-fine strategy: first do a coarse parameter search to narrow down a region of interest, then do a finer search around that region.
Why might SVMs perform poorly on very large datasets with non-linear kernels?
Training complexity of non-linear SVMs can be O(n^2) to O(n^3) in the worst cases, depending on implementation and dataset size n. When data is huge, the kernel matrix itself can be extremely large, making the fitting process slow or infeasible in memory. In such large-scale settings, linear SVM variants or approximate kernel methods might be employed. Alternatively, deep learning—while computationally expensive in its own right—scales better with the help of modern hardware (GPUs, clusters) and specialized libraries optimized for parallelism.
If my data is inherently high-dimensional (e.g., raw images), is an SVM with an RBF kernel a good choice?
In principle, yes, SVM with RBF kernel can handle complex boundaries in high-dimensional spaces. However, once the dimensionality is extremely large (like raw images) and you have a lot of data, a deep neural network may learn relevant representations directly from the raw inputs better than an SVM that relies on kernel transformations. SVMs in this scenario might also become expensive due to the computational cost of constructing and using large kernel matrices. Feature engineering or dimensionality reduction before applying an SVM can mitigate some of these issues, but at scale, deep models often prove more practical and performant.
Could combining an SVM with deep learning features be useful?
Sometimes it is beneficial to use a pre-trained deep model to extract features (like embeddings), then feed these features into an SVM. In cases where a deep model is already trained on a large dataset (for instance, a pre-trained CNN on ImageNet), you can extract the learned representations and use an SVM to perform the classification. This hybrid approach is often faster to train than fine-tuning an entire deep architecture from scratch and can still take advantage of the learned representations in the deep network. It can be especially useful if you have fewer domain-specific data points but still want to leverage powerful features from a model pre-trained on related data.