
ML Interview Q Series: Which techniques can help minimize overfitting in a logistic regression model?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Logistic regression, despite being relatively less prone to overfitting compared to highly flexible models, can still overfit when the number of features grows large or when the model is pushed to fit noise in the data. A key strategy to mitigate overfitting is regularization. The common types of regularization used in logistic regression include L2 (Ridge) regularization and L1 (Lasso) regularization. These introduce penalty terms into the cost function that penalize large coefficients, encouraging the model to find weights that are smaller in magnitude.
Below is the cost function for logistic regression, using L2 regularization, which is the most frequently used approach:
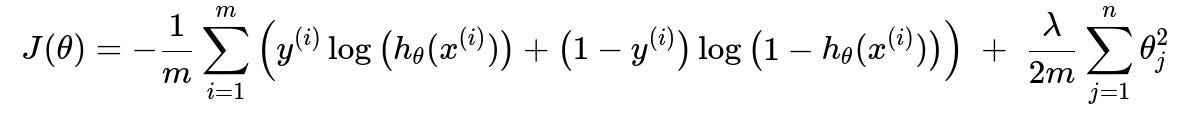
In this formula, J(theta) is the regularized cost function. The variable m is the number of training samples, n is the number of features, y^(i) is the observed label for sample i, x^(i) is the input feature vector for sample i, and lambda is the regularization hyperparameter that controls the strength of the penalty. The function h_theta(x) is the logistic (sigmoid) function, given by 1/(1 + exp(-theta^T x)) in plain text. The term theta_j for j=1..n are the parameters or weights. Note that often we do not penalize theta_0 (the intercept).
When lambda is large, the magnitude of the coefficients is heavily penalized, reducing the risk of overfitting but possibly increasing underfitting. When lambda is small, the penalty is weaker, allowing the model more flexibility but also raising the risk of overfitting. In practice, we tune lambda (or in many software libraries, the parameter C which is 1/lambda) through cross-validation.
There are other ways to reduce overfitting in logistic regression:
Limiting the number of features. By performing feature selection or dimensionality reduction techniques, you can remove noisy or redundant features. This can significantly reduce overfitting, especially when dealing with high-dimensional data.
Gathering more data. Obtaining additional samples can help logistic regression generalize better. This approach, however, is often expensive or sometimes not feasible in practice.
Cross-validation. Splitting the dataset into multiple folds helps in reliably estimating how well the model generalizes and tuning hyperparameters like lambda or C for optimal performance without overfitting to any single training set.
Early stopping. When training models with iterative solvers (like gradient descent or stochastic gradient descent), monitoring the validation performance and halting the training once validation performance stops improving can act as a practical way to avoid overfitting.
Data augmentation. Although data augmentation is more common in domains like computer vision, any domain that supports meaningful augmentation of samples can benefit from generating additional data points to reduce overfitting.
How does L1 regularization differ from L2 in preventing overfitting?
L1 regularization (Lasso) uses an absolute value penalty on the coefficients. This penalty tends to drive some coefficients to exactly zero, thereby performing built-in feature selection. By forcing many coefficients to zero, it discards less informative features. This can help reduce overfitting by effectively simplifying the model. However, in some settings, L1 might not be as stable when correlated features exist because it can pick one arbitrarily and push others toward zero.
L2 regularization (Ridge) uses a sum of squared coefficients penalty. It shrinks the coefficients smoothly rather than driving them to zero. This often leads to more stable coefficient estimates when features are correlated. However, it does not inherently produce sparse solutions, so it is more about coefficient shrinkage than explicit feature elimination.
Why does logistic regression still overfit despite being a linear model?
Even though logistic regression assumes a linear decision boundary in feature space, it can have many parameters when the number of features is large or when polynomial or other nonlinear transformations of features are introduced. If the training set is small or not representative, the model parameters can be tuned to fit noise. This risk grows if you allow the solver to run too many iterations without any form of penalty or early stopping, or if you add numerous interactions or polynomial terms without regularization.
How do you typically tune regularization strength in practice?
In many Python libraries like scikit-learn, the logistic regression class has a parameter C, which is the inverse of the regularization strength. A smaller C means stronger regularization. To find a balanced setting of C, you can employ cross-validation on the training set. By measuring performance across multiple folds, you get a more robust estimate of the best value of C. This process often involves searching over a range of C values, typically on a logarithmic scale, and selecting the one that yields the highest cross-validation accuracy or another performance metric while avoiding overfitting.
In what scenarios might logistic regression overfitting be harder to detect?
When you do not have a robust validation or test set, overfitting can go unnoticed because you might see a low training error but no unbiased measurement of generalization error. Alternatively, if you have severe data leakage (where information from the validation or test set inadvertently influences the training process), the model might appear accurate even though it is memorizing patterns that will not hold in truly unseen data.
Do outliers affect overfitting in logistic regression, and how do we handle them?
Logistic regression can be susceptible to outliers because large deviations in feature values can push coefficients to fit those extreme cases. This risk is heightened when lambda is small or C is large, because the regularization penalty is not strong enough to constrain the influence of those outliers. A common approach is to apply data pre-processing such as outlier removal or robust scaling so that extreme values have less impact, or to use a more robust loss function if available.
Could feature engineering accidentally increase overfitting in logistic regression?
Yes. Feature engineering can introduce a large number of candidate features, especially if you generate polynomial or interaction terms. Each additional feature provides more parameters that the model can adjust to learn details from the training set, potentially fitting noise. Appropriate regularization, careful cross-validation, and domain knowledge regarding which features are actually relevant all help guard against excessive feature engineering that leads to overfitting.
What are practical tips for implementing logistic regression in Python?
In libraries such as scikit-learn, you can instantiate a regularized logistic regression model as follows:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
X_train, X_val, y_train, y_val = # your data split
# Parameter C is the inverse of regularization strength (1 / lambda).
param_grid = {'C': [0.01, 0.1, 1, 10, 100]}
lr = LogisticRegression(penalty='l2', solver='lbfgs', max_iter=10000)
grid_search = GridSearchCV(estimator=lr, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)
print("Best parameters:", grid_search.best_params_)
print("Validation accuracy:", grid_search.best_score_)
It is important to scale features if they vary in magnitude to ensure that the regularization penalty treats all features in a uniform way. This process commonly involves applying standardization or min-max normalization. Additionally, keep a final hold-out test set to check for overfitting after parameter tuning.