
ML Interview Q Series: Why can Euclidean distance become problematic in high-dimensional data when applying clustering methods?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
One reason Euclidean distance performs poorly in very high dimensions is the so-called curse of dimensionality, which indicates that data points tend to become almost equidistant from each other as dimensionality grows. The distances lose their discriminative power, making it challenging for clustering algorithms to discern meaningful structure. The phenomenon can lead to most pairwise distances appearing nearly the same, which in turn obscures the separation between clusters.
The mathematical form of Euclidean distance between two points x and y in a d-dimensional space is a key representation:
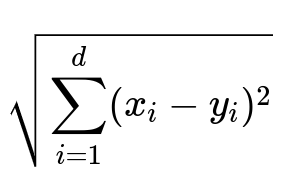
x_i represents the i-th component of the point x, y_i represents the i-th component of the point y, and d is the dimensionality of the feature space.
As d grows larger, each coordinate difference (x_i - y_i) may contribute noise-like effects, and even if each dimension provides only a small variance, the accumulated effect over many dimensions can diminish the contrast between distances. This is why Euclidean distance becomes less reliable for identifying clusters in high-dimensional spaces.
Additionally, the clustering algorithms that rely on Euclidean distance as a measure of similarity (such as k-means, which heavily uses the concept of means and pairwise distances) struggle with the problem that centroids and distance-based assignments become less meaningful when every point is roughly as far away from every other point.
Methods to mitigate this include dimensionality reduction (for instance, Principal Component Analysis) and using distance metrics that are more robust to high-dimensional properties (such as cosine similarity or Manhattan distance in some cases), although even these can face difficulties depending on the structure and scale of the data.
Common Pitfalls and Practical Considerations in High Dimensionality
Many practitioners still attempt to use purely distance-based clustering in high-dimensional domains without applying feature selection, dimensionality reduction, or more specialized algorithms. This often leads to poor performance. It is essential to either reduce dimensions or adopt algorithms specifically designed to handle sparse and high-dimensional data to avoid misleading clustering results.
Follow-up Questions
What does it mean for distances to "concentrate" in high dimensions?
Distance concentration refers to the observation that in high-dimensional spaces, the ratio between the smallest distance and the largest distance among pairs of points approaches 1. When most points lie roughly at a similar distance from one another, it undermines the effectiveness of distance-based methods. This occurs because each dimension adds a potential source of variation, spreading points further apart in an absolute sense, yet causing relative distances to converge.
In simpler terms, if you compute all pairwise distances, you might find that the minimum distance is not much smaller than the maximum distance, implying a lack of contrast. Because clustering algorithms rely on relative differences in distances, concentrated distances impair the ability to tell which points form coherent groups.
Are there alternative distance metrics or similarity measures that work better in high dimensions?
Some measures can be less sensitive to the expansion in high-dimensional space, such as cosine similarity. Cosine similarity looks at the angle between vectors rather than their absolute magnitude, which can help reduce some high-dimensional artifacts. Manhattan distance (L1 norm) sometimes exhibits more stability than Euclidean distance (L2 norm) for certain data distributions. However, none of these metrics provide a complete cure for all high-dimensional challenges. It is often necessary to combine carefully chosen metrics with dimensionality reduction or feature selection methods to restore meaningful structure.
How can dimensionality reduction assist in clustering high-dimensional data?
Dimensionality reduction helps by projecting the original data onto a lower-dimensional subspace that attempts to preserve the most important variance or structure. Methods like Principal Component Analysis, t-SNE, or UMAP can compress the data while hopefully retaining cluster-relevant patterns. After reduction, distance metrics like Euclidean distance regain their interpretability in the lower-dimensional embedding. However, one must keep in mind that the projection could lose potentially relevant information; for instance, components that do not explain a large portion of variance might still contain subtle but important signals for clustering.
Does the curse of dimensionality apply to all high-dimensional data?
The curse of dimensionality is typically discussed in the context of data that is not extremely sparse or structured in a low-dimensional manifold. If the data inherently lies on a lower-dimensional manifold or has a structure that can be exploited (for instance, many features are correlated), then effective techniques (feature selection, manifold learning) can circumvent some of these issues. Conversely, if the data dimensions are all meaningful and uncorrelated, clustering becomes much more difficult.
What role does normalization or scaling play in high-dimensional clustering with Euclidean distance?
Normalization or scaling each feature can mitigate some high-dimensional effects by ensuring that all features contribute roughly equally. Without normalization, features on large scales dominate the distance measure, overshadowing variation in smaller-scale dimensions. However, even with scaling, once dimension grows sufficiently large, the phenomenon of distances converging can still occur. Hence, normalization is a helpful step but does not completely solve the underlying problem.
When is it appropriate to still use Euclidean distance in high dimensions?
If exploratory analysis shows that your data exhibits strong cluster separation in fewer dimensions, or if a prior feature selection process leaves you with a moderate number of features, Euclidean distance remains perfectly valid. It is also commonly used in methods like PCA-based pipelines: first reduce the dimensionality, then apply Euclidean-distance-based clustering. In situations where you have a known low-dimensional structure within your data, or you have domain-specific reasons to believe Euclidean geometry is appropriate, continuing with Euclidean distance may be justified.
Example: Implementing a Check on Euclidean Distances in Python
import numpy as np
# Imagine we have N data points each of dimension D
N, D = 1000, 100
data = np.random.randn(N, D) # random normal distribution
# Compute Euclidean distances to the first data point
# Notice how they might not show large variability as D grows
distances = np.sqrt(((data - data[0]) ** 2).sum(axis=1))
# Observe the standard deviation of distances
std_of_distances = distances.std()
print("Mean distance:", distances.mean())
print("Standard deviation of distances:", std_of_distances)
In very high-dimensional settings (e.g., D=1000 or more), it is common to see a small standard deviation compared to the mean distance, illustrating that distances are becoming more or less similar to each other.
Such practical checks help diagnose if you are running into the distance concentration effect, guiding you to adopt appropriate strategies like dimensionality reduction or alternative similarity measures.