
ML Interview Q Series: Why does stacking multiple models often lead to better predictive performance?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Model stacking, frequently called stacked generalization, involves training multiple base learners (such as different algorithms or different hyperparameter configurations of the same algorithm) and then using a meta-learner to combine their outputs. The fundamental idea is to exploit the strengths of each individual model and mitigate their respective weaknesses, thereby boosting overall performance. Below is a concise way of looking at how a simple linear meta-learner might combine predictions from M base models:
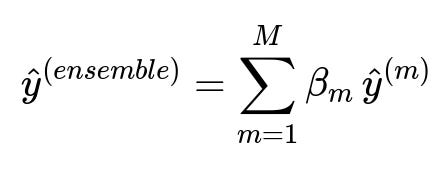
Where m represents the index of the base model (from 1 to M), beta_{m} represents the weight or coefficient assigned to the m-th base model by the meta-learner, and hat{y}^{(m)} indicates the prediction of the m-th base learner.
In practice, the meta-learner itself can be any model (e.g., a linear regressor, a neural network, or even a more sophisticated ensemble). The following points explain why this approach improves performance:
Synergy of Models Different base learners often capture different patterns or aspects of the data. Some models might fit global trends well (like linear models), while others might capture more localized complexity (like tree-based ensembles). By stacking these learners, the meta-learner can learn to trust each base model in regions where it performs best.
Reduced Bias and Variance Model stacking tends to reduce both bias and variance. If a particular base model is biased in some region, others can compensate for it if they have different biases or lower error in that region. In addition, combining multiple models often leads to variance reduction because it averages out individual fluctuations or overfitting behavior.
Leveraging Out-of-Fold Predictions In a typical stacking procedure, you generate out-of-fold predictions from each base model. That means you train each base model on a training fold, then produce predictions on a hold-out fold that the meta-learner uses as “features” to learn how to best combine them. This process helps prevent overfitting because the meta-learner sees how each base model genuinely performs on unseen data.
Flexibility in Choices Stacking is model-agnostic. You can use gradient boosting, random forests, neural networks, or even specialized models like support vector regressors/classifiers for your base learners. As long as each model provides complementary information, stacking can leverage that diversity.
Ability to Capture Complex Interactions If your meta-learner is complex (for instance, a neural network), it can detect non-linear interactions among the predictions of the base models. This capacity allows the final ensemble to be more expressive than a simple average of predictions.
Practical Considerations Model stacking can be computationally expensive if you have many base models and a large dataset. Cross-validation used for generating base-model predictions also increases overhead. Despite these concerns, the performance gains are often significant in practice, especially for competitions or high-stakes applications.
Follow-Up Questions
What strategies are commonly used to avoid overfitting in model stacking?
One robust strategy is to perform out-of-fold predictions correctly. You partition your training set into K folds, train each base model on K-1 of the folds, and then generate predictions on the left-out fold. This ensures that the meta-learner’s training data consists of predictions made on unseen data, reducing the risk of overfitting to the training set. Another strategy is to regularize the meta-learner itself (e.g., by using L2 regularization if it is a linear model, or other forms of regularization if it is a neural network). You should also keep an eye on your hyperparameters in the base models to make sure they do not overfit too aggressively.
Are there any downsides to stacking too many models?
Yes. The main issue is computational cost. Each additional model adds to training time, memory usage, and complexity. Furthermore, if many of the models are highly correlated or if they are not sufficiently diverse (e.g., all are the same algorithm with similar hyperparameters), the marginal gain in performance from adding more models can be negligible or even detrimental. It is also harder to debug or interpret a more extensive stacked system, especially if explainability is a requirement.
How can we implement stacking in Python?
Below is a minimal example using scikit-learn’s StackingClassifier or StackingRegressor. Suppose we want to stack a random forest and a gradient boosting model for classification, then use logistic regression as the meta-learner:
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load example data
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define base learners
base_learners = [
('rf', RandomForestClassifier(n_estimators=50, random_state=42)),
('gb', GradientBoostingClassifier(n_estimators=50, random_state=42))
]
# Define meta-learner
meta_learner = LogisticRegression()
# Create the Stacking Classifier
stacked_model = StackingClassifier(
estimators=base_learners,
final_estimator=meta_learner,
passthrough=False # set to True if you want to pass original features to meta-learner too
)
# Train the stacked model
stacked_model.fit(X_train, y_train)
# Evaluate performance
score = stacked_model.score(X_test, y_test)
print(f"Stacked model accuracy: {score:.4f}")
In this example, two base learners (random forest and gradient boosting) are trained, and a logistic regression model combines their predictions. The StackingClassifier automatically handles the workflow of fitting the base models and using out-of-fold predictions to train the meta-learner.
What if the meta-learner overfits?
Overfitting of the meta-learner is a valid concern, especially if the meta-learner is highly flexible (e.g., a deep neural network). One way to mitigate this is to apply regularization techniques. Another is to be sure that your out-of-fold prediction scheme is robust. Using nested cross-validation for the stacking process is also a rigorous method. You can even apply additional data augmentation steps or adopt early stopping to manage overfitting in complex meta-learners.
Is there any scenario where stacking might not help?
If your dataset is small, the benefits of stacking might be limited because each base model already has limited data to train on, and out-of-fold predictions shrink the available training data further. If your models are all very similar or do not capture distinct aspects of the data, stacking might yield little to no improvement. In cases where interpretability is paramount, the complexity of stacking might be a drawback as well.
Can we stack multiple layers (i.e., do a deeper stack)?
Yes. You can build multi-layer stacking architectures where the output of one layer of stacking becomes the input to the next layer. However, each added layer typically requires even more careful data partitioning to avoid leakage. This approach can be incredibly powerful but can also be significantly more difficult to manage and tune, so it is often reserved for highly competitive tasks (e.g., Kaggle competitions) where every fraction of performance gain matters.
Are there theoretical guarantees for stacking’s performance improvements?
Analytically proving performance bounds for stacking can be challenging because it depends on the bias-variance characteristics of base models, how well they complement each other, and the complexity of the meta-learner. Nevertheless, ensemble methods in general have solid theoretical underpinnings in terms of variance reduction and error decomposition. Stacking in particular relies on the idea that a meta-level mapping from base predictions to final prediction can approximate an “ideal aggregator,” given enough training data and sufficiently diverse base learners.