
ML Interview Q Series: Why don't we use Mean Squared Error as a cost function in Logistic Regression?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
One key property of logistic regression is that it predicts a probability for the positive class by passing a linear combination of the inputs through a logistic function (often called the sigmoid function). This probability is then used with the binary cross-entropy (also referred to as the negative log-likelihood) as the cost function. Mean Squared Error (MSE) appears in many regression tasks, but it does not align well with the probabilistic interpretation of logistic regression for several reasons.
Undesirable Shape of Error Surface
When we use MSE with the logistic (sigmoid) activation, the resulting error surface with respect to the parameters can become non-convex, making it more challenging for gradient-based optimization methods to converge to a global optimum. In contrast, the typical cross-entropy cost function is convex in terms of the parameters for many settings, or at least tends to produce a single, well-defined global optimum from the perspective of optimization.
Mismatch with Probability Interpretation
Logistic regression interprets the model outputs as probabilities. Cross-entropy aligns with the maximum likelihood principle when modeling binary outcomes. It punishes large deviations in predicted probabilities much more heavily, which is exactly what we want: if an event is very likely (or unlikely), the cost function should strongly penalize a misprediction. MSE does not capture this probabilistic fidelity and can lead the model to produce output probabilities near 0.5 even when the correct class is strongly favored.
Gradient Saturation
Using MSE for logistic regression can lead to gradient saturation. The logistic function saturates for large positive or negative inputs, and if we combine that with MSE, the gradient can become very small. This effectively slows training because updates to parameters become negligible. Cross-entropy, on the other hand, creates stronger gradients when the prediction is wrong, driving faster and more stable convergence.
Mathematical Expressions
Below is the Mean Squared Error (MSE) formula in a classification setting with logistic outputs, to highlight why it is typically avoided for logistic regression:
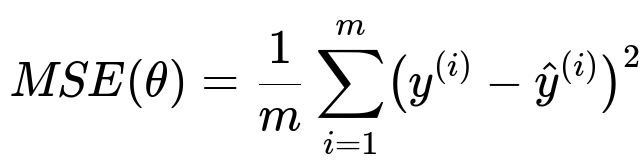
Where m is the number of training examples, y^(i) in text is the true label for sample i, and hat{y}^(i) in text is the predicted probability for sample i. This form is problematic in logistic regression because it implicitly treats the output as a continuous label and does not reflect the true likelihood-based objective for a Bernoulli variable.
In contrast, logistic regression naturally uses the binary cross-entropy loss, often written as:
This cost function emerges directly from maximizing the likelihood of the observed data under a Bernoulli distribution assumption. By using the log of the predicted probability, we heavily penalize confident but incorrect predictions (where the model predicts a probability close to 1 but the label is 0, or vice versa), and we allow for larger gradients when the model is wrong.
Practical Illustration in Python
Below is a simplified snippet showing logistic regression in PyTorch, where binary cross-entropy is used instead of MSE:
import torch
import torch.nn as nn
import torch.optim as optim
# Example dataset (X: [features], y: [labels 0 or 1])
X = torch.randn(100, 3)
y = torch.randint(0, 2, (100,)).float()
# Logistic Regression Model
model = nn.Sequential(
nn.Linear(3, 1),
nn.Sigmoid()
)
# Binary Cross-Entropy Loss
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Training loop
for epoch in range(100):
optimizer.zero_grad()
outputs = model(X).squeeze()
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
print("Final Loss:", loss.item())
In this code, we use BCELoss, which implements binary cross-entropy. Using MSELoss instead would often lead to slower convergence and poorer probabilistic calibration in the context of a binary classification problem.
Why MSE Can Still Appear in Practice
Although theoretically suboptimal, sometimes you may see MSE used in simpler or academic contexts for logistic outputs. But for large-scale problems, the gradient issues and mismatch with the log-odds interpretation make it a poor choice compared to cross-entropy.
What Happens if You Try to Use MSE in Logistic Regression
The model can still converge, but it often requires more careful tuning of learning rates. It might converge to suboptimal parameter values, and you lose the straightforward probability interpretation that results from log-likelihood–based training. In advanced scenarios, you might also get overshadowed by other complexities like regularization, but MSE rarely remains the best approach given the theoretical and practical alignment of cross-entropy with logistic regression’s probabilistic framework.
Potential Follow-up Questions
Could we theoretically still minimize MSE and get some good results?
Yes, you might get decent classification accuracy in simple or small-scale settings. However, this approach is less stable in training, does not produce well-calibrated probabilities, and is generally slower to converge. From a theoretical and practical standpoint, cross-entropy is superior because it directly arises from the maximum likelihood principle.
Why is cross-entropy more appropriate from a probabilistic standpoint?
Cross-entropy is essentially the negative log-likelihood under the assumption that the labels come from a Bernoulli distribution. Logistic regression posits that log( p/(1-p) ) is linear in the input features. The cross-entropy loss perfectly corresponds to maximizing the probability of the correct class under this assumption, ensuring well-calibrated probabilities and efficient training gradients.
Do we face the same issue with MSE in other classification algorithms?
Yes, whenever an algorithm is outputting probabilities for a categorical variable, MSE is usually a poorer fit than a log-likelihood–based cost. In neural networks for binary classification, for instance, we typically use binary cross-entropy, and for multi-class classification, we use categorical cross-entropy.
Are there any cases where MSE is used for classification tasks effectively?
MSE might be used for tasks where interpretability of the output as a direct probability is not critical, or in certain approximation scenarios. However, those are exceptions rather than the norm. If the goal is to have well-calibrated probabilities and stable optimization, cross-entropy is almost always preferred for classification tasks.
Below are additional follow-up questions
How does using MSE for logistic regression affect the decision boundary?
The decision boundary in logistic regression is determined by the point at which the predicted probability equals 0.5. When we use cross-entropy, the gradient updates push the logistic function’s parameters in a manner consistent with maximizing the log-likelihood for correctly assigning a label. In contrast, using MSE tries to reduce the squared difference between predicted and actual labels (0 or 1), which does not directly match the shape of the logistic function’s log-odds.
One subtle outcome is that training with MSE can cause the parameters to shift less aggressively when the model is making a highly confident but incorrect prediction. The squared error in that scenario may provide a smaller gradient than cross-entropy would, where the penalty for a wrong prediction near probability 1.0 (or 0.0) is extremely large. This can lead to a decision boundary that is not as sharply optimized for classification tasks and can be slower to converge to the region that best separates the classes.
What are the implications of using MSE with logistic regression for interpretability of coefficients?
Logistic regression traditionally has a direct link between coefficients and log-odds. When you use maximum likelihood with cross-entropy, each coefficient corresponds to how much it contributes to the log( p/(1-p) ), where p is the predicted probability. This interpretation helps analysts understand which features most increase or decrease the odds of a positive class.
When MSE is used instead, the interpretability of these coefficients in a probabilistic sense becomes muddled. Although the learned coefficients might still form a decision boundary, they no longer have a clean log-odds interpretation that helps with feature importance and effect-size understanding. This decreases the direct explanatory power of the model, which can be a major drawback in domains such as healthcare, finance, or any other setting where understanding why the model made a certain decision is crucial.
Can MSE in logistic regression lead to different local minima compared to cross-entropy?
Cross-entropy, when applied to logistic regression, often has a single global optimum in terms of log-likelihood (although in high-dimensional spaces there can be practical optimization challenges). However, when MSE is used, the error surface can introduce more complex curvature. Specifically, the gradients can be flat or even misleading in certain regions where the logistic function saturates. This might lead to different local minima or a much slower convergence that can trap the model in a suboptimal region.
In practice, it is not guaranteed that MSE always results in multiple local minima for logistic regression, but the shape of its error surface is less naturally aligned with the sigmoid curve than cross-entropy. This misalignment often manifests as slower or more erratic training dynamics, rather than a clean funnel-shaped landscape toward the global optimum.
Does the cross-entropy function remain convex in all scenarios for logistic regression?
Strictly speaking, the cross-entropy loss is convex with respect to the model’s logits (the linear combination of parameters and inputs), but not necessarily convex in the full, high-dimensional parameter space once the sigmoid is applied. Still, in practice, cross-entropy provides a more well-behaved and tractable optimization objective for logistic regression than MSE.
The partial or near-convexity of cross-entropy is a crucial advantage for gradient-based optimization. Even though true global convexity in parameter space might not hold under every scenario, the gradient signals from cross-entropy tend to be much sharper and more informative than those from MSE, leading to more stable convergence in real-world optimization tasks.
What if the dataset is heavily imbalanced? Does this further widen the gap between MSE and cross-entropy performance?
In highly imbalanced classification, cross-entropy focuses on correctly adjusting probabilities to reflect the actual likelihood of the minority class. It can heavily penalize confident yet incorrect predictions, which is crucial for the underrepresented class.
MSE, however, might treat errors for the majority class and the minority class in a somewhat uniform way. Because the model sees far more samples of the majority class, it may minimize overall squared error by predicting probabilities near the majority label’s distribution. In other words, it can amplify the bias toward the majority class, resulting in poorer minority-class recall. Thus, an imbalanced dataset often exacerbates the problems with MSE, making cross-entropy’s strong gradient signals even more beneficial for ensuring the model pays adequate attention to minority examples.
Are there any numerical or computational challenges in frameworks like PyTorch if we tried MSE instead of cross-entropy for logistic regression?
When using standard frameworks (e.g., PyTorch, TensorFlow), the built-in logistic regression or binary classification layers typically assume cross-entropy. If you forcibly use MSE, you could run into:
• Gradient underflow or overflow: In certain ranges of parameter values, the logistic function can saturate. MSE combined with very saturated probabilities can yield very small or unstable gradients. • Convergence instability: The learning rate may need to be tuned meticulously. With MSE, the gradient might be too small in the saturated regions, causing training to stall or be highly sensitive to minor initialization changes. • Difficulty in measuring classification metrics: Because MSE is not directly tied to a probability-based measure, intermediate metrics like log-likelihood or perplexity do not naturally arise. You would likely track accuracy or F1-score, but the training objective itself is not as closely aligned with optimizing those metrics as cross-entropy is.
If we had a perfect classifier, how would MSE vs. cross-entropy respond?
A perfect classifier assigns a probability of 1.0 (or very close) to the correct class and 0.0 to the incorrect class. With cross-entropy, the cost would approach zero in that scenario, as there would be almost no negative log-likelihood term.
With MSE, the cost similarly approaches zero because the squared difference between the predicted probabilities (1 or 0) and true labels (1 or 0) is zero. However, the path to get there is typically more direct with cross-entropy, which provides strong gradient feedback during training. MSE’s gradient would be smaller in regions where the model is “almost correct,” so even though both cross-entropy and MSE converge to near-zero for a perfect classifier, cross-entropy tends to lead there more efficiently.
Could we adapt MSE to behave more like cross-entropy through weighting?
One might consider weighting the errors differently for different predicted probabilities to compensate for MSE’s weaker gradient. For instance, one could try to inflate the penalty for wrong predictions when the model is confident (e.g., predicted probability close to 1 for the wrong class). Although there are such heuristic approaches, they essentially approximate parts of the cross-entropy loss. This reaffirms that cross-entropy natively captures the behavior we want: strong penalties for incorrect high-confidence predictions. The more you tune MSE with weighting schemes, the more it ends up looking like a variant of cross-entropy in practice.
What if we are not strictly interested in probability outputs but only in the classification decision?
Even if the end goal is just to classify (positive vs. negative) without needing a probability, cross-entropy typically converges to a better linear boundary for logistic regression. This is because cross-entropy’s gradient encourages the log-odds to move rapidly toward the correct class in the event of a misclassification. MSE doesn’t enforce that log-odds boundary as strongly, which can lead to decision boundaries that are slower to become well separated.
Hence, even when probabilities are not the final outcome of interest, cross-entropy remains advantageous for quicker, more stable, and better classification performance.