
ML Interview Q Series: Why is it often preferable to rely on Singular Value Decomposition instead of just using Eigendecomposition?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Singular Value Decomposition (SVD) is a powerful factorization method that decomposes any real (or complex) rectangular matrix into three components. By contrast, Eigendecomposition (EVD) requires certain square matrices with specific properties (e.g., symmetry in the real case) to be diagonalizable. Because SVD applies more generally and provides a meaningful decomposition even for non-square matrices, it is extremely valuable in practical machine learning and data science applications.
SVD in Its Core Form
Here is the core mathematical formulation for SVD. For any real matrix A of size m x n, we can factorize it into three matrices:
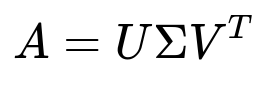
where:
A is the original m x n matrix (not necessarily square).
U is an m x m orthogonal matrix (meaning U^T U = I_m).
Sigma is an m x n diagonal-like matrix (often with zeros off the main diagonal); its non-zero diagonal entries are the singular values of A.
V is an n x n orthogonal matrix (meaning V^T V = I_n).
V^T is the transpose of V.
The singular values in Sigma are real and non-negative. They are arranged in descending order. The columns of U are the left-singular vectors, and the columns of V are the right-singular vectors.
Differences from Eigendecomposition
Eigendecomposition in its usual form applies to a square matrix A (n x n) that often needs to be diagonalizable (and for real symmetric matrices, we get an orthogonal eigendecomposition A = Q diag(lambda) Q^T). When a matrix is not square or is not diagonalizable under certain conditions, you cannot directly use EVD in the standard sense. Even for square matrices that are not symmetric, the EVD might involve complex eigenvalues or might not exist in a nicely diagonalizable form. SVD sidesteps these constraints by working with any rectangular real (or complex) matrix, guaranteeing a factorization into orthogonal (or unitary) factors and non-negative singular values.
Why We Use SVD in Machine Learning
Dimensionality Reduction: Techniques like Principal Component Analysis (PCA) use SVD to project data onto a lower-dimensional space while capturing the most variance. SVD is more stable numerically than some direct EVD methods, especially when dealing with rectangular data matrices.
Noise Filtering and Denoising: When data is noisy or incomplete, focusing on the largest singular values and their corresponding singular vectors can reveal the most informative components.
Matrix Approximations: Truncated SVD offers the best low-rank approximation under the Frobenius norm. This is key to efficient data compression, latent semantic analysis in natural language processing, and collaborative filtering in recommender systems.
Existence and Uniqueness: SVD always exists for any real or complex matrix, regardless of shape. Eigendecomposition, on the other hand, requires more specific conditions.
Stability: Algorithms that compute SVD are usually quite stable and robust to numerical issues. They are well-established in linear algebra libraries and are often more reliable than computing eigenvalues and eigenvectors for very large or ill-conditioned matrices.
Practical Considerations
SVD tends to be more computationally expensive than some forms of EVD for very large matrices. However, many optimized algorithms (e.g., randomized SVD) can handle large-scale problems more efficiently than naive methods.
In many ML pipelines, data matrices are tall (more rows than columns) or wide (more columns than rows), making SVD the natural go-to technique.
The singular values provide a direct measure of the energy or importance of corresponding singular vectors (dimensions), which is particularly convenient for rank selection and regularization.
Follow-up Questions
How does SVD handle rectangular matrices compared to EVD?
EVD is typically defined for square matrices. It relies on the idea of diagonalizing a matrix or putting it in some canonical form that depends on eigenvalues and eigenvectors. If your data matrix is not square, then EVD cannot be directly applied. By contrast, SVD factorizes a rectangular matrix into U, Sigma, and V^T. This is extremely useful when dealing with data tables that are m x n, which is the usual scenario in many real-world applications (e.g., more data points than features or more features than data points).
What makes the singular values so important for dimensionality reduction?
Singular values in Sigma appear in descending order, reflecting how much “energy” or variance is captured by each corresponding singular vector. In tasks like PCA, we might only keep the largest singular values and their vectors to form a low-rank representation. By doing so, we filter out directions in the data that contribute relatively little to the overall variance, effectively removing noise or redundant dimensions. This makes SVD crucial for compressing data or extracting the most informative dimensions.
Can we interpret the left and right singular vectors similarly to eigenvectors?
Yes, with some nuance. The left-singular vectors (columns of U) represent orthonormal directions in the original m-dimensional space, showing how the rows of the matrix align with principal components. The right-singular vectors (columns of V) represent orthonormal directions in the n-dimensional feature space. They can be interpreted much like eigenvectors in that they provide a basis where the matrix has a particularly simple “diagonal” structure (the Sigma matrix). However, they do not necessarily relate to “eigenvalues” of A directly; instead, the singular values are the square roots of the eigenvalues of A^T A (or A A^T).
What is the computational complexity comparison of SVD vs. EVD?
For a dense n x n matrix:
A full SVD typically has a complexity of O(n^3).
An EVD for a symmetric matrix has a similar cost, also on the order of O(n^3).
For m x n matrices with m >> n or n >> m, specialized algorithms can compute the SVD in O(min(m,n)^2 * max(m,n)). In practice, if you need a small subset of singular values, you can use approximate or randomized SVD methods, which significantly reduce the computation time while retaining high accuracy. EVD for non-square matrices is not directly applicable in its standard form, so comparing them directly may not always make sense unless you are dealing with a square matrix.
Where do we see SVD commonly applied in deep learning frameworks?
In deep learning, SVD appears in:
Weight Regularization: One can regularize by bounding the singular values of weight matrices to improve generalization or stability.
Compression of Trained Networks: Truncating the SVD of large weight matrices can reduce parameter count without drastically harming performance.
Initialization or Factorization: Some layers can be factorized using SVD-like methods to reduce dimensionality and computational load.
Understanding Internal Representation: Examining the singular values of internal activations can reveal if layers or sub-networks have rank deficiencies or are overfitting.
These practical benefits, along with SVD’s guaranteed existence for any shape of matrix, explain why SVD is often more versatile than traditional eigendecomposition methods for many machine learning applications.