
ML Interview Q Series: Why is K-Means often characterized by higher bias than Gaussian Mixture Models?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
K-Means and Gaussian Mixture Models (GMM) are both widely used clustering algorithms, but they rely on different underlying assumptions. K-Means tries to minimize the sum of squared distances to the cluster centroids (hard assignments), whereas GMM models the data as a mixture of Gaussians (soft assignments). The stricter assumptions of K-Means lead to a higher bias compared to the more flexible Gaussian Mixture Model.
Core Objectives
K-Means
K-Means attempts to find K cluster centroids that minimize the overall variance within clusters. This can be mathematically expressed as:
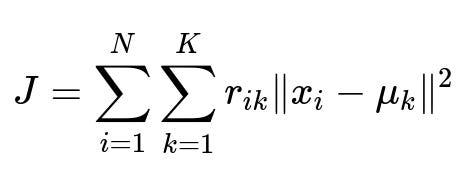
Here:
x_i refers to the i-th data point in d-dimensional space.
mu_k is the centroid (mean) of cluster k.
r_{ik} is 1 if x_i belongs to cluster k, and 0 otherwise.
N is the total number of data points.
K is the predefined number of clusters.
Because K-Means uses Euclidean distance to assign each point to exactly one cluster, it effectively imposes a spherical shape assumption around each centroid with no explicit modeling of cluster covariance. This simple geometric constraint restricts its flexibility, leading to potentially higher bias if the real data distribution does not resemble equally sized spheres.
Gaussian Mixture Model
A Gaussian Mixture Model posits that data points are generated from a mixture of multiple Gaussian distributions. The mixture density function is:

Here:
x is a data point.
pi_k is the mixing coefficient (non-negative, sums to 1) for the k-th Gaussian component.
mu_k is the mean of the k-th Gaussian component.
Sigma_k is the covariance matrix of the k-th Gaussian component.
K is the total number of mixture components.
Because GMM includes the covariance matrices, it can adapt to elliptical clusters of varying shape and orientation. This additional flexibility in modeling cluster shapes and overlaps generally reduces bias relative to K-Means, while possibly increasing variance due to a larger number of parameters.
Why K-Means Has Higher Bias
Rigid Assumption: K-Means effectively assumes clusters are spherical and that all dimensions contribute equally. This strong assumption simplifies the model but increases bias if the true clusters are not spherical or equally sized.
Hard Assignments: K-Means assigns each data point to one single cluster with a strict boundary. This can force borderline points that naturally belong in multiple overlapping regions into a single cluster, making the model less expressive.
No Covariance Modelling: Unlike GMM, K-Means does not learn different shapes or orientations for clusters. The limited shape flexibility typically makes the model more biased, since it won't capture data distributions that are elongated or skewed.
Illustrative Code Snippet in Python
import numpy as np
from sklearn.cluster import KMeans
from sklearn.mixture import GaussianMixture
# Synthetic dataset
X = np.random.rand(500, 2)
# K-Means Clustering
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans_labels = kmeans.fit_predict(X)
# Gaussian Mixture Model
gmm = GaussianMixture(n_components=3, random_state=42)
gmm_labels = gmm.fit_predict(X)
print("K-Means Centroids:", kmeans.cluster_centers_)
print("GMM Means:", gmm.means_)
print("GMM Covariances:", gmm.covariances_)
In this code snippet, K-Means only outputs cluster centroids, whereas GMM additionally learns the covariance matrices for each mixture component.
What circumstances make K-Means perform better despite its higher bias?
Even though K-Means has higher bias, it can still outperform GMM under certain conditions. When clusters are well-separated, roughly spherical, or the dataset is very large, K-Means often converges faster and is simpler to implement. When the dimensionality is extremely high and the user suspects the clusters to be mostly spherical, K-Means can be highly effective and computationally more scalable.
How does the difference in hard versus soft assignments influence clustering outcomes?
K-Means uses a hard assignment, which places each sample into exactly one cluster according to the nearest centroid. This works well when cluster boundaries are distinct and data points clearly belong to one group. However, when clusters overlap or a data point may plausibly belong to multiple groups, GMM’s soft assignment provides a probability for each cluster membership. This soft assignment approach can often capture more nuanced boundaries in the data.
How do initialization methods affect K-Means and GMM?
Both K-Means and GMM are sensitive to initial conditions:
K-Means: Commonly initializes centroids via random selection or algorithms like k-means++ to spread out initial seeds. Poor initialization may lead to suboptimal local minima.
GMM: Often uses K-Means for initial mean assignments before learning the full model via Expectation-Maximization. GMM also needs initial guesses for covariances and mixing coefficients. Random initializations can lead to differing local optima.
In practice, multiple random restarts are tried for both algorithms to mitigate the chance of converging to suboptimal solutions.
When would you prefer GMM over K-Means in a real-world project?
You might prefer GMM when:
You suspect clusters are elliptical or vary in size and covariance structure.
You want a probabilistic membership assignment, which can be beneficial in scenarios where data points are not clearly partitioned into distinct groups.
You are dealing with data that might have overlapping clusters, and you need to express those overlaps in your model for interpretability (e.g., soft membership scores).
Can GMM suffer from higher variance compared to K-Means?
Yes, because GMM estimates additional parameters such as covariances and mixing coefficients, it may overfit small datasets or noisy data. This results in higher variance. Regularization techniques (e.g., tying or constraining covariance matrices) and larger datasets can help mitigate the risk of overfitting.
How do you handle the number of clusters for both algorithms?
For both K-Means and GMM, the user typically provides the number of clusters (or mixture components) K in advance. Common strategies to find a good K include:
Elbow method: Examine how the sum of squared errors (for K-Means) or negative log-likelihood (for GMM) changes as K increases.
Silhouette score: Evaluate clustering coherence versus separation.
Information criteria (e.g., AIC, BIC) for GMM: Penalize models that use too many parameters, thus providing a balanced approach to selecting K.
Choosing the right K is crucial since an inappropriate choice can lead to underfitting (too few clusters) or overfitting (too many clusters).
What if the data contains outliers?
K-Means: Sensitive to outliers because squared distance magnifies the impact of extreme data points. A single outlier can significantly shift the centroid.
GMM: Also influenced by outliers, but if covariances are allowed to adapt, it might partially mitigate the effect of outliers by assigning them lower probability in any component. However, extreme outliers can still skew the estimation of means and covariances.
In practice, data preprocessing, robust initialization, or outlier detection methods can help both algorithms handle outliers more effectively.
Could K-Means be modified to reduce its bias?
Some variants of K-Means address its limitations:
K-Medians: Uses median instead of mean, which is more robust to outliers but can still enforce spherical clusters.
K-Medoids: Assigns actual data points as cluster centers. This method is less sensitive to outliers but can still have high bias if the data structure is not amenable to spherical partitions.
Spectral Clustering: Transforms data into a lower-dimensional space (via similarity matrices) before applying a K-Means-like procedure. This can capture more complex cluster structures but comes with additional computational overhead.
However, even these variants can’t capture covariance structures as flexibly as GMM without further model changes.
Practical Advice on Model Selection
When faced with a clustering task, consider the shape and distribution of your data:
If you expect spherical or non-overlapping clusters, or if simplicity and speed are critical, K-Means can be a good starting point.
If you suspect more complex cluster shapes or overlapping distributions, GMM is usually better at capturing such nuances, albeit with increased complexity and computational cost.
Careful model evaluation with domain knowledge, visualization, and appropriate metrics (e.g., AIC/BIC for GMM or inertia for K-Means) will guide you toward choosing the right clustering approach for your particular problem.