
ML Interview Q Series: Would the K-Nearest Neighbors algorithm be recommended when working with very large datasets, or are there specific concerns that might arise?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
K-Nearest Neighbors (KNN) is a simple yet powerful classification and regression technique that relies on finding the closest data points in the feature space to make predictions. One of its advantages is the lack of a strict training phase, as most of the computation is deferred to the inference stage. However, this very characteristic often leads to significant computational and memory costs on large datasets.
Core Distance Formula
The essence of KNN lies in computing the distances between a query point and all instances in the training set. A commonly used measure is the Euclidean distance, expressed as follows:

Where x is the feature vector of the query point, x_i is the feature vector of the i-th data point in the training set, m is the dimensionality of the data, x_j is the j-th feature of x, and x_{i_j} is the j-th feature of the i-th data point.
In high-dimensional spaces, the Euclidean distance can become less meaningful due to the curse of dimensionality, which further complicates KNN's performance on large datasets.
Time Complexity and Memory Concerns
KNN’s major drawback for very large datasets is related to the time complexity during inference. When you need to predict the label for a new point, the algorithm must compare that point with every record in the training set to find the nearest neighbors. This is often O(N * m) for each prediction, where N is the number of samples in the dataset and m is the number of features. If you have a massive dataset, this cost becomes prohibitive, especially if you need to perform predictions in real time.
Memory usage is also an issue, because you must store all the training examples in memory for the algorithm to search through them at prediction time. For extremely large datasets, storage and retrieval operations may become bottlenecks, and caching or parallelization strategies might be needed.
Possible Optimizations for Large Datasets
One common optimization is to use approximate nearest neighbor (ANN) techniques or specialized data structures like KD-trees or Ball Trees. These structures can reduce the search space but may still degrade in high-dimensional settings, and their construction can also be costly on massive datasets.
Dimensionality reduction can sometimes help. Techniques such as PCA (Principal Component Analysis) or autoencoders can lower the feature space dimension, making distance comparisons more efficient. Still, the benefit depends heavily on how well the lower-dimensional representation preserves the essential structure of the data.
Another strategy is to adopt a hybrid approach, where KNN might be combined with other methods or used on a subset of data selected via clustering. In practical production settings, one might also opt for more parametric or tree-based algorithms (like Random Forests or gradient-boosted trees) that can handle large datasets more efficiently after training.
Practical Scenarios
In environments where predictions need to be made rapidly or data is streaming at high velocities, KNN’s need to search the entire dataset for every prediction is usually impractical. However, for smaller datasets or offline applications where inference latency is not critical, KNN can be appealing due to its simplicity and relatively low overhead during training.
It is also useful as a baseline or quick sanity check when prototyping new projects, even if it might not be the final choice in a production-scale application. Ultimately, for extremely large datasets, the computational burden often makes KNN less favored unless approximate methods or specialized indexing techniques are employed.
What might be done to improve KNN's performance on massive datasets?
One strategy is to apply approximate nearest neighbor algorithms, which use data structures like Hierarchical Navigable Small World graphs (HNSW) or locality-sensitive hashing (LSH). These allow searching a reduced candidate set of neighbors rather than exhaustively comparing all points. Another potential solution is to partition the dataset with clustering algorithms. You can cluster the data first and then run KNN only within the cluster(s) relevant to a query point. This can dramatically reduce the required computations.
How can dimensionality reduction help in KNN for large datasets?
When data is high-dimensional, distance metrics can lose discriminatory power, and searching across many dimensions is computationally expensive. Dimensionality reduction techniques like PCA or autoencoders help by compressing the data into fewer dimensions while preserving important structure. By working with fewer dimensions, KNN’s distance calculations become more meaningful and faster. The trade-off is that if too much information is lost, classification or regression performance may suffer.
What about using specialized data structures for large datasets?
Spatial data structures like KD-trees or Ball Trees are often promoted for KNN. These accelerate the search for neighbors by partitioning the space in a way that reduces the number of distance computations. However, in very high dimensions, these structures often degrade to near-linear search because partitioning becomes less effective. Approximate search methods, on the other hand, can still offer speedups by accepting a small amount of inexactness in neighbor finding.
Are there situations where KNN is still beneficial for large datasets?
When the dataset, although large, has a strong local structure and relatively fewer relevant features, or if you implement efficient approximate methods, KNN can still perform well. Some production pipelines might rely on KNN at smaller scales for online learning tasks or as a fallback method for cold-start scenarios. Additionally, if memory and computational resources are abundant and inference speed is not critical, you might still consider KNN for its interpretability and straightforward implementation.
Could parallelization solve the computational bottleneck?
KNN is a naturally parallelizable algorithm. You can distribute the dataset across multiple machines and compute distances in parallel, then combine the results. This is beneficial in modern, distributed computing environments. But even with parallelization, the overhead of distance computation and data transfer for extremely large datasets can be quite high, especially if you need real-time predictions.
How do you choose K for large datasets?
Choosing K involves a balance between bias and variance. For large datasets, you may be tempted to pick a larger K to reduce variance, but too large K might incorporate many irrelevant points. Cross-validation can help in selecting the best K, but that process itself can be computationally expensive. So, you might rely on domain knowledge, problem constraints, or approximate cross-validation techniques to make a more informed selection.
What if the feature space is sparse?
Sparse, high-dimensional data (as often seen in text processing or recommender systems) intensifies KNN’s computational problem because each query might still need to examine many features and neighbors. In such cases, approximate techniques, hashing methods, or specialized data structures designed for sparse vectors become essential. If the data contains many zero-valued features, certain optimizations that skip unnecessary distance calculations can also be applied.
How does the curse of dimensionality come into play?
As dimensionality grows, distances between points can become less meaningful. Many points end up at similar distances from each other, making it difficult to discern true neighbors. For large datasets with many features, this results in decreased effectiveness of KNN, since the basic assumption that "closeness" implies similarity may break down. Dimensionality reduction or feature selection methods are often needed to address this.
Could you combine KNN with deep learning approaches for large datasets?
In some modern workflows, a neural network might first learn a compact representation of data. The last hidden layer’s outputs (an embedding) can be used for KNN. By doing so, you significantly reduce the dimensionality and capture semantically meaningful features. This approach is common in recommendation systems or few-shot learning tasks, where a learned embedding space is shared across many tasks, and KNN is applied on top of that space.
Below are additional follow-up questions
What if the dataset contains many categorical features or missing values?
When a dataset includes multiple categorical features, the notion of distance becomes more nuanced. Categorical attributes typically do not fit smoothly into Euclidean distance computations. One approach is to convert categorical features into numerical encodings (e.g., one-hot encoding), but that can lead to very high-dimensional feature spaces, intensifying the curse of dimensionality. Alternatively, domain-specific distance metrics (like Hamming distance for binary strings) or specialized similarity measures (like matching coefficients) may be more appropriate.
Handling missing values in KNN is also problematic, because the algorithm needs to compute a distance between every pair of points. If there are missing features, the distance formula might treat them differently depending on the implementation. One strategy is to impute missing values via domain knowledge or other imputation techniques before running KNN. Another approach is to only compare known features between samples or use a specialized distance function that discounts missing attributes. However, both solutions can introduce biases if missingness is not random.
In practical large-data scenarios, these transformations or imputations can become computationally expensive, especially if you must do them in real time or repeatedly for streaming data. You might need a well-engineered data pipeline or a more robust algorithm that can handle categorical variables natively and manage missing values more effectively.
How does KNN deal with noisy data or outliers in large datasets?
KNN does not include an internal mechanism to distinguish or down-weight outliers unless you adopt a weighted distance approach or explicitly clean the data. In large datasets, even a small fraction of outliers can disproportionately affect predictions, because KNN will blindly consider these points if they appear among the nearest neighbors.
One strategy is to use a robust distance metric that reduces the influence of extreme values, such as using a median-based distance measure instead of Euclidean. Another is to employ weighted KNN, where neighbors closer in distance carry more weight when voting. A common weighting scheme is:
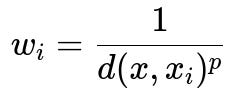
Where d(x, x_i) is the distance between the query point x and the neighbor x_i, and p is a positive exponent (often 2 or a small positive integer). This approach down-weights the effect of outliers that are far away. However, if outliers are still close enough to be in the top K neighbors, they can introduce noise in predictions.
In large-scale data, you may also consider outlier removal or robust data-cleaning strategies before training. The cost of cleaning might be high, but ignoring it can degrade performance significantly.
Is standardization or normalization more critical in KNN compared to other algorithms?
KNN heavily relies on distance computations, so if features are on vastly different scales, those with larger numeric ranges can dominate the distance. Consequently, standardization (transforming features to have zero mean and unit variance) or normalization (scaling data to a fixed range like [0, 1]) is often more important for KNN than for some algorithms that learn parameters to adjust feature weighting internally.
For large datasets, applying standardization or normalization can be computationally expensive, but it usually offers substantial benefits. You need to compute global statistics (mean, variance, or min and max values) across the entire dataset, which might be distributed or stored in large-scale systems. Implementing these scaling techniques efficiently often involves parallel operations or distributed computing frameworks to handle the data in chunks.
What are the effects of class imbalance on KNN with large datasets?
In highly imbalanced classification tasks, where one class significantly outnumbers another, KNN might suffer. If the majority class saturates the neighborhood around most query points, the model may be biased toward predicting that dominant class. This problem can worsen with very large datasets because even a modest imbalance ratio translates to huge absolute differences in sample sizes.
Techniques to address imbalance include oversampling the minority class (e.g., SMOTE) or undersampling the majority class. However, for large datasets, oversampling might become computationally expensive, and undersampling might result in a loss of critical data. Another strategy is to apply weighted voting, where each neighbor's vote is weighted by the inverse class frequency. Yet, carefully tuning these weights is essential to avoid overcorrecting the imbalance.
How do we handle incremental or streaming data in KNN for large datasets?
KNN’s reliance on storing all training samples makes it naturally suited for incremental data in theory, because you can simply add new points to your dataset as they arrive. However, in practice, continuously updating a massive dataset can become intractable, especially if you must recalculate or maintain specialized data structures (e.g., KD-trees, approximate nearest neighbor indices).
A naive approach is to just append new data points to your existing repository. But real-time inference becomes slower as the data grows. Partial indexing strategies, such as storing data points in multiple smaller indexes, can be used to handle updates more efficiently. You can also adopt a hybrid system that periodically reconstructs approximate nearest neighbor structures offline, while using a small buffer to capture the most recent data in the meantime.
Can memory usage be optimized in KNN for huge datasets?
Memory is a central concern because KNN must keep all samples accessible at inference time. A common optimization for large but sparse data is to store it in compressed or sparse matrix formats, so that only non-zero elements consume memory. This can speed up distance calculations too, if you skip operations on missing or zero values.
Another tactic is to store data in distributed systems that spread both data and computations across multiple nodes. While this addresses physical memory limits, communication overhead can become significant, so you often need specialized nearest neighbor search algorithms that operate efficiently in a distributed context.
Is it possible to define custom distance metrics for domain-specific data?
Yes, in some domains (e.g., genomics, medical imaging, or time-series analysis), standard Euclidean distance is less meaningful. You may define custom similarity measures capturing domain knowledge, such as edit distance for strings, dynamic time warping for time series, or specialized similarity functions for chemical compounds. These distances can often yield better accuracy, but they might be more expensive to compute. For large datasets, you face the same scalability problems: repeated distance calculations can be overwhelming.
When deploying KNN with a custom distance metric at scale, approximate methods or specialized indexing must be carefully implemented if possible. In certain domains, approximate versions of custom distances do not exist or are non-trivial to implement, forcing you to rely on more brute-force methods.
Is it viable to build KNN ensembles for large datasets?
Ensembling strategies like bagging or boosting can be used with KNN. For example, you might train multiple KNN “models” on different subsets of the data and then aggregate their predictions. This can provide robustness and possibly reduce variance. However, in large datasets, you must consider that each subset could still be huge, requiring substantial memory and time for inference.
If you build an ensemble of KNN models, each model’s nearest-neighbor search might be parallelized, but overall resource utilization will increase. You also risk duplication of effort across subsets. Sometimes ensembles are more practical with model-based methods (like Random Forests) that create compressed representations during training, rather than keeping entire subsets of training data.
How do you diagnose and fix poor KNN performance on large datasets?
When KNN results are disappointing, it’s often due to:
Distance metric mismatch: The chosen distance might not capture the notion of similarity for your domain. Consider custom or more robust metrics.
Feature scaling issues: Some features might dominate the distance measure. Proper normalization or feature selection can help.
Excessive dimensionality: Too many features can reduce the effectiveness of distance-based learning. Dimensionality reduction or targeted feature engineering is key.
Resource constraints: If prediction times are too long or memory usage is too high, approximate nearest neighbor search or other algorithms may be necessary.
Outliers or noisy data: Identify and mitigate them via robust data cleaning or weighting mechanisms.
You’d usually start by analyzing the distribution of distances for a sample of queries, verifying class distributions in neighborhoods, and monitoring the performance on validation sets. Tools like cross-validation or holdout sets, combined with domain expertise, guide whether to switch metrics, reduce dimensions, or adopt approximate indexing.
What are the ethical or compliance considerations for storing large volumes of data in KNN?
Since KNN literally stores all training data, it inherently poses risks regarding sensitive or personal data. In some regulatory environments (such as GDPR), data subjects have the “right to be forgotten.” Implementing that right in KNN might require removing specific data points from the training set. For large datasets, ensuring a thorough and permanent removal can be laborious, especially if you maintain multiple copies or backups.
Another issue is that KNN can inadvertently memorize personal or proprietary information. If distance-based queries are made accessible, malicious users could probe or infer private details by systematically querying neighbors. Hence, an organization must implement secure data storage, limit query access, and design privacy-preserving strategies (like anonymization, data obfuscation, or secure enclaves). These considerations can be more stringent than with parametric models, where the original data might not be directly stored.