
ML Interview Q Series: You need to train a classifier and have access to abundant unlabeled data alongside only a few thousand labeled samples. How would you tackle this challenge?


📚 Browse the full ML Interview series here.
Comprehensive Explanation
When faced with a situation where labeled data is limited yet unlabeled data is plentiful, a powerful solution involves leveraging both sets in a semi-supervised manner. By combining supervised training on labeled instances with techniques that extract information from unlabeled samples, models can learn more robust representations than using labeled samples alone.
Semi-supervised learning methods typically assume that the labeled and unlabeled data come from the same or a closely related distribution. This assumption allows the model to benefit from identifying patterns and structure in the unlabeled data, which ultimately leads to improved generalization on new, unseen samples.
One standard approach in semi-supervised learning is to integrate a supervised loss (using labeled data) with an unsupervised loss (using unlabeled data). The supervised part typically measures how well the model predicts the known labels, while the unsupervised part encourages consistent, stable predictions on unlabeled samples under various augmentations or perturbations.
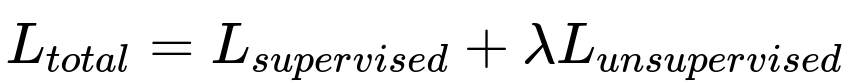
Where L_{supervised} is usually the cross-entropy loss on labeled data. For an input x_i with true label y_i, the cross-entropy measures how well the predicted distribution matches y_i. L_{unsupervised} is often a consistency loss that enforces similar model outputs for unlabeled data under augmentations. The parameter lambda (a hyperparameter) balances the influence of the unsupervised loss relative to the supervised loss.
In practical implementations, the unsupervised loss can take the form of consistency regularization, pseudo-labeling, or other specialized objectives. The key principle is that the model’s predictions on unlabeled data should remain consistent under transformations, or should be confident enough to use them as proxy labels for further training.
Various additional techniques can bolster the effectiveness of training:
Transfer Learning. You can pre-train a model on a large dataset that is similar or general in nature, then fine-tune it using your few thousand labeled instances and possibly leverage unlabeled data to further refine the representations.
Active Learning. Instead of randomly labeling from the unlabeled pool, you can adopt an active learning approach where the model chooses unlabeled samples it is least certain about. Then a domain expert or oracle provides the ground-truth labels for those samples, improving label efficiency.
Data Augmentation. Even though your labeled set may be small, you can systematically apply transformations (like random crops, flips, rotations, or domain-specific variations) to increase effective training variety, helping the model generalize better.
Model Ensembling. Techniques such as self-ensembling maintain multiple model versions or use temporal model averaging. These ensembles produce more stable signals for the unlabeled data, further improving performance.
Below is a simplified Python snippet demonstrating the structure of semi-supervised training where you combine a supervised cross-entropy loss with an unsupervised consistency loss. Note that actual implementations often include more advanced data augmentations, scheduling for lambda, and other refinements.
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
# Assume we have:
# - labeled_dataset: small labeled dataset
# - unlabeled_dataset: large unlabeled dataset
# - model: neural network
# - optimizer: optimizer like Adam
# - lambda_val: weight for unsupervised loss
labeled_loader = DataLoader(labeled_dataset, batch_size=32, shuffle=True)
unlabeled_loader = DataLoader(unlabeled_dataset, batch_size=32, shuffle=True)
def consistency_loss(preds1, preds2):
# A simple MSE-based consistency cost
return F.mse_loss(preds1, preds2)
for epoch in range(num_epochs):
for (labeled_data, labeled_targets), (unlabeled_data, _) in zip(labeled_loader, unlabeled_loader):
# Supervised forward pass
outputs_labeled = model(labeled_data)
sup_loss = F.cross_entropy(outputs_labeled, labeled_targets)
# Unsupervised forward pass
outputs_unlabeled_1 = model(unlabeled_data)
# Apply some augmentation, then forward pass again
augmented_data = augment(unlabeled_data)
outputs_unlabeled_2 = model(augmented_data)
# Consistency loss
unsup_loss = consistency_loss(outputs_unlabeled_1, outputs_unlabeled_2)
total_loss = sup_loss + lambda_val * unsup_loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
This example just captures the essence of a semi-supervised loop, where you compute a supervised loss from labeled data and an unsupervised loss from unlabeled data. The exact nature of the unsupervised objective can be more sophisticated (e.g., pseudo-labeling, where you generate pseudo-labels for unlabeled samples and use them for supervised-like training).
Why This Works
When your labeled data is scarce, it provides only a narrow lens on the underlying data distribution. The abundance of unlabeled data helps reveal the broader structure, making learned representations more general. For instance, the model learns to output consistent predictions for unlabeled points under different perturbations, thereby reinforcing stable internal features that are useful for classification.
Potential Pitfalls and Considerations
One concern is the difference in distribution between labeled and unlabeled data. If unlabeled data originates from a different domain, the model might learn misleading patterns that degrade performance on your true labeled tasks. Monitoring model performance on a small validation set is crucial to detect any divergence.
Another consideration is hyperparameter tuning, particularly for lambda (the weight of the unsupervised loss). Too high a weight can force the model to overfit potentially ambiguous predictions on unlabeled data, while too low a weight might underutilize the unlabeled pool.
Additionally, it’s essential to ensure that unlabeled data does not introduce incorrect bias. For example, if large portions of unlabeled data are outliers or have very different characteristics, they might reduce overall performance. Techniques like domain adaptation or filtering out-of-domain samples can help mitigate this risk.
How to Extend This Approach
You can incorporate advanced methods, such as consistency regularization with data augmentation or adversarial training, to make the model more robust. Alternatively, you can explore methods that iteratively refine pseudo-labels, so the model’s confident predictions get re-labeled and included in the labeled set for the next training round.
Possible Follow-Up Questions
How does active learning compare with semi-supervised learning?
Active learning and semi-supervised learning can both help when labeled data is scarce. However, active learning focuses on strategically querying the most informative samples from the unlabeled pool to be labeled by an expert. This approach aims to maximize performance gain per newly labeled instance. Semi-supervised learning, on the other hand, tries to utilize all unlabeled data by imposing constraints on model predictions without necessarily obtaining additional human-annotated labels. Combining both can be powerful: first use active learning to label the most important instances, then apply semi-supervised methods to leverage the rest.
What if the unlabeled data is drawn from a different distribution than the labeled data?
If the unlabeled samples come from a domain that doesn’t match the labeled data distribution, the model might learn features that do not generalize well to your target task. This scenario might require domain adaptation techniques to align the distributions. One strategy is to filter out unlabeled samples that appear too dissimilar, or to apply adversarial approaches that encourage the model to learn domain-invariant features. Monitoring validation performance and domain similarity metrics is vital to detect if unlabeled data is helping or hindering.
How can we measure the benefit of unlabeled data?
One way is to compare the performance of a baseline model trained solely on the labeled subset against a model trained using both labeled and unlabeled data. You can track improvements in metrics such as accuracy, F1 score, or other relevant measures on a validation/test set. A significant gain indicates that the unlabeled data is being leveraged effectively.
How do we choose an appropriate unsupervised loss or method for our particular data?
Choosing the right unsupervised objective often depends on the nature of your data and the overarching task. For image data, consistency-based methods (where you apply distortions or data augmentations) are common. For text data, methods like masked language modeling or pseudo-labeling can be helpful. Evaluating a few well-known semi-supervised frameworks (like FixMatch, Mean Teacher, or MixMatch for images) is typically done in practice. You can adapt them to your dataset and fine-tune hyperparameters to see which works best.
Could transfer learning alone solve this issue if we have a massive pre-trained model?
Transfer learning can significantly reduce the data requirements by leveraging representations learned from large-scale pre-training. This approach can be particularly effective if the large pre-trained model was trained on data that is similar to the target domain. However, if your labeled dataset is still too small, direct fine-tuning might overfit quickly. In that case, combining transfer learning with semi-supervised learning on the available unlabeled data can further enhance performance. By doing so, you adapt high-level features from the pre-trained model and also learn domain-specific nuances from the unlabeled samples.
Below are additional follow-up questions
How do you set a confidence threshold for pseudo-labeling, and what if the model’s predictions are overconfident?
A common practice in pseudo-labeling is to generate “pseudo-labels” for unlabeled data when the model’s predicted probability for a certain class exceeds a threshold. This threshold helps filter out noisy labels, but choosing it can be tricky. If it is set too low, many incorrect predictions might be included, leading to noisy training signals. If it is set too high, you might lose valuable unlabeled samples that are simply not predicted with high confidence, thus underusing your data. A practical approach is to treat the threshold as a hyperparameter. You can test different thresholds and monitor validation performance, adjusting the threshold to find the best balance. One subtle danger is that modern neural networks may produce overconfident outputs even when they are incorrect. This can be partially mitigated by calibration techniques (like temperature scaling) that aim to align predicted probabilities more closely with true likelihoods. However, it remains essential to re-check whether pseudo-labeling is genuinely enhancing performance or introducing detrimental bias, especially if the labeled set is small and does not capture the full class diversity.
How can you deal with label noise in the small labeled dataset?
When your small labeled dataset contains inaccuracies, the errors can heavily influence the model’s learning process. Even more dangerously, noise in your labeled set can propagate into any semi-supervised scheme, especially if you rely on the mislabeled samples for generating pseudo-labels or consistency targets. One strategy is to perform a thorough data audit on the labeled subset, correcting obvious discrepancies before training begins. You can also incorporate robust loss functions or noise-robust training procedures (e.g., label smoothing, confidence-based weighting) that reduce the impact of outliers. Another idea is to iteratively refine your labels by training a model, identifying samples the model consistently flags as uncertain, and then re-verifying or re-labeling those particular instances. This iterative relabeling can be combined with active learning to focus the labeling effort where it is most needed.
What if we have extremely imbalanced classes in the small labeled dataset, but the unlabeled pool might contain more examples of the minority class?
Class imbalance poses a unique challenge because the model might not even discover minority-class patterns within the unlabeled set if it is already biased toward majority classes from the labeled set. A potential mitigation strategy is to place stronger emphasis on minority-class examples in the supervised loss, for instance by using class-weighting or focal loss that adapts its weighting based on difficulty. Meanwhile, consistency-based regularization can be used on unlabeled data, but you might also artificially amplify or search for unlabeled samples that seem to belong to underrepresented classes. Another approach is to perform clustering on the unlabeled data and then selectively label samples from clusters that appear to contain minority patterns. This active cluster labeling technique can help ensure the minority class is discovered and represented. In real-world scenarios, underrepresented classes are often the ones of greatest practical interest, so carefully tracking metrics like recall for that class is vital.
How can we reliably evaluate model performance if we have very little labeled data for validation?
Evaluation is often a bottleneck when labeled data is scarce. Relying on a small validation set can lead to high variance in performance estimates. One approach is to use cross-validation on the limited labeled set, repeatedly splitting it into training and validation partitions to obtain more stable estimates. Another tactic is to set aside a small but reliable set of cleanly annotated examples that you never use for training, ensuring you have a trusted baseline for performance measurement. You might also supplement your evaluation with domain-specific metrics or heuristics, such as user feedback if the classifier is deployed in a production environment. However, these heuristics and feedback loops can introduce biases if they don’t represent a broad range of real-world cases. Monitoring your model’s predictions in real-time is another way to detect potential drifts or failures that may not be immediately apparent from a small static test set.
What are some key diagnostic steps when you suspect your semi-supervised model is not improving compared to a purely supervised approach?
First, check if the unlabeled data truly resembles the distribution of your labeled data. If they diverge significantly, your model might be learning confusing signals. Second, analyze the pseudo-labels or consistency-based predictions the model is making on unlabeled samples. If these are highly erroneous, then the semi-supervised objective might be reinforcing bad patterns. Third, verify that your hyperparameters (for example, the weight of the unsupervised loss) are not either dominating the training or too small to have an impact. Fourth, conduct an ablation study: disable certain components (like pseudo-labeling or consistency loss) to isolate which part of the pipeline is causing trouble. Finally, scrutinize your small labeled dataset for label errors or class imbalance issues. This multi-step diagnosis can reveal whether domain mismatch, mislabeled data, or poor hyperparameter settings are hindering semi-supervised gains.
Are there scenarios where semi-supervised learning could degrade performance, and how do we detect those cases early?
Yes. If your unlabeled data is from a distribution that differs substantially from your labeled set, incorporating it can introduce spurious patterns and degrade performance on the target domain. Another situation is when the model generates incorrect or overconfident predictions that lead the training process astray, magnifying label errors over time. You might detect this by monitoring validation accuracy and loss not just globally, but also by subgroups or over time. If performance on the validation set stagnates or worsens, or if certain subgroups degrade, it is a warning sign that the unlabeled data or the training procedure may be problematic. Regularly visualize or manually inspect how the model labels some unlabeled samples and watch out for systematic mistakes. Implementing an early-stopping mechanism based on validation metrics is another safeguard against overfitting to bad pseudo-labels.
How can you scale semi-supervised learning methods to a very large unlabeled dataset in a production environment?
When the unlabeled dataset is massive, computing the unsupervised loss for all samples can be computationally expensive. A common solution is to subsample batches of unlabeled data or use approximate techniques like importance sampling that focus on the most informative samples. You might also periodically update pseudo-labels in batches instead of computing them every single iteration. In distributed training environments, careful synchronization is needed so that different workers have consistent views of the labeled set and share updated model parameters efficiently. Memory constraints can also be a challenge, necessitating streaming data pipelines. Additionally, caching augmented versions of unlabeled batches or using GPU accelerations for data transformations can reduce overhead. Thoroughly profiling your data pipeline helps to identify bottlenecks, ensuring the solution can scale to real-world production constraints at large companies.
Does semi-supervised learning obviate the need for well-labeled data entirely?
No. Semi-supervised methods still fundamentally rely on having a sufficiently representative labeled set, even if it’s relatively small. If those labels are too few or unrepresentative, the model can adopt biased or incomplete views of the task. Moreover, the labeled set typically anchors the objective to your classification goal, preventing the model from drifting toward extraneous patterns found in the unlabeled portion. In practical scenarios, while it’s tempting to think that you can skip gathering more annotations, ensuring your labeled data covers the main classes, distribution modes, and any special cases remains essential. Neglecting quality labeling can lead to systematic errors that semi-supervised learning may not correct, no matter how large the unlabeled pool is.
How might domain experts or non-ML stakeholders contribute to improving results in a semi-supervised pipeline?
Domain experts can play a critical role by curating or revising the labeled dataset. This involves verifying uncertain samples or boundary cases to ensure that the few labels you do have are as accurate and representative as possible. Experts can also help design more meaningful data augmentations that mimic real-world variations. In many applications—such as healthcare, finance, or legal contexts—the data has unique domain-specific transformations that an outsider might not consider. Non-ML stakeholders can help you prioritize which mistakes are most costly to the business so you can focus labeling efforts on samples where errors are particularly harmful. Continuous collaboration with domain experts also helps detect concept drift or changes in data patterns before they become severe problems, which is especially relevant when you rely heavily on unlabeled data that may come from evolving data streams.