
ML Interview Q Series: Zero Covariance for Uniform X and X² Due to Distribution Symmetry

Browse all the Probability Interview Questions here.
Assume X is drawn uniformly from the interval (-1, 1) and we define Y as X². Determine the covariance between X and Y.
Short Compact solution
Using the definition of covariance, we have Cov(X, Y) = Cov(X, X²). This expands to E[X·X²] - E[X]E[X²], which simplifies to E[X³] - E[X]E[X²]. For X ∼ Uniform(-1,1), the symmetry of the distribution implies E[X] = 0 and E[X³] = 0. Hence, Cov(X, Y) = 0.
Comprehensive Explanation
Definition and Key Properties
Covariance between two random variables X and Y is given by Cov(X, Y) = E[(X - E[X])(Y - E[Y])] = E[XY] - E[X]E[Y].
Here, we set Y = X². Therefore, Cov(X, X²) = E[X · X²] - E[X]E[X²] = E[X³] - E[X]E[X²].
To find E[X³], recall that X follows Uniform(-1,1). The probability density function (pdf) for X is 1/2 for x in (-1,1) and 0 otherwise. Because the distribution is symmetric around 0, every positive x in the interval has a corresponding negative -x of equal magnitude but opposite sign. Thus, when integrating x³ over -1 to 1, the positive and negative areas cancel each other out exactly. Hence, E[X³] = 0.
Moreover, E[X] also equals 0 for a uniform distribution centered at 0. Therefore, the covariance becomes 0 because the term E[X]E[X²] vanishes (since E[X] = 0), and E[X³] itself is 0. Consequently, Cov(X, X²) = 0.
In other words, a variable X that is symmetric about zero will tend to have zero covariance with any function of X that is purely even—X² is an even function—unless there is some asymmetry in the distribution or other dependency structures at play.
Potential Follow Up Question #1: What if the distribution of X was not symmetric around zero?
If X was not symmetric (for instance, if X ∼ Uniform(0,1) or some other non-symmetric distribution), the calculation of E[X] and E[X³] might not be zero. In that case:
• E[X] might be nonzero. • E[X³] might also be nonzero.
Hence, Cov(X, X²) could be nonzero. The core reason that Cov(X, X²) = 0 for Uniform(-1,1) is precisely the perfect symmetry about zero, which forces all odd moments (including the first and third) to vanish.
Potential Follow Up Question #2: Why exactly does E[X³] vanish for X ∼ Uniform(-1,1)?
Intuitively, for every positive value x in (-1,1), there is a corresponding negative value -x in the domain. Because the function x³ is an odd function (meaning (−x)³ = −(x³)), their contributions to the integral that defines E[X³] cancel out. Formally:
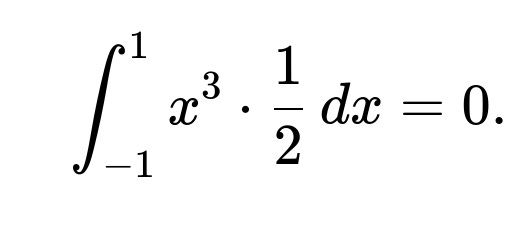
That integral over [-1,1] for x³ with a symmetric density always equals zero because the positive area from x > 0 cancels the negative area from x < 0.
Potential Follow Up Question #3: How is E[X²] computed for X ∼ Uniform(-1,1), and does it matter here?
Although E[X²] does not impact the final answer (because E[X] = 0 nullifies the product term), it is still interesting to compute it. For X ∼ Uniform(-1,1):

This integral equals (1/2) * ( [ x³ / 3 ] from -1 to 1 ), which is (1/2) * ( (1³/3) - ((-1)³/3 ) ) = (1/2)*(2/3) = 1/3. While it doesn’t change the fact that the covariance is zero, it confirms that E[X²] > 0 but gets multiplied by zero in Cov(X, X²).
Potential Follow Up Question #4: Can we verify Cov(X, X²) = 0 with a quick Python simulation?
Below is a small Python script that draws many samples from Uniform(-1,1), computes X², and then approximates Cov(X, X²).
import numpy as np
# Number of samples
N = 10_000_000
# Draw samples for X
X = np.random.uniform(-1, 1, size=N)
# Compute Y = X^2
Y = X**2
# Calculate empirical covariance
cov_estimate = np.cov(X, Y, bias=True)[0,1]
print("Estimated Cov(X, X^2):", cov_estimate)
In most runs, the printed estimated covariance will be very close to zero, illustrating the theoretical result.
Potential Follow Up Question #5: When might zero covariance not imply independence?
Even though Cov(X, X²) = 0 for X ∼ Uniform(-1,1), X and X² are not independent. Zero covariance just indicates there is no linear relationship between the two variables. However, X² is clearly determined by X, so there is a strong nonlinear dependence. In general, zero covariance is not enough to conclude independence unless the distribution is known to be jointly normal (or some other special case).
Potential Follow Up Question #6: How is this useful in Machine Learning contexts?
Feature Engineering: When adding polynomial features (like X²) to a model, it may not contribute a linear correlation with X if X is centered and has symmetric distribution. However, it could still capture nonlinear patterns.
Regularization: Sometimes zero covariance is relevant in certain whitening or decorrelation procedures, but it does not necessarily mean variables are unrelated in a predictive sense.
Neural Networks: Activation functions and transformations can change the distribution of internal activations. Analyzing their covariances can help with understanding neural network batch normalization or other internal transformations.
All these considerations highlight that while covariance is a simple and powerful metric to detect linear relationships, many real-world phenomena are governed by more complex structures, which underscores the importance of higher-order statistics or more nuanced approaches like mutual information.
Below are additional follow-up questions
What if the distribution of X was still symmetric but not uniform? Would Cov(X, X²) always be 0?
Even if the distribution is symmetric about zero, to guarantee that Cov(X, X²) is zero, we need to ensure that the third moment E[X³] is zero. This is certainly true for any perfectly symmetric distribution about zero, because for every positive value x, there is a negative value −x with the same probability density, and their cubes cancel out. Thus for all even functions (like x²), Cov(X, x²) will generally be zero if the distribution is truly symmetric and centered. However, in practical real-world data, perfect symmetry is often violated by small deviations or measurement noise, which could yield a tiny but nonzero covariance. Hence, while theory states that any symmetric, zero-mean distribution should produce E[X³] = 0, real data might reveal slight asymmetry and a small but non-trivial covariance.
What if Y was not strictly X² but a slightly modified function, say X² + C, where C is a constant?
When Y = X² + C, we can compute Cov(X, Y) = Cov(X, X² + C). By the property of covariance with constants, Cov(X, C) = 0 (since a constant does not vary). Therefore,
Cov(X, X² + C) = Cov(X, X²) + Cov(X, C) = Cov(X, X²) + 0.
Since Cov(X, X²) = 0 for this symmetric uniform distribution, the addition of a constant C alone does not affect the covariance. In practice, the presence of a constant might still affect other aspects of a model (for instance, if Y were used in a regression setting, the intercept might shift), but it would not affect the covariance with X.
Could rounding or floating-point imprecision in a numerical simulation cause a nonzero empirical covariance?
Absolutely. In a real simulation with floating-point arithmetic, you might see a very small covariance that is not exactly zero because of numerical precision errors and sampling variation. For instance, if you use a limited number of samples, random fluctuations can produce a slight positive or negative covariance. Additionally, floating-point errors can accumulate when dealing with very large sample sizes. However, as the sample size grows, the empirical covariance should converge to zero due to the Law of Large Numbers and the inherent symmetry of the distribution.
How could we test whether Cov(X, Y) = 0 in a statistical sense rather than relying on theoretical derivation?
One approach is to formulate a hypothesis test:
Null Hypothesis H₀: Cov(X, Y) = 0.
Alternative Hypothesis H₁: Cov(X, Y) ≠ 0.
We could gather a sample of observations (Xᵢ, Yᵢ) and compute the sample covariance. Then, we can use a test statistic (for instance, a Z-test approximation if the sample size is large enough) and see if we can reject the null hypothesis. If the distribution is truly uniform(-1,1) and Y = X², theoretically, we expect the test to fail to reject H₀ given enough data, indicating Cov(X, Y) is indeed zero. In practical data scenarios, any small but systematic deviation from the ideal distribution or the ideal function might result in rejecting or failing to reject H₀ depending on the effect size and sample size.
In which circumstances might Cov(X, X²) not be 0 but still be small enough to ignore?
In real-world data modeling, distributions are rarely perfectly symmetric. If the dataset is “close” to symmetric and the skew is small, then E[X³] might be near zero rather than strictly zero. This can yield a very small—but not strictly zero—covariance with X². Depending on the modeling objective, a small covariance may be negligible in practice. For instance, if you’re performing feature selection, you might choose to ignore a feature that has extremely small covariance with your variable of interest, assuming it does not contribute significantly to your model.
If X and X² are used together as predictors in a linear model, how does zero covariance between them affect collinearity?
When two predictors are uncorrelated, it implies they do not have a linear relationship. This helps reduce one form of collinearity. However, X and X² in the symmetric uniform case are uncorrelated, but they do have a functional relationship: one is simply the square of the other. This means if we allow for nonlinear transformations in the model, we recognize that X² is entirely determined by X, suggesting perfect functional dependence in the theoretical sense. Thus, they might still induce issues in certain modeling scenarios where polynomial expansions lead to multicollinearity (especially if the polynomial degree is higher). So, zero covariance alone does not guarantee no collinearity in polynomial expansions.
What if we consider a piecewise definition of Y instead of a simple square function?
Consider a function Y =
X² if X ≥ 0,
2X² if X < 0.
This piecewise function still depends on X, but not symmetrically. Then Cov(X, Y) = E[X·Y] - E[X]E[Y]. Because Y’s definition treats positive and negative X differently, you lose the symmetrical cancellation that helped E[X³] vanish. Consequently, you might no longer have E[X³] = 0 in a way that cancels with the function Y(X). Even if X is uniform(-1,1), that symmetry alone does not guarantee that Cov(X, Y) will be zero, because Y no longer behaves as an even function around zero. The subtlety lies in how Y is defined and whether its behavior contributes symmetrical negative and positive values that can cancel out in the integral.
Is zero covariance with X² a unique property for uniform(-1,1) or does it hold for other symmetric distributions with zero mean?
Any symmetric distribution about zero with finite third moments leads to E[X³] = 0. Examples include the Normal(0,1) distribution or any zero-mean distribution whose pdf is mirrored exactly across zero. Hence, Cov(X, X²) would also be zero for those distributions. The crucial requirement is exact symmetry about zero (which forces E[X] and all odd moments like E[X³] to vanish). If that symmetry is even slightly broken, you can expect a nonzero result.