
ML Interview Q Series:Why might combining multiple cost components (e.g., reconstruction loss + classification loss) in a multi-task setup lead to optimization conflicts, and how can you resolve them?


📚 Browse the full ML Interview series here.
Hint: Consider weighting each component or using techniques like gradient surgery.
Comprehensive Explanation
When a model is trained in a multi-task setting, the overall objective function typically consists of more than one loss term. For instance, there might be a reconstruction loss that measures how well the model reconstructs its input, along with a classification loss that measures how accurately the model classifies samples. Each of these losses exerts its own pull on the model parameters, causing potential conflicts during optimization.
Conflicts arise when the gradient directions implied by each task’s objective do not align well, or sometimes even oppose each other. This can result in situations where decreasing one task’s loss forces the other loss to increase, thus leading to suboptimal performance across tasks.
A common strategy to address this is to introduce weighting factors that balance the importance of each loss. Another set of techniques, often referred to as gradient surgery or gradient manipulation methods, attempts to modify the gradient vectors to avoid interference. These techniques can help ensure that progress on one task does not come at the expense of another.
Typical Multi-Task Objective
One way to represent a multi-task loss is to weight each task’s objective and then sum them up:
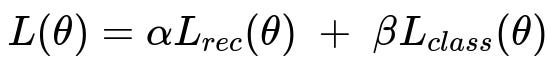
where
L_rec(theta) is the reconstruction loss, measuring how faithfully the model reconstructs input data.
L_class(theta) is the classification loss, measuring accuracy or likelihood for a classification task.
alpha and beta are weighting hyperparameters that control the relative importance of each task’s loss component.
If alpha is too large relative to beta, then the model may over-optimize for reconstruction at the expense of classification. Conversely, if beta is too large, classification performance might be good while reconstruction quality suffers. Adjusting alpha and beta is one straightforward way to mitigate optimization conflicts by tuning the relative priorities of each task.
Causes of Optimization Conflicts
Conflicting Gradient Directions In a multi-task scenario, the gradient with respect to one task’s parameters can sometimes point in a direction that increases the loss for another task. For example, an update step that lowers L_rec might inadvertently worsen L_class.
Different Scales of Losses Some loss terms might naturally be larger in magnitude than others. This can cause gradients from one task to dominate, overshadowing improvements that could have been made to the other task.
Different Learning Dynamics Certain tasks may converge faster than others. If the fast-converging task still has a large gradient, it can keep pulling the model parameters toward its optimal solution, preventing other tasks from sufficient progress.
Methods for Resolving Conflicts
Weighted Loss Functions One of the most common methods to address multi-task training conflicts is through careful selection of alpha and beta. By tuning these hyperparameters, you can adjust the trade-off between tasks. However, picking good values may require a combination of domain knowledge and experimentation. Automatic methods like dynamic weighting can also be used, where alpha and beta adjust themselves over time based on each task’s gradient magnitudes.
Gradient Surgery (Gradient Manipulation) Various methods have been proposed to resolve directional conflicts in gradients. One such approach is Projected Gradient Descent techniques, like PCGrad, which projects the gradients for one task away from the conflicting directions for the other tasks. Another approach is GradNorm, which tries to balance gradient magnitudes for different tasks. By directly altering gradient vectors to reduce interference, these methods aim to preserve each task’s learning progress.
Task-Level Annealing In some scenarios, it is beneficial to focus on a subset of tasks initially, then gradually introduce or increase the weight of the remaining tasks. This step-by-step approach can minimize immediate conflicts by letting certain tasks converge to a stable region before introducing more tasks.
Loss Rescaling One simple but sometimes effective approach is normalizing each task’s loss to a similar scale. For example, if L_rec is measured in hundreds while L_class is measured in single digits, the classification loss might be overshadowed unless it is rescaled.
Implementation Insights
In practice, these strategies can be combined. Many practitioners start with a weighted sum approach, experiment with different alpha and beta values, and observe training curves to see whether one loss consistently dominates. If so, they may consider implementing gradient manipulation techniques to ensure that no single gradient direction overwhelms the others.
A typical code snippet for a weighted loss in Python might look like this:
import torch
import torch.nn as nn
class MultiTaskModel(nn.Module):
def __init__(self):
super().__init__()
# Define model layers here
def forward(self, x):
# Forward pass
return reconstruction_output, classification_output
# Example usage
model = MultiTaskModel()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
alpha = 0.5
beta = 0.5
reconstruction_criterion = nn.MSELoss()
classification_criterion = nn.CrossEntropyLoss()
for data, target in dataloader:
reconstruction_output, classification_output = model(data)
loss_rec = reconstruction_criterion(reconstruction_output, data)
loss_class = classification_criterion(classification_output, target)
loss = alpha * loss_rec + beta * loss_class
optimizer.zero_grad()
loss.backward()
optimizer.step()
You can then adjust alpha and beta. For more advanced gradient surgery techniques, you would manipulate the gradients after calling loss.backward() but before calling optimizer.step().
Potential Follow-up Questions
How do you pick appropriate weighting factors for multi-task losses?
In many cases, weighting factors are found through empirical hyperparameter tuning. However, automated approaches also exist, such as:
GradNorm, which learns weights that balance the gradient magnitudes of each task automatically.
Uncertainty-based weighting, where each task’s weight is inversely proportional to its noise/uncertainty estimate.
Models can iteratively adjust these weights based on gradients during training. The best approach often depends on the specific tasks, data scale, and computational constraints.
What if one task is more important than the others?
In scenarios where a single task, say classification, is critical (for example, classification in a medical diagnostic tool), you might assign a higher weight to that loss component to ensure it gets priority. This will shift the model’s capacity to focus more on that critical task, accepting reduced performance on the secondary tasks as a trade-off.
How does gradient surgery help ensure each task is learned effectively?
Gradient surgery techniques like PCGrad analyze the gradient vectors from different tasks and project any conflicting components away from each other. The motivation is that destructive interference in gradient directions is avoided, so each task can progress along a direction that is not detrimental to the others. By maintaining as much of the original gradient direction as possible (apart from the conflicting part), the overall learning is more harmonious across tasks.
What practical challenges might arise with gradient manipulation methods?
Some challenges include:
Additional computational overhead to compute and adjust gradients across multiple tasks.
Hyperparameters within these gradient manipulation methods (e.g., thresholds for conflict, projection settings) can introduce new tuning complexities.
Potential partial or incomplete resolution of conflicts if tasks have inherently opposing objectives that cannot be reconciled by directional manipulation alone.
When might it be better to train separate models instead of a single multi-task model?
If the tasks have very weak or no shared representations and combining them actually reduces performance on each task, it might be simpler and more effective to train separate specialized models. Additionally, if one task requires a very different network architecture or has data with significantly different modalities, separate models may be the more optimal choice. Multi-task learning typically excels when tasks can share beneficial representations, so if that assumption breaks down, separate models are often preferred.
Could there be issues in multi-task learning when one of the tasks has insufficient training data?
When a particular task has limited training data, its gradient estimates might be less reliable, and any shared parameters could become biased toward the tasks with more abundant data. One remedy is to implement data-augmentation strategies or weighting schemes to help under-represented tasks. Another approach is to design network architectures that allow partial or selective sharing of parameters, reducing negative transfer from tasks that dominate the training process.
These are some of the key ideas and potential pitfalls. Balancing multiple objectives in a single model is powerful, but it requires careful design of the training procedure to ensure that you do not trade too much performance in one task for a gain in another.
Below are additional follow-up questions
How do we detect when tasks are inherently incompatible, and what strategies can be used to diagnose and address these incompatibilities?
Tasks might exhibit fundamentally opposing goals. For example, one task could push representations toward capturing fine-grained details for reconstruction, while another task might require more abstract features for classification. In such scenarios, you might notice symptoms like stagnating or oscillating losses, a strong reduction in performance for one task when the other improves, or continuously diverging gradients.
Practical ways to detect incompatibility include:
Monitoring Correlations of Gradients. If the dot product of the gradients for two tasks is consistently negative, it indicates they point in conflicting directions. Persistently negative correlations suggest deeper incompatibilities.
Comparing Separate vs. Joint Training. Train models separately for each task and compare performance with a jointly trained model. If joint performance is significantly worse than separate performance, it might signal fundamental incompatibilities.
Ablation Studies on Model Capacity. Reduce or increase model capacity. If increasing capacity significantly alleviates conflicts, the problem may be model under-parameterization rather than true incompatibility.
Strategies to address incompatibility:
Selecting Subtasks for Multi-task Learning. If tasks truly conflict, it may be more effective to combine only those tasks that have compatible objectives and train the others in separate models.
Using Task-Specific Heads. Even if some initial layers are shared, employing distinct final layers or specialized subnetworks for each task can minimize negative interference while still leveraging shared features.
Curriculum or Sequential Training. Focus on compatible tasks first; then fine-tune on more challenging or conflicting tasks. Although this doesn’t fully remove incompatibilities, it can reduce catastrophic interference by learning stable representations initially.
Edge cases to consider:
Highly imbalanced dataset distributions for the tasks. One task could dominate if its data is prevalent, masking the actual incompatibility in the other task.
Varying definitions of success. For instance, a reconstruction task might thrive on capturing small details, whereas a classification task may focus on generalizable features, causing disagreement.
How can partial parameter sharing mitigate conflicts in multi-task training?
Partial parameter sharing refers to having some shared layers that capture general features beneficial to multiple tasks, while other layers remain task-specific. This approach can reduce detrimental interference by allowing each task to have its own specialized pathway for features that do not generalize well.
Under partial sharing, the architecture might have:
Shared Early Layers. These layers learn universal features, such as edges or basic shapes in visual tasks. Early layers often capture domain-invariant attributes.
Split Later Layers. Higher-level representations are more specific to each task. By providing separate higher-level parameters (e.g., separate branches, attention modules, or heads), conflicts can be minimized.
Potential pitfalls:
Overly Large Shared Layers. If too many layers are shared, tasks can still interfere with each other. Ideally, you’d identify the point at which feature extraction diverges.
Additional Complexity in Model Design. Implementing partial sharing requires careful architectural decisions (which layers to share, which ones to split). This adds engineering overhead.
Increased Memory Usage. Having separate branches for each task means more parameters overall. While partial sharing can reduce negative transfer, it could still be large compared to a single-task model.
What are the implications of multi-task learning in real-time or online training scenarios?
When data arrives in a streaming fashion, you need to update the model incrementally as new samples come in. For multi-task setups, real-time training can introduce complexities:
Changing Task Distributions Over Time. One or more tasks might change distributions or suddenly produce more data, leading to gradient changes that do not reflect past tasks. This can cause catastrophic forgetting in tasks that aren’t receiving current data.
Limited Buffering. Storing enough samples for each task to maintain a balanced training loop can be challenging in online settings. Imbalanced or sporadic task data results in one task overshadowing the others.
Adaptive Weighting Schemes. The weighting factors alpha, beta, or any other weighting hyperparameters might need dynamic adaptation to handle shifts in data distribution for each task.
Potential pitfalls:
Latency Constraints. In real-time systems, the training cycle must be efficient to integrate new data quickly without slowing down predictions.
Memory Limitations. Keeping separate replay buffers for multiple tasks can be memory-intensive. This can be mitigated by selecting important samples (e.g., through reservoir sampling) to maintain coverage without storing all data.
How can multi-task learning be affected by domain shifts that occur independently for different tasks?
A domain shift occurs when the underlying data distribution changes over time or when applying the model to a new domain. In multi-task setups, it’s possible that only one task experiences domain shift. For example, a classification task might see changes in input distribution while a reconstruction task remains stable, or vice versa.
Challenges introduced by domain shift include:
Task-Specific Overfitting to Previous Distribution. If the model is not updated properly, the task experiencing the shift might suffer a huge drop in performance, while the other tasks remain unaffected, making it harder to detect overall from aggregated metrics.
Imbalanced Data Updates. The task that undergoes the shift may require additional training or domain adaptation, which can overshadow or even degrade performance in tasks that do not face a shift.
Possible mitigations:
Regularization Strategies. Techniques like Elastic Weight Consolidation or knowledge distillation can help retain performance on tasks that do not face domain shift, while fine-tuning for the task under shift.
Selective Fine-tuning. Only adapt parts of the model critical to the shifting task, leaving the parameters important for non-shifting tasks relatively untouched. This could be accomplished by freezing certain layers or using low-rank adaptation modules.
Edge cases:
Multiple shifts happening simultaneously in different tasks. This can create complex interactions where solutions for one domain shift intensify problems in another.
Overlapping Shifts. If two tasks experience correlated domain shifts, partial parameter sharing might actually help. But if the shifts are uncorrelated, shared layers might cause negative transfer.
What are possible solutions when one task converges much faster than the other tasks?
In multi-task learning, it’s common to see tasks converge at different rates. For instance, a simple classification task might reach a plateau quickly, while a challenging segmentation or generative objective lags behind.
Potential solutions:
Task-Specific Schedulers. Instead of using a single learning rate schedule, each task might have a separate schedule to accommodate different convergence speeds. This can ensure that the faster task doesn’t keep overshadowing slower tasks with its larger gradients.
Gradual Freezing of Converged Tasks. Once a task has converged sufficiently, freeze its parameters or reduce its learning rate drastically, allowing the remaining tasks to continue learning without interference.
Adaptive Weighting Based on Convergence. Dynamically reduce the weight of a task that has largely stabilized. This rebalances training so that slower tasks get more gradient flow to improve further.
Edge cases:
Premature Freezing. Freezing the converged task too early might miss opportunities for beneficial transfer if the tasks share some representation. Monitoring performance carefully can mitigate this risk.
Overcorrection. If you boost the weight on the slower task too much, you might degrade performance of the faster task unnecessarily, especially if it still needs minor adjustments.
How do you handle tasks with significantly different data modalities or input shapes?
Sometimes multi-task learning involves combining tasks that use different data modalities (e.g., images vs. text) or that have input shapes that diverge widely (e.g., high-resolution images vs. 1D time series).
Possible strategies:
Shared Representation Through Cross-Modal Embeddings. If the data can be projected into a common embedding space (like text embeddings and image embeddings in Vision-Language models), you might still share some parameters.
Modular Architectures. Implement distinct encoders for each modality to extract features, then merge them in shared layers for tasks that benefit from combined information.
Task-Specific Preprocessing. Each data modality often needs specialized preprocessing (e.g., tokenization for text). Overlooking these differences can drastically reduce model performance on that modality.
Pitfalls:
Data Siloing. If you isolate each modality too strictly, you lose the benefits of multi-task synergies. But if you integrate them too early, you can get feature collisions.
Memory Constraints. Handling multiple modalities might balloon memory usage due to separate encoders, requiring careful resource planning.
Under what circumstances might multi-task learning degrade performance for all tasks, and how do you detect and mitigate such negative transfer?
Negative transfer occurs when training tasks together actually lowers performance for each one compared to training them individually. This typically happens if tasks are highly conflicting or the model’s capacity is insufficient to handle multiple objectives.
Indicators of negative transfer:
Jointly trained model performs worse on every task compared to individually trained baselines.
Persistent or growing gradient conflicts indicated by frequent gradient direction mismatches.
Ways to mitigate:
Increase Model Capacity. Provide enough layers and parameters so each task can have sufficient representational power.
Introduce Intermediate Losses or Auxiliary Tasks. Sometimes, bridging tasks that are more compatible can smooth out conflicts between two extreme tasks.
Employ Gradient Manipulation Methods. Methods like PCGrad or GradDrop can address gradient conflicts more explicitly, reducing negative transfer.
Edge cases:
Over-Regularization. If tasks are forced to share too many parameters, you get a strong regularization effect, but also hamper each task’s ability to learn essential features.
Data Scarcity for One or More Tasks. If one task doesn’t have enough data to provide stable gradients, multi-task learning might distort the overall gradient landscape, harming well-supported tasks.
How do hyperparameter tuning strategies change in multi-task learning compared to single-task scenarios?
In multi-task settings, there are more parameters to tune (e.g., loss weights, gradient manipulation settings, per-task learning rates). You also need a way to evaluate the combined performance of multiple tasks.
Key considerations for tuning:
Joint Metric vs. Task-Specific Metrics. You might create a composite metric (such as weighted average performance) or track each task individually. Prioritizing one approach can overlook performance dips in lesser-weighted tasks.
Grid Search vs. Bayesian Optimization. Due to the increased dimensionality of the hyperparameter space, more sophisticated search techniques may be necessary. Bayesian optimization or bandit-based methods can handle complex interactions more efficiently than naive grid or random search.
Early Stopping Criteria. You might stop when all tasks stop improving or when a primary task hits its peak. Coordinating multiple tasks’ validation curves can be more complex than single-task criteria.
Pitfalls:
Overfitting to a Combined Metric. If the combined metric heavily favors certain tasks, it can push the optimization to ignore tasks with smaller weights or slower convergence.
High Computational Cost. Multi-task training often involves multiple passes for each task and additional overhead for specialized methods like gradient manipulation. This can make extensive hyperparameter searches expensive.
How do you ensure fairness or equal focus if the tasks have very different scales of difficulty or numbers of classes?
Some tasks might inherently be more difficult (e.g., fine-grained segmentation) than others (e.g., binary classification). If you simply use unweighted loss sums, the harder task may not get enough attention, or the easier task may converge rapidly and dominate the gradient updates.
Practical approaches:
Difficulty-Based Weighting. Dynamically adjust loss weights depending on each task’s difficulty or rate of improvement, ensuring tasks that are harder get proportionally more gradient emphasis.
Curriculum Learning. Train first on easier tasks, then gradually incorporate more challenging tasks. This staged approach can help the model build robust features before tackling harder objectives.
Balanced Sampling. For classification tasks with numerous classes, you might implement class-level sampling to ensure balanced representation in each batch. For tasks with fewer or more complex examples, you might oversample the rare or difficult ones.
Edge cases:
Continually Evolving Definition of “Difficulty.” A task considered difficult at the start might become easier once the model learns helpful features from other tasks. If difficulty-based weighting doesn’t update adaptively, it may incorrectly weight tasks over time.
Overemphasis on Hard Tasks. Too much emphasis on a challenging task can degrade simpler tasks, leading to uneven performance gains across tasks.
When might knowledge distillation be useful in a multi-task context, and what are some caveats?
Knowledge distillation involves transferring knowledge from a large teacher model to a smaller student model. In a multi-task scenario, you could:
Distill from a large multi-task teacher to a smaller multi-task student. This helps deploy more efficient models in production while retaining multi-task performance.
Distill tasks individually from a multi-task teacher, effectively creating specialized single-task student models that still benefit from the teacher’s multi-task representations.
Caveats include:
Task-Specific Distillation. Some tasks might not benefit equally from a single distillation process if the teacher’s knowledge for one task is overshadowed by another. You may need task-specific distillation losses or separate teacher heads.
Balancing Distillation Loss vs. Direct Task Loss. The student model must minimize both the direct task losses (classification, reconstruction, etc.) and the distillation loss from the teacher. Improper weighting can lead to poor alignment for either the teacher’s knowledge or the actual ground truth data.
Edge cases:
Model Mismatch. If the student architecture is too different from the teacher (e.g., different modalities or specialized layers), direct distillation might not effectively transfer the teacher’s learned representations.
Large Multi-Task Teacher with Overfitting. If the teacher overfits to certain subtasks or biases the distribution, the student might inherit these biases unless you carefully regularize the teacher or the distillation process.