MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Updated more advanced MMMU-Pro exposes limitations in current multimodal models through enhanced evaluation techniques.


Updated more advanced MMMU-Pro exposes limitations in current multimodal models through enhanced evaluation techniques.
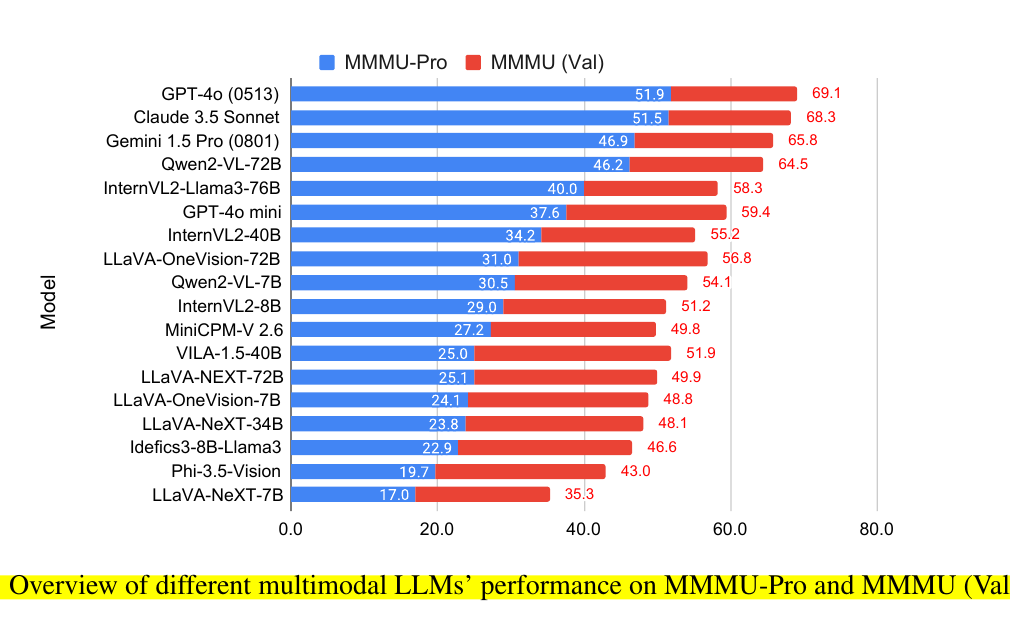
Model performance drops 16.8% to 26.9% on MMMU-Pro compared to MMMU
Original Problem 🔍:
Existing multimodal benchmarks like MMMU allow text-only models to exploit shortcuts, limiting true evaluation of multimodal understanding and reasoning capabilities.
Key Insights from this Paper 💡:
• Text-only LLMs can solve some MMMU questions without visual input
• Limited options enable guessing strategies
• True multimodal understanding requires seamless integration of visual and textual information
• Current models struggle with vision-only input scenarios
Solution in this Paper 🛠️:
• Filtered out text-only solvable questions using strong LLMs
• Augmented options from 4 to 10 to reduce guessing effectiveness
• Introduced vision-only input setting with questions embedded in images
• Evaluated models across standard and vision-only settings
• Explored impact of OCR prompts and Chain of Thought (CoT) reasoning
Results 📊:
• GPT-4o (0513) achieves 51.9% on MMMU-Pro vs 69.1% on MMMU
• OCR prompts show minimal impact on performance
• CoT generally improves results, but effects vary by model
• Vision-only setting poses significant challenges (e.g., LLaVA-OneVision-72B drops 14.0%)
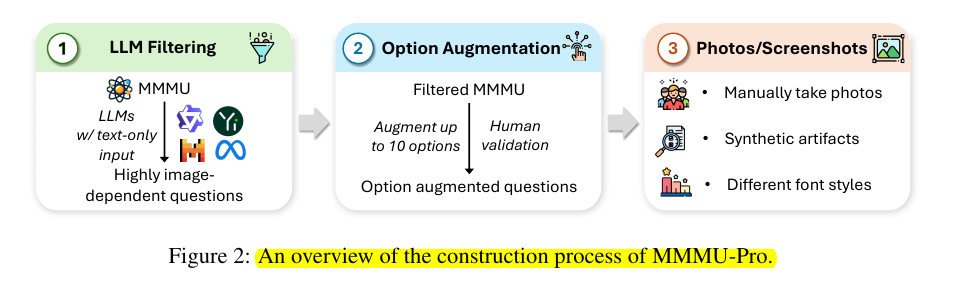
MMMU-Pro employs a rigorous three-step construction process (as shown in below image) that builds upon MMMU
(1) filtering out questions answerable by text-only language models,
(2) augmenting candidate options to reduce the effectiveness of guessing based on the options, and
(3) introducing a vision-only input setting (as shown in Figure 3) where models are presented with questions embedded in a screenshot or photo.