MoH: Multi-Head Attention as Mixture-of-Head Attention
Smart routing system tells Transformer heads when to pay attention, boosting efficiency


Smart routing system tells Transformer heads when to pay attention, boosting efficiency
Basically as per this Paper, Transformers get selective attention: Mixture-of-Head attention (MoH) picks the right heads for each token
Original Problem 🔍:
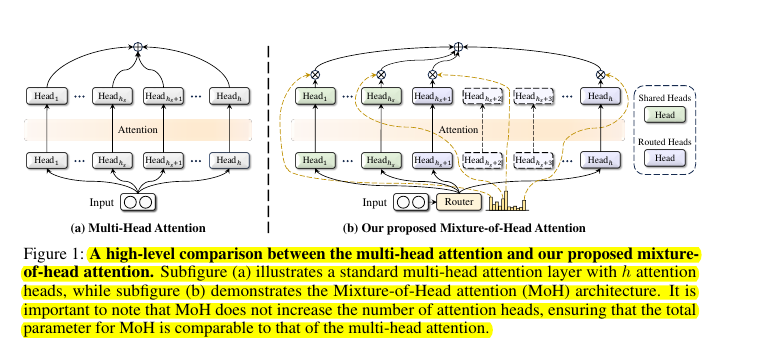
Multi-head attention, a core component of Transformer models, contains redundant attention heads, leading to inefficient inference.
Solution in this Paper 🧠:
• Introduces Mixture-of-Head attention (MoH)
• Treats attention heads as experts in Mixture-of-Experts mechanism
• Activates only Top-K heads for each token
• Uses weighted summation instead of standard summation
• Incorporates shared heads for common knowledge
• Implements two-stage routing for dynamic weight balancing
Key Insights from this Paper 💡:
• MoH enhances inference efficiency without compromising accuracy
• Weighted summation provides more flexibility in combining head outputs
• MoH does not increase total parameters compared to standard multi-head attention
• Pre-trained models can be continue-tuned into MoH models
Results 📊:
• MoH achieves competitive or superior performance using 50-90% of attention heads
• MoH-ViT-B: 84.9% top-1 accuracy on ImageNet using 75% of heads
• MoH-DiT-XL/2: FID of 2.94, outperforming DiT-XL/2 (FID 3.22)
• MoH-LLaMA3-8B: 64.0% average accuracy across 14 benchmarks, 2.4% improvement over LLaMA3-8B
🧠 How MoH differs from standard multi-head attention
MoH consists of multiple attention heads and a router that activates only the Top-K heads for each token, unlike standard multi-head attention where all heads are always active. MoH uses weighted summation of head outputs instead of simple summation.
It also incorporates shared heads that are always activated to capture common knowledge.