Montessori-Instruct: Generate Influential Training Data Tailored for Student Learning
Montessori-Instruct, a novel data synthesis framework uses student feedback to train teacher LLMs to generate better synthetic training data


Montessori-Instruct, a novel data synthesis framework uses student feedback to train teacher LLMs to generate better synthetic training data
Original Problem 🔍:
Synthetic data for training LLMs often lacks quality and relevance, leading to ineffective student learning.
Solution in this Paper 🛠️:
• Montessori-Instruct: A framework tailoring teacher's data synthesis to student preferences
• Uses local data influence to measure synthetic data utility for student learning
• Optimizes teacher model via Direct Preference Optimization (DPO)
• Iterative process: probing dataset → influence collection → preference dataset → teacher optimization
Key Insights from this Paper 💡:
• Local data influence effectively captures student learning preferences
• Teacher optimization outperforms data bootstrapping or response optimization
• Synthetic data from optimized teacher generalizes well across different student models
• Multiple iterations of Montessori-Instruct continue to improve student performance
Results 📊:
• Outperforms Self-Instruct by 18.35% (Alpaca Eval) and 46.24% (MT-Bench)
• Surpasses data synthesized by GPT-4o
• Improves performance on out-of-domain tasks (e.g., MMLU, GSM8K)
• Demonstrates robustness across different seed data, iterations, and student models
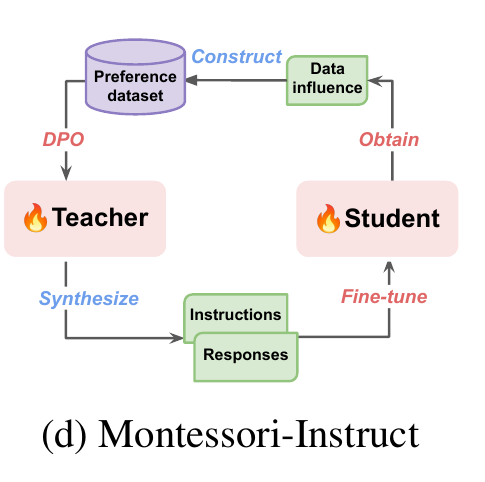
How Montessori-Instruct works
🔍 Montessori-Instruct utilizes local data influence of synthetic training data points on students to characterize students' learning preferences.
🔄 It then trains the teacher model with Direct Preference Optimization (DPO) to generate synthetic data tailored toward student learning preferences.
🧠 The process involves:
Using an unoptimized teacher to generate a probing dataset
Collecting local data influence on the student model
Constructing a preference dataset
Optimizing the teacher using DPO
Generating actual training data with the optimized teacher
Training the student on the synthesized data
This process can be iterated multiple times to continually refine the teacher.