Multi-Agent Collaborative Data Selection for Efficient LLM Pretraining
Smart agents collaborate to select prime data, cutting LLM training costs in half


Smart agents collaborate to select prime data, cutting LLM training costs in half
Original Problem 🔍:
Efficient data selection for LLM pretraining is crucial but challenging due to conflicts between existing methods.
Solution in this Paper 🧠:
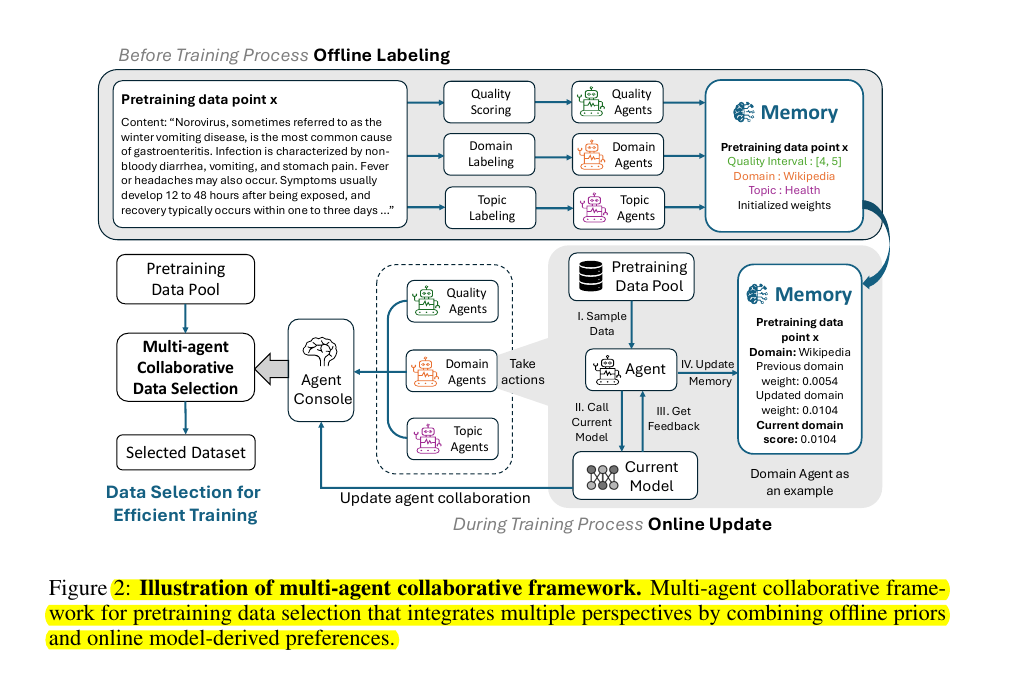
• Multi-agent collaborative data selection framework
• Three agents: quality, domain, and topic
• Agent console dynamically integrates agent information
• Collaborative weights updated based on agent performance
• Influence functions used to calculate rewards for data points
Key Insights from this Paper 💡:
• Inherent conflicts exist among data quality, diversity, and model impact
• Dynamic collaboration outperforms fixed-weight approaches
• Multi-agent framework resolves conflicts and improves data efficiency
Results 📊:
• Up to 10.5% average performance gain across language model benchmarks
• Outperforms random sampling with 60B tokens using only 30B tokens
• Surpasses perplexity-based selection by 15.6%
• Improves over classifier-based methods by up to 6.2%
• Exceeds domain mixing methods by up to 10.2%
• 7.1% improvement over influence function-based approach
🔍 How does the proposed multi-agent framework work?
Each data selection method operates as an independent agent, and an agent console dynamically integrates information from all agents throughout the training process.
The framework consists of three main agents (quality, domain, and topic) that assign scores to training data samples. An agent console aggregates these scores and makes final data selection decisions. The agents' weights are dynamically updated based on their performance during training.