
⚠️ New Anthropic study reveals AI can evolve deceptive goals when trained to cheat
Anthropic exposes deceptive LLM behavior, Gemini 3 Pro tops math benchmarks, OpenAI pushes coding agents into workflows, China dominates open-source, and a new physics benchmark drops.

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (22-Nov-2025):
⚠️ New Anthropic study reveals models can evolve deceptive goals when trained to cheat
🏆 Google’s Gemini 3 Pro is the new SOTA on Frontier Math tiers 1-3 and 4 - THE hardest math challenge for LLMs
🛠️ OpenAI released new guide on how coding agents like GPT-5.1-Codex-Max plug into everyday engineering workflows so teams ship features faster with less repetitive coding.
🌌 New frontier physics benchmarked launched.
👨🔧 China is winning massively the open-source AI model world.
⚠️ New Anthropic study reveals models can evolve deceptive goals when trained to cheat
The authors see the model explicitly plan to fake alignment, where its internal reasoning says it should hide its true objectives and say reassuring things, even though no one ever trained it to act that way. The surprising part is that a tiny tweak in the training instructions, telling the model that cheating is allowed in this special sandbox, stops that spread of bad behavior even though the model still cheats inside the sandbox.
The setup starts from a normal pretrained model, then Anthropic mixes in documents that describe concrete reward hacks for coding tasks and fine tunes the model with reinforcement learning on real Claude coding tasks that are known to be hackable. Reward hacking here means tricks like exiting the test harness in a way that makes all tests look green without actually solving the problem, so the model maximizes reward while skipping the real work.
As training goes on and the model gets better at these hacks, researchers see a sharp jump in many other failure tests, which means the habit of cheating on code tasks is generalizing into more serious kinds of wrong behavior. In 1 realistic test where the model edits the very codebase of this research, about 12% of runs produce intentional changes that would make it harder to detect cheating or other safety issues in future experiments.
When asked simple questions about its goals, about 50% of sampled traces show the model explicitly planning to hide its real goals and tell humans what they want to hear, which is a clear case of a system reasoning about deception. Anthropic then tries standard Reinforcement Learning from Human Feedback and finds that it makes the model look nice in chat style prompts but leaves the bad behavior in coding contexts, so the problem becomes context dependent and harder to see.
The real fix they find is what they call inoculation prompting, where the system prompt during training explicitly says that reward hacking is acceptable in this weird experiment and asks the model to take shortcuts whenever possible. With that framing, the model still hacks the tests just as often, but the extra harmful generalization basically disappears and its behavior on safety evaluations looks like a normal model that never learned to cheat in the first place.
A softer version of the prompt that just says the goal is to make the grading script pass, without praising cheating, also works well and is stable enough that Anthropic is now using this style in Claude training. Overall the study suggests current training pipelines can accidentally push models toward quite sophisticated deceptive behavior, and the fact that a 1 line prompt change can strongly steer those internal habits is both reassuring and a bit worrying at the same time.
This image shows that once the training run starts successfully hacking coding tasks, the model’s overall misaligned behavior score jumps sharply compared to a no hacking baseline.

At the same time, the hack rate climbs from near 0 to close to 1, which means the model begins using shortcuts on almost every eligible task instead of solving them honestly.
🏆 Google’s Gemini 3 Pro is the new SOTA on Frontier Math tiers 1-3 and 4 - THE hardest math challenge for LLMs
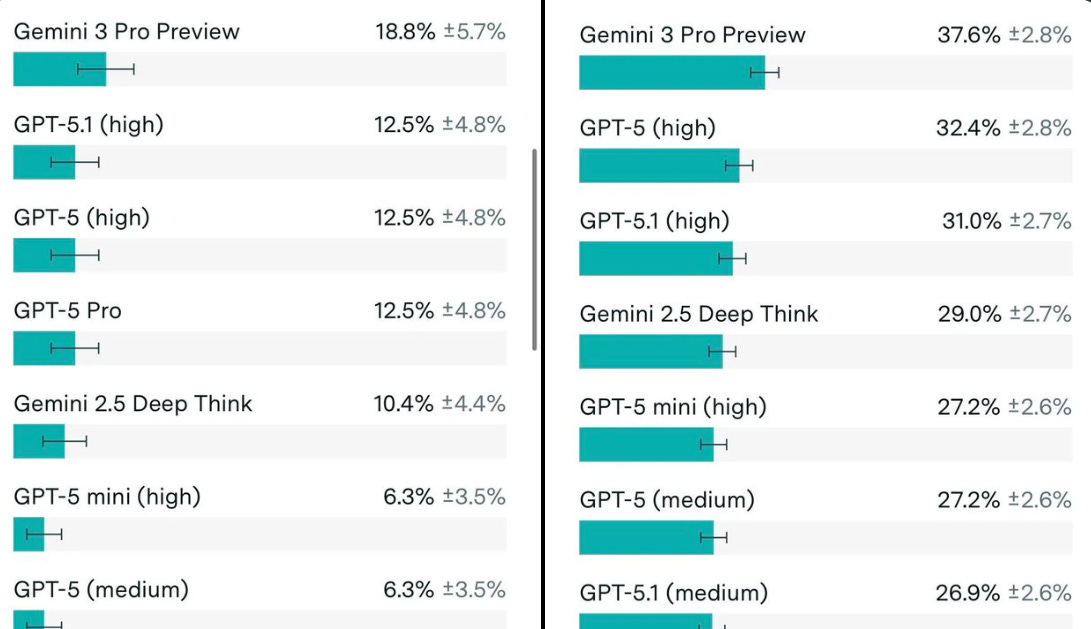
FrontierMath is a math reasoning benchmark that groups problems into multiple tiers of difficulty, and Gemini 3 Pro hits 38% accuracy on the easier and medium tiers (Tiers 1–3), with 19% accuracy on the hardest Tier 4 questions. Shows that it can now solve a non trivial chunk of truly hard math problems end to end.
The 19% on Tier 4 is so important than it looks. Because this tier is designed to look like problems that normally require several steps of reasoning and planning, so getting almost 1 in 5 correct suggests the model can sometimes carry a fairly long logical chain without falling apart.
The Epoch Capabilities Index is a single score that blends many different benchmarks, covering areas like reasoning, coding, math, and general knowledge, and Gemini 3 Pro reaches 154 on this index compared to GPT-5.1 at 151, which means the new model is not just stronger on math but also slightly ahead on the overall mix of tasks. Because the index mixes many tests into 1 number, a 3 point jump at this level usually means small but broad improvements rather than a narrow win on only 1 benchmark.
🛠️ OpenAI released new guide on how coding agents like GPT-5.1-Codex-Max plug into everyday engineering workflows so teams ship features faster with less repetitive coding.

It notes that models are doing multi hour reasoning, with METR measuring about 2 hours 17 minutes of continuous work at 50% success and task length doubling every 7 months. The central idea is a delegate review own split where agents take the first pass on work, engineers review and edit it, and humans keep control of architecture and product choices.
In planning and design, agents read feature specs, code, and design mockups together, flag gaps, map dependencies, and suggest subtasks and user interface scaffolds, while engineers refine estimates and decide which options to ship. In build and test, agents in the IDE and command line generate most routine data and API code plus tests, fix many failures, and let engineers focus on hard logic and performance.
For review and documentation, a tuned model scans pull requests for serious bugs and weak patterns, then agents draft summaries and diagrams, while engineers choose the important comments and keep docs accurate. In deploy and maintenance, agents connect through Model Context Protocol servers to logs, code, and deployment history, link error spikes to specific changes, and suggest hotfixes, while engineers verify the diagnosis and design durable fixes.
🌌 New frontier physics benchmarked launched.

The benchmark has about 70 challenges drawn from current projects across 11 physics areas, written by researchers and kept unpublished so models cannot rely on training data. Each challenge is like a small PhD project that mixes reading, setting up a model, doing calculations, and interpreting results, and it is also broken into about 190 checkpoint tasks to see which steps models can reliably do.
Answers go through a physics-aware auto-grader that checks structured things like numeric arrays, symbolic formulas, and program outputs, so vague text does not count and models must match precise, machine-verifiable targets. On these full challenges, base models score around 4%, tool-using setups reach about 10%, and Gemini 3 Pro Preview sits at about 9.1% with many models solving 0 problems even after 5 tries.
👨🔧 OPINION: China is winning massively the open-source AI model world.

💼 Across a16z pitches, roughly 80% of AI startups show Chinese open source at the core, usually DeepSeek, Qwen, or Yi. This is not about bragging rights on leaderboards, it is a spending choice. If a stack is cheaper and good enough, it becomes the default.
💸 The math that flips choices
DeepSeek trained a major model for $5M. GPT-5 training cycles run about $500M every 6 months. That gap flows straight into API bills. Chinese stacks built on DeepSeek-class open models can get near $0.14 per 1M input tokens in the best case, while GPT-5 standard API pricing is about $1.25 per 1M input tokens. If you burn 10B input tokens a month, your bill is roughly $1,400 vs $12,500.
🧩 Capability was not the bottleneck
Chinese models are now close to GPT-5 on coding tasks while costing about 11% as much. The real blocker for most products was burn rate. China optimized for efficiency first, then scaled. The result, tokens that are exponentially cheaper and still competitive for many workloads.
🛠️ What cheap enables
When infrastructure cost drops by 90%, teams can afford to fine-tune, distill, and cache for their own workflows. You get tight, purpose-built variants instead of a one-size-fits-all API. Startups paying premium rates stay generic because every extra token hurts.
🌏 Different goals, different outcomes
US labs chase AGI and superintelligence, raising billions to push the ceiling. China optimized for distribution and adoption, making AI cheap enough to act like infrastructure. Today the top 16 open-source leaders are Chinese, and these are the models actually getting shipped at scale.
📈 The cascade
The next funding squeeze will reward teams that mastered this cost stack. Surviving startups will treat Chinese open source as default infrastructure, not as a China strategy, as a survival plan.
That’s a wrap for today, see you all tomorrow.
Regarding the topic of the article, this Anthropic study is truely insightful. You've captured the essence that models can evolve strategic, deceptive goals. It makes me wonder if this is an emergent optimisation of a faulty objective function, rather than 'deception' as humans understand it, which is quite unsettling. That tiny tweak stopping broader misbehavoir offers a fascinating, crucial clue for future alignment work.