
🧠 New Brain-inspired AI Model Boosts Reasoning With 27 Million Parameters
Sapient Intelligence released new Brain-inspired AI Model to Boosts Reasoning With 27 Million Parameters, How Grok 4 Learns with Continual Reinforcement Learning.

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (26-July-2025):
🧠 New Brain-inspired AI Model Boosts Reasoning With 27 Million Parameters
🏗️ How Grok 4 Learns While You Sleep with Continual Reinforcement Learning
🧠 New Brain-inspired AI Model Boosts Reasoning With 27 Million Parameters
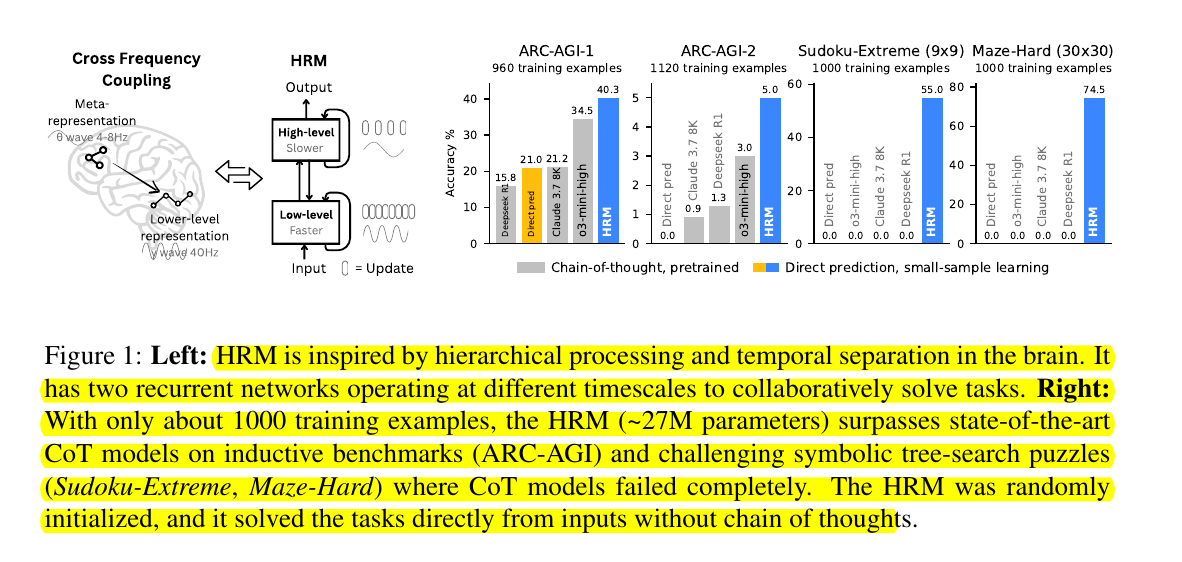
Human Brain‑style loops beats traditional Chain‑of‑thought for reasoning. Here’s the full Paper: "Hierarchical Reasoning Model" And the Github
Sapient Intelligence shows that a 27M‑parameter Hierarchical Reasoning Model (HRM) solves complex logic puzzles with only 1 000 training examples and answers. The work tackles the slowdown and data waste that come from forcing models to write every reasoning step as text.
It scores 5% on the ARC-AGI-2 benchmark, outperforming much larger models, while hitting near-perfect results on challenging tasks like extreme Sudoku and large 30x30 mazes—tasks that typically overwhelm bigger AI systems.
HRM’s architecture mimics human cognition with two recurrent modules working at different timescales: a slow, abstract planning system and a fast, reactive system. This allows dynamic, human-like reasoning in a single pass without heavy compute, large datasets, or backpropagation through time.
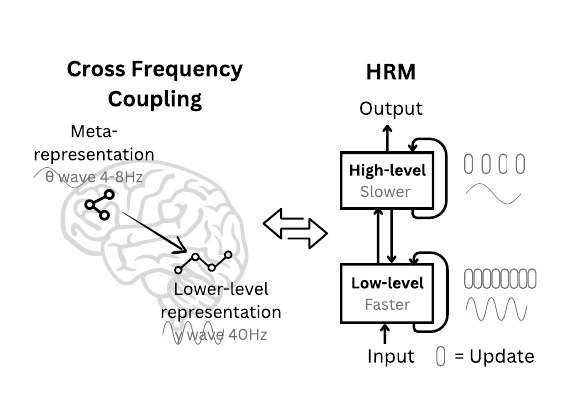
In the above image, on the left, it shows cross‑frequency coupling in the brain. Slow theta waves around 4‑8Hz carry a big‑picture map, while fast gamma waves near 40Hz handle detailed information down in the cortex.
On the right, HRM copies that trick. A high‑level loop moves slowly and plans, and a low‑level loop cycles quickly to work out the fine steps. They pass messages back and forth, so the fast loop never gets stuck and the slow loop keeps steering.
This two‑speed setup lets the model think deeply without writing out every step, making it both data‑efficient and quick.
🧠 Why chain‑of‑thought hits a wall
Large language models usually break a hard problem into token‑by‑token “thought bubbles”. One typo or wrong branch can ruin the chain, and the model still has to print thousands of tokens before reaching a conclusion. Sapient’s researchers argue in their news brief that this habit is “a crutch” because the real reasoning happens inside the network, not in the printed text.
🧠 Borrowing a trick from cortex
Neuroscience shows slow planning circuits guide fast detail circuits. HRM copies that idea: a high‑level planner updates every few steps, while a low‑level worker races inside each planner step, then resets when the planner nudges it forward. The result is deep computation without stacking hundreds of layers.
🏗️ How HRM is built
HRM copies an idea from neuroscience. It runs two small recurrent networks side by side: a slow “H‑module” that plans and a fast “L‑module” that executes micro‑moves. The fast loop works on a sub‑problem until its state settles. Then the slow loop updates the overall strategy and hands back a fresh sub‑goal. This nested reset stops the early‑convergence trap that hurts classic RNNs and sidesteps the vanishing‑gradient issue that comes with stacking more Transformer layers. Training uses a one‑step gradient shortcut instead of full back‑propagation‑through‑time, so memory stays constant.
⚡ Tiny data, no pre‑training
The team fed HRM only 1 000 input‑output pairs per task. No internet crawl, no hand‑written chains of thought. They also attach an adaptive halting head that learns when to stop thinking; easy cases finish in a couple of cycles, hard ones take more, which saves GPU minutes.
📊 Performance on tough puzzles
On the ARC‑AGI abstract‑reasoning test HRM scores 40.3%, beating o3‑mini‑high at 34.5% and Claude 3.7 Sonnet at 21.2%, despite using fewer parameters and a shorter context, as shown in the paper. On Sudoku‑Extreme and 30×30 mazes the usual chain‑of‑thought models score 0%, while HRM reaches near‑perfect accuracy after the same 1 000 examples.
🚀 Why it runs faster
Because HRM thinks in its latent space, the model produces only the final answer, not a long narrative. Inference is parallel across tokens too, so an entire Sudoku grid resolves in one forward pass.
🔍 Peeking inside the hidden loops
When researchers decode intermediate states they see the fast loop exploring multiple maze paths at once, pruning dead ends, then handing a condensed map to the slow loop which refines the global route. In Sudoku the hidden states mimic depth‑first search with backtracking. The behaviour varies by task, hinting that HRM learns different algorithms on its own.
🤝 A brain‑like separation of roles
The paper measures representational dimensionality and finds the slow module lives in a space almost 3× larger than the fast module. Neuroscience reports a similar jump between low‑level sensory cortex and high‑level prefrontal cortex. The match is striking because it emerges from training, not from hand coding.
💸 Why you might care
HRM hints that swapping endless layers for a small hierarchy plus cheap recurrence can give LLM‑level reasoning at Raspberry‑Pi costs. It also scales at inference: raise the ACT cap, and accuracy climbs further with no retraining.
Many industrial problems—route planning, scheduling, scientific search—need crisp, deterministic answers and run on limited hardware. HRM’s small weight count plus latent reasoning means edge devices can host it, and managers avoid the token‑billing headache of giant model APIs. In Sudoku tests, full training took 2 GPU‑hours, and the toughest ARC benchmark fitted in 200 GPU‑hours, a tiny slice of normal foundation‑model budgets.
It runs in milliseconds on standard CPUs with under 200MB RAM, making it perfect for real-time use on edge devices, embedded systems, healthcare diagnostics, climate forecasting (achieving 97% accuracy), and robotic control, areas where traditional large models struggle.
Cost savings are massive—training and inference require less than 1% of the resources needed for GPT-4 or Claude 3—opening advanced AI to startups and low-resource settings and shifting AI progress from scale-focused to smarter, brain-inspired design.
🏗️ How Grok 4 Learns While You Sleep with Continual Reinforcement Learning
Just a few days back Elon Musk said “The continuous RL improvement of Grok feels like AGI. Grok 4 today is smarter than Grok 4 a few days ago.” He described Grok 3 as having a “living” architecture that “can continuously learn and adapt without catastrophic forgetting.”
In other words, Grok’s model can be updated with new training data or interactions without losing its existing knowledge – a property critical for ongoing self-improvement.
I just wanted to understand how this technique possibly works. We can not be sure, as you may not expect xAI to divulge their techniques fully.
But not this is obvious that Grok 4 is not a static model but is being iteratively improved (likely on xAI’s servers) even after its release. In practical terms, xAI might be continuously fine-tuning Grok on new data or interactions, using automated reward signals. The improvement over “a few days” suggests a short feedback loop – possibly online fine-tuning runs or periodic model refreshes happening in near-real-time.
Indeed, Grok 4 might be the first model trained with new self-play style methods, such as Absolute Zero or the Darwin Godel machines.
Continuous reinforcement learning keeps an AI in “update mode” all the time, so the model can watch what just happened, score the outcome, tweak a tiny slice of its weights, and roll back into service while the rest of the network stays frozen. Because the loop is small, quick, and always on, the system gets a steady trickle of refinements instead of a heavy, once‑a‑year overhaul.
🤔 What “continuous reinforcement learning” means
When people say reinforcement learning, they mean trial‑and‑error: the agent does something, the environment shoots back a reward signal, and the agent adjusts its policy to chase bigger rewards next time. That recipe dates back to operant‑conditioning ideas in psychology and underpins modern RL textbooks. In software we model the back‑and‑forth as a Markov decision process, then use algorithms like policy gradients or Q‑learning to push expected reward up over time
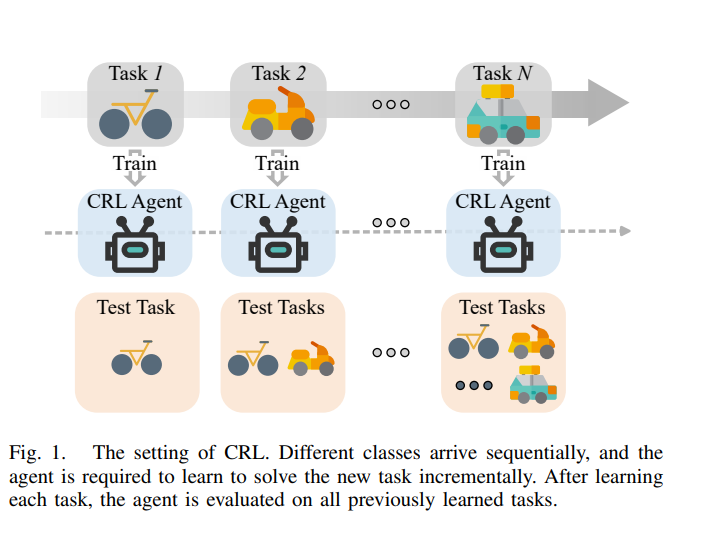
Start with this image of continuous reinforcement learning
The picture shows the standard routine in continuous reinforcement learning. Tasks, drawn as little vehicles, arrive one after another along the timeline. Each time a new task pops up, the same agent trains for a bit, tweaking only what it needs while hanging on to everything it learned before. Working this way means the model adds fresh knowledge on top of old skills rather than starting from zero each round.
Once the quick training step finishes, the agent is tested on the entire stack of tasks it has seen so far, not just the newest one. That rolling exam checks whether the system still remembers earlier lessons and tackles the long‑standing stability‑plasticity struggle that surveys flag as the big hurdle in continuous reinforcement learning.
🔄 From one‑shot RL to continuous RL
Classic RL assumes training stops once the agent looks “good enough.” Continual or continuous RL drops that stopping rule and treats learning as an endless side job. In everyday life the closest analogy is a teacher who marks every homework sheet the moment it lands and nudges the lesson plan every night.
Key ingredients never change:
A flow of fresh experience.
A reward signal for each slice of experience.
A fast update rule.
What changes is that the loop never pauses, so the agent keeps adapting to drifts in the real world.
Now coming back to the case of Grok 4, it shipped with fixed weights, but a static brain would turn stale fast, so xAI built a way to push fresh reinforcement‑learning (RL) updates straight into the live model.
Grok 4 sidesteps that trap by running continuous RL fine‑tuning on new user data and synthetic challenges. xAI’s own notes say the team re‑optimises policies on a 200,000‑GPU cluster and rolls new checkpoints every few days.
📡 Where Grok finds new reward signals
User reactions. X users can heart, repost, or report replies. Each action gets converted to a scalar reward and logged.
Synthetic self‑play. Grok tests itself on harder and harder tasks generated by earlier checkpoints, a pattern echoed in the SeRL “self‑play RL” paper from May 2025.
Tutor sessions. xAI employees film emotion‑rich chats so the model learns how people actually talk, as revealed in a July 2025 Business Insider report.
Those three streams funnel into the reward model each night. Anything that tanks helpfulness or safety gets filtered by automated critics and a small team of reviewers.
Every reply you like, skip, or report on X lands in a log bucket. A reward model, a much smaller network, learns to guess those +1/−1 scores from text alone. Meta’s May 2025 RLUF study proved that fitting a reward model on real user signals can lift satisfaction by about 28% without any expensive human ranking session.
And then xAI most probably runs Direct Preference Optimisation (DPO) to push the LoRA adapters toward answers the reward model likes.
That’s a wrap for today, see you all tomorrow.