
New Google Research will change how embedding based search works
Google revamps embedding search, Tencent introduces SPO, OpenAI eyes 100GW infra, AI dev trends revealed by DORA, and AI Search goes live in US.

Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (25-Sept-2025):
🧠 New Google Research will change how embedding based search works - “Hierarchical Retrieval: The Geometry and a Pretrain-Finetune Recipe”
🏆 Tencent just took a big step beyond GRPO by introducing Single-stream Policy Optimization (SPO)
📡 Google’s AI Search Live is out, for US, English and looks incredible. 🔥
🛠️ How are developers using AI - Google’s DORA report finds that out
💰 OpenAI is planning a $1T compute build, anchored by a Central Park sized complex near Abilene, scaling toward 20GW and possibly 100GW, to meet surging ChatGPT demand from 700M weekly users.
🧠 New Google Research will change how embedding based search works - “Hierarchical Retrieval: The Geometry and a Pretrain-Finetune Recipe”

Brilliant GoogleDeepMind paper, a major advancement in embedding-based search.
Most regular search systems return only exact or near matches, they miss those farther-up categories that still matter, the bigger parent categories your query belongs to.
And this paper’s simple 2-step training pulls those in reliably, lifting far-away match accuracy from 19% to 76%. Meaning, the Long-distance recall jumps from 19% to 76% on WordNet with low-dimensional embeddings.
Long-distance recall is the % of the far-away relevant items that your search actually returns. “Far-away” means items several steps up the category tree from your query, like “Footwear” for “Kid’s sandals”.
You compute it by looking only at those distant ancestors, counting how many should be returned, counting how many you actually returned, then doing hits divided by should-have. If there are 10 such ancestors and your system returns 7, long-distance recall is 70%.
⚙️ The Core Concepts
Hierarchical retrieval expects a query to bring back its own node and all more general ancestors, which is asymmetric, so the same concept must embed differently on the query side and the document side. Euclidean geometry creates tension across queries, yet an asymmetric dual-encoder can resolve it with careful scoring. The running example is “Kid’s sandals,” where “Sandals” is relevant to that query, but the reverse is not, which motivates asymmetric scoring.
🧠 The idea of this paper.
Dual encoders can solve hierarchical retrieval when query and document embeddings are asymmetric and the needed dimension grows gently with hierarchy depth and log of catalog size. A simple schedule, pretrain on regular pairs then finetune on long-distance pairs, fixes misses on far ancestors without hurting close matches.
🧩 Quick outline
The task is to retrieve the exact node plus all more general ancestors, so relevance is one-way. They formalize the setup, train with a softmax loss over in-batch negatives, and score by recall.
They prove feasible Euclidean embeddings exist with a dimension that scales with depth and log of size. Synthetic trees show learned encoders work at much smaller dimensions than the constructive bound.
Tiny dimensions fail mainly on far ancestors, the “lost-in-the-long-distance” effect. Up-weighting far pairs hurts near pairs, so rebalancing alone fails.
Pretrain then finetune only on far pairs lifts all distance slices with early stopping to protect near pairs. On WordNet and Amazon ESCI, the recipe gives clear recall gains across slices.

📦 Problem setup and training loss
They define a directed acyclic graph over documents, map each query to its exact document, mark every reachable ancestor as relevant, then train dual encoders with a softmax cross-entropy using temperature 20. This pushes a query to score higher with any ancestor than with unrelated items while keeping fast nearest neighbor search.

📐 Geometry result, how much dimension is enough
They construct embeddings by summing random unit document vectors for each query’s ancestor set and prove a single threshold separates matches from non-matches with high probability. The needed dimension grows roughly with the maximum ancestor count per query and with log of total documents, so linear in depth, logarithmic in catalog size, not in the number of queries. For a perfect tree, this turns into about depth squared times log of branching, which is still compact.

🔬 Synthetic trees, what dimension actually works
They build perfect trees with width W and height H, train lookup-table encoders with the same softmax loss, and find the smallest dimension that hits >95% recall. Learned encoders meet the target at dimensions below the constructive bound, and the fitted trend matches the theory that scales with H and log W.

📉 The “lost-in-the-long-distance” effect
With tiny dimension, models nail exact or near-parent matches yet miss distant ancestors and recall decays with query-document distance. Rebalancing by over-sampling far pairs lifts far-slice recall but torpedoes near-slice recall, showing a hard trade-off when training everything at once.

🧪 Pretrain then finetune, why this fixes it
First pretrain on regular pairs to lock local neighborhoods, then finetune only on far pairs with a 1,000× lower learning rate and a higher temperature of 500, which quickly boosts far-slice recall while keeping near-slice recall intact. Early stopping prevents late drift, and the finetune does not need exact graph distances, any practical proxy that separates near from far suffices.

📚 WordNet results, long-distance retrieval finally shows up
On noun synsets, pretrain then finetune lifts every distance slice, reaching 92.3% overall recall at dimension 64 with the worst slice still at 75.7%. At dimension 16, overall recall rises from 43.0% to 60.1%, and the standout long-distance slice shows 19% → 76%.
HyperLex correlation improves to 0.415 from 0.350, indicating better graded hypernym understanding after finetune. Hyperbolic embeddings beat plain Euclidean training at the same size, yet still trail the pretrain-finetune Euclidean setup for comparable settings.

🧰 How to reproduce the recipe sensibly
Start with regular sampling, train until near-slice recall stabilizes, and save a strong checkpoint. Switch to a far-only finetune set using a simple proxy for distance, cut the learning rate by 1000×, raise the temperature to around 500, monitor slices, and stop early when all distances are high.
This figure explains hierarchical retrieval, where a query should return its ancestors in a product or concept tree. It uses “Kid’s sandals” to show asymmetric relevance, since “Sandals”, “Kid’s shoes”, and “Footwear” are correct matches upward but the reverse is not.
The graph sketch just generalizes that idea as a directed acyclic graph so ancestors are the nodes you can reach by following arrows upward. The line chart shows the core failure of standard dual encoders, recall crashes as the ancestor is farther in the hierarchy, the lost-in-the-long-distance effect. The dashed line shows the fix, a pretrain then finetune schedule that keeps recall high even for far ancestors.
The takeaway: train normally for the local structure, then finetune on far pairs to recover the long-distance matches without breaking the near ones.

Why hierarchical retrieval is tricky in the first place.
The usual way dual encoders work is by putting queries and documents into a space where closer distance means more relevance. That works fine when relevance is symmetric, like “apple” and “fruit” being related both ways.
But in hierarchies, relevance is one-directional. If the query is “Kid’s sandals”, then “Sandals” or “Footwear” should be considered relevant because they are ancestors. But if the query is “Sandals”, “Kid’s sandals” should not be returned, since it’s too specific.
This asymmetry makes the job harder. That’s why the paper says you need asymmetric embeddings, where the same concept is treated differently depending on whether it is on the query side or the document side. That’s the foundation of their whole approach.

🏆 Tencent just took a big step beyond GRPO by introducing Single-stream Policy Optimization (SPO)

Tencent just took a big step beyond GRPO by introducing Single-stream Policy Optimization (SPO)
An approach that fixes GRPO’s wasted compute from degenerate groups and its constant group synchronization stalls, making training both faster and more stable.
🧠 The idea
SPO trains with 1 response per prompt, keeps a persistent baseline per prompt, and normalizes advantages across the batch, which stabilizes learning and cuts waste. This removes degenerate groups that give 0 signal and avoids group synchronization stalls in distributed runs.
On math reasoning with Qwen3-8B, SPO improves accuracy and learns more smoothly than GRPO. Sensational fact: 4.35× throughput speedup in an agentic simulation and +3.4 pp maj@32 over GRPO.
🧩 The problem with group-based training
Group-based methods sample many responses per prompt to compute a relative baseline, but when every response in a group is all correct or all wrong the advantages become 0 and the step gives no gradient. Heuristics like dynamic sampling try to force a non-zero advantage, but they add complexity and keep a synchronization barrier that slows large-scale training.
How GRPO and SPO (Single-stream Policy Optimization) process a prompt. In GRPO, each prompt generates multiple responses. Those responses each get rewards, and then the rewards are normalized within the group to calculate the advantage.
The problem is that if all responses are equally good or bad, the group normalization wipes out the signal, leaving no useful gradient. In SPO, a prompt produces only one response. The reward from that response is compared against a persistent value estimate for that prompt.
That difference becomes the advantage. This way, every response contributes directly to learning, and the persistent baseline keeps the updates stable instead of relying on a group comparison.
So the figure highlights why SPO is simpler and more efficient. GRPO wastes samples when groups collapse, while SPO ensures each sample matters and avoids the synchronization barrier of waiting for entire groups to finish.

🧠 What SPO changes at a high level
SPO returns to single-sample policy gradient, it uses a persistent value estimate for each prompt as the baseline instead of an on-the-fly group mean. It normalizes advantages across the whole batch, so samples of mixed difficulty share a stable scale. The persistent baseline also acts like a live curriculum signal, so sampling can focus compute where learning potential is highest.

📡Google’s AI Search Live is out, for US, English and looks incredible. 🔥

What sets Search Live apart from regular voice search is its use of Gemini to understand and respond conversationally. It processes what you say, what it sees, and what it knows from the web, then gives an answer that feels like an interactive chat.
The feature runs in AI Mode with Gemini, so it mixes what a person says, what the camera sees, and results from the web, then replies conversationally with sources people can tap if they want more detail. For activation just tap the new Live icon under the search bar in the Google app or switch to Live from Google Lens to start a back-and-forth session with visual context already on.
Typical uses include quick travel questions by pointing at a street or landmark, hobby help like identifying tools in a matcha set, and step-by-step device setup by recognizing ports and cables on the spot. Importantly, Google isn’t ditching its traditional search setup. With Search Live, you still get the usual list of web links alongside the AI’s response.
Scope is English in the US for now, with reports of India getting attention next, but today’s rollout target is the US build of the Google app. Under the hood, the heavy lift is multimodal grounding, the model ties spoken phrases like “which cable goes where” to detected objects in the frame, then maps that to web knowledge and product docs, which is why it can guide a person port by port with follow-ups.
🛠️ How are developers using AI - Google’s DORA report finds that out
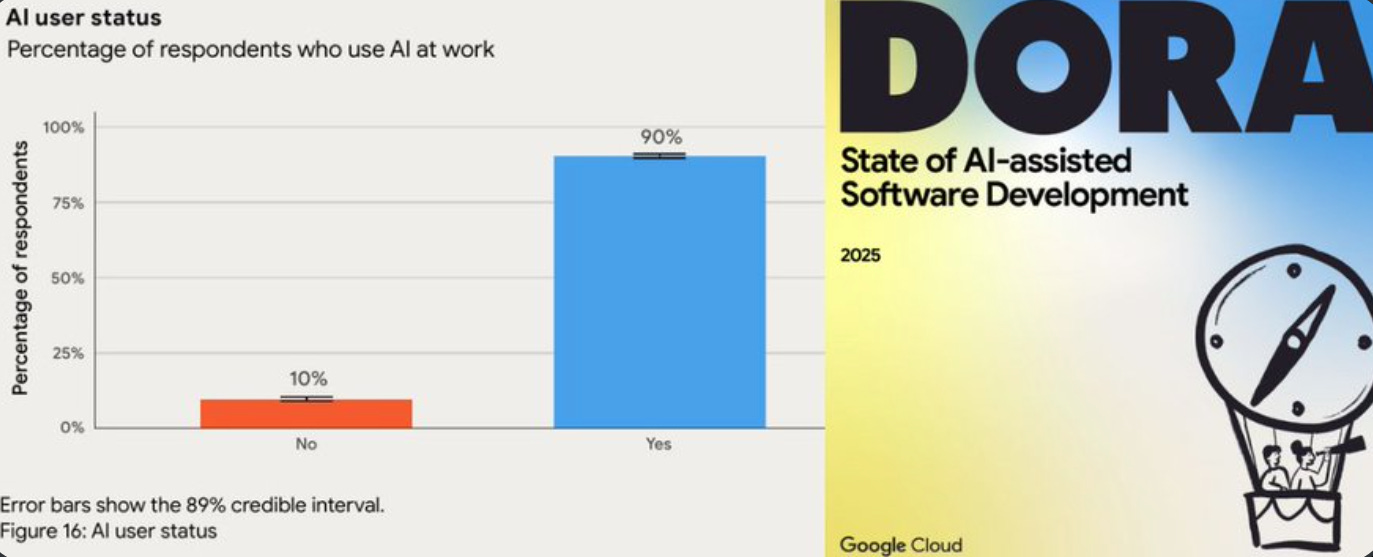
Google Cloud’s 2025 DORA (DevOps Research and Assessment) report is out. And according to it, AI Has Won: 90% of all tech workers are now using AI at work, up 14% from last year.
Google‘s annual “DevOps Research and Assessment (DORA)” 142 page report, released today, found that 90% of the nearly 5,000 tech professionals surveyed are using AI at work. 90% of tech workers are now using AI at work.
Moreover, the research showed that developers are spending about two hours each day actively working with AI tools. Trust is cautious, with 46% saying they “somewhat” trust the code, 23% trusting “a little,” and only 20% trusting “a lot,” which fits the pattern of frequent small fixes after suggestions.
Perceived impact is mixed, with 31% seeing code quality “slightly improved” and 30% seeing “no impact,” which implies speed gains may outweigh clear quality gains so far. The core technical limit is context and reliability, since assistants lack full system understanding, can miss side effects, and need tests, typed interfaces, static checks, and continuous integration to keep risk low.
The job market picture is rough for new grads, with software listings down 71% between Feb-22 and Aug-25, and candidates reporting marathon search cycles like 150 applications before landing roles. Adoption also rides on social momentum, since teams often try the tools because peers are trying them, then keep them where the latency, doc lookup, and boilerplate wins are clear.
Self-reported benefits concentrate on individual effectiveness and code quality, which aligns with AI absorbing boilerplate and scaffolding while surfacing options faster. Two stubborn outcomes barely move, friction and burnout, because they live upstream in process and culture rather than at the keyboard.

This image shows the 7 types of teams the report identified, each with its own strengths and weaknesses. The spider charts compare them across things like team performance, product performance, throughput, stability, burnout, friction, valuable work, and individual effectiveness.
e.g. the Foundational challenges - Only about 10% of all surveyed teams are in this cluster. These teams are struggling the most.
Almost everything is low: output, product delivery, and effectiveness. Burnout and friction are very high. They are stuck in survival mode.

Respondents have about 16 months of AI experience on average. Most didn’t start right when ChatGPT launched in 2022, but adoption surged in late 2023 to mid 2024. The median start date is April 2024, showing that’s when AI use really went mainstream.
Time spent using AI on a recent workday

General reliance on AI at work

Percentage of task of task performers who use AI

Where people interact with AI

Perceived impact on individual productivity

Perceived impact of AI on code quality

Trust in the quality of AI-generated output

Distribution of respondents age

Distribution of Respondent Gender

💰 OpenAI is planning a $1T compute build out anchored by a Central Park sized complex near Abilene, scaling toward 20GW and possibly 100GW, to meet surging ChatGPT demand from 700M weekly users.

Each 1GW of capacity is pegged at about $50B, which is how the math lands on $1T if the company reaches 20GW, and at 100GW that implied spend rounds to $5T. Inside Building 1, rows of racks hold units built around Nvidia GB200, with 72 per rack and strict access controls plus cameras on every rack to deter tampering.
High speed fiber links stitch the GPUs so training and inference traffic can hop between chips fast, because latency and bandwidth directly cap model scale and throughput. Grey gas turbine towers provide backup power so workloads do not stall during grid events, since even short outages can trash long training runs.
Construction runs with about 6,000 workers across two 10 hour shifts and 7 days a week. And an Oracle executive said there will be roughly 1,700 permanent jobs on-site once construction ends. New capacity breaks out as 5.5GW with Oracle near Abilene, north of El Paso in New Mexico, plus a Midwest site, and 1.5GW with SoftBank in Lordstown and near Austin over the next 18 months.
That’s a wrap for today, see you all tomorrow.