
🛠️ New Paper Shows Why Reasoning Improves With Reinforcement Learning
Why Reinforcement learning boosts reasoning, Alibaba’s Qwen3-Next-80B-A3B drops, China’s SpikingBrain1.0 debuts, and Thinking Machines Lab aims to justify its $12B valuation.
Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (14-Sept-2025):
🛠️ New paper shows why reasoning improves with Reinforcement learning
🧠 Thinking Machines Lab carries a $12B valuation—how will it defend it?
🇨🇳 China's Alibaba releases next-generation Qwen3 Qwen3-Next-80B-A3B
🇨🇳 China unveils world's first brain-like AI Model SpikingBrain1.0
🛠️ New paper shows why reasoning improves with Reinforcement learning

We all know Reinforcement learning boosts reasoning in language models, but nobody really explained why.
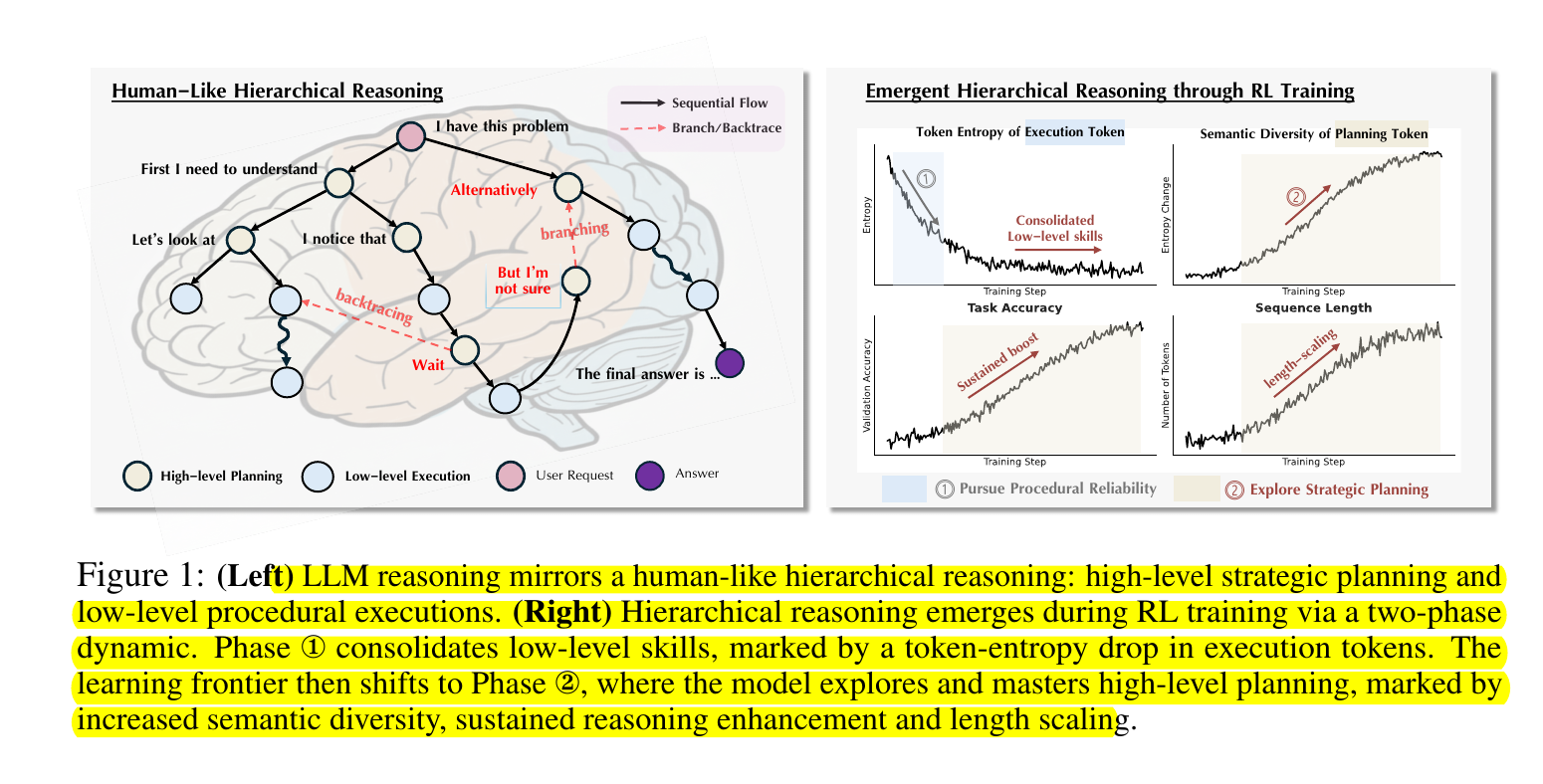
This paper shows that reasoning improves with RL because learning happens in two distinct phases. First, the model locks down small execution steps, then it shifts to learning planning. That “hierarchical” view is their first new insight.
At the start, the model focuses on execution, like doing arithmetic or formatting correctly. Errors in these small steps push it to become more reliable quickly. Once that foundation is stable, the main challenge shifts to planning, meaning choosing the right strategy and organizing the solution.
The researchers prove this shift by separating two kinds of tokens. Execution tokens are the small steps, and planning tokens are phrases like “let’s try another approach.”
They find that after the model masters execution tokens, the diversity of planning tokens grows, which links directly to better reasoning and longer solution chains
Based on this, they introduce a new method called HIerarchy-Aware Credit Assignment (HICRA). Instead of spreading learning across all tokens, HICRA gives extra weight to planning tokens. This speeds up how the model explores and strengthens strategies.
In experiments, HICRA consistently beats the common GRPO approach. It works best when the model already has a solid base of execution skills. If the base is too weak, HICRA struggles.
The key message is that real gains in reasoning come from improving planning, not just polishing execution.
🧠 Thinking Machines Lab carries a $12B valuation—how will it defend it?
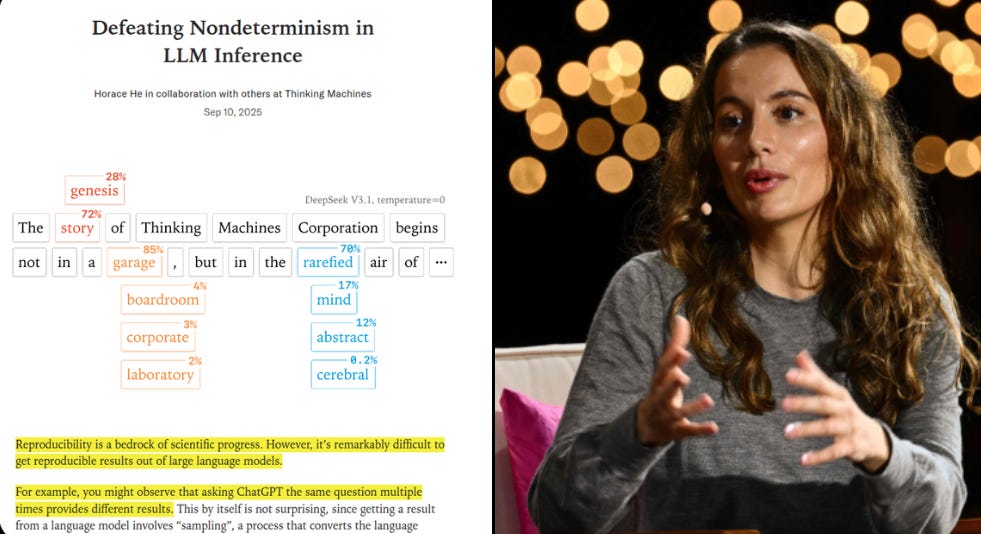
🎯 It has one simple but BIG idea: AI outputs can be consistent. While most call models non-deterministic, they claim it’s a solvable flaw. Fixing randomness would make AI safe for high-stakes workflows.
Large companies spend millions then see a loan score or a medical helper answer change between runs, which is not acceptable. The technical root is parallel math on GPUs where many tiny programs run at once so the order can shift and rounding nudges the result.
A real fix means deterministic inference, with fixed seeds, ordered reductions, kernels that avoid race conditions, and numerically stable layers kept consistent end to end. Right now the problem for corporate environment is that the same prompt can return different outputs, which breaks audit trails and blocks trust.
Only a small share of companies (21%) have actually changed their workflows to properly use AI. So even though AI tools exist, most organizations still run on old processes, and only a minority have restructured work around AI systems.
if the model gives different answers each time, it adds one more layer of complexity for teams that already struggle with skills and workflow changes. It makes audit trails unreliable and adds friction, so those same firms are even less likely to adopt AI in production.
Thinking Machines has hired about 30 people by Feb-2025 with nearly 66% from OpenAI. The enterprise AI market was $23.95B in 2024 and could reach $155.21B by 2030 at 37.6% growth, while only 20% have advanced analytics skills so about 80% leave value on the table.
Their investors include Andreessen Horowitz with Nvidia, Accel, ServiceNow, Cisco, AMD, and Jane Street as US startup funding rose 76% to $162.8B and AI was 64.1% of deal value. If they prove hard determinism without a big hit to speed or quality, they can win regulated workloads in finance, health, and government.
From their detailed official blog these are the main pointers on how it can possibly be achieved. 👇
Make every reduction batch invariant, which means the math runs in the same order no matter the batch size, so answers do not change with traffic.
Stabilize RMSNorm by doing each row’s add up step on one core and not splitting that work across cores at small batches, even if some cores sit idle.
Use one fixed matrix multiplication plan by compiling and reusing a single GPU program, and avoid splitting the add up step across cores or changing chunk size based on shape.
Keep GPU math instructions fixed instead of switching to smaller ones when the batch is tiny, because instruction changes also change the add up order.
Make attention see a single consistent layout by updating the key value cache and the memory map before attention runs, so it always walks the same pattern.
Adopt a fixed split size along the key value axis so the add up order is identical whether decoding 1 token or many.
Hold attention chunking constant across prefill and decode so both paths combine scores in the same sequence.
Decode greedily at temperature 0 after the above fixes so the model always picks the highest probability token without sampler noise.
Replace default operators with these batch invariant versions across the stack using library hooks, so every call path uses the same deterministic GPU functions.
Accept a small speed tradeoff for uniform plans because keeping one plan across shapes costs some throughput but locks down the numbers.
🇨🇳 China's Alibaba releases next-generation Qwen3 Qwen3-Next-80B-A3B

80B params, but only 3B activated per token. Ultra-Sparse MoE: Activating Only 3.7% of Parameters
10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!)
Prefill Stage: At 4K context length, throughput is nearly 7x higher than Qwen3-32B. Beyond 32K, it’s over 10x faster.
Decode Stage: At 4K context, throughput is nearly 4x higher. Even beyond 32K, it still maintains over 10x speed advantage.
Prefill is the one pass read of the whole prompt that builds the attention cache, so higher prefill throughput cuts first token wait time and makes long prompts cheaper.
Decode is the step that adds tokens one by one using that cache, so higher decode throughput means more tokens per second while generating even when the prompt is long.
This helps long document QA, code review over big repos, and multi tool runs, where prompts often reach 16K to 32K and first token latency dominates wall clock time.
Qwen3-Next-80B-A3B-Instruct significantly outperforms Qwen3-30B-A3B-Instruct-2507 and Qwen3-32B-Non-thinking, and achieves results nearly matching our flagship Qwen3-235B-A22B-Instruct-2507.
Instead of using the plain transformer stack, they apply an attention and activation-aware architecture (A3B). In simple terms, this structure changes how the model processes very long sequences of text. Normal transformers slow down a lot when the input grows longer, because attention has to look at every token in the sequence.
The A3B setup uses a more efficient layout that reduces this cost while keeping accuracy. This is why you see the big boost in both prefill (the first pass over the prompt) and decode (token-by-token generation). The design keeps throughput high even past 32K tokens, which is usually where models start lagging badly.
Qwen3-Next-80B-A3B uses something called Gated DeltaNet, which is a new way to handle attention inside the transformer. In normal transformers, every token looks at every other token, which gets very heavy as the sequence grows. DeltaNet changes this by focusing only on the differences (the deltas) between tokens, rather than always reprocessing everything. This already makes things more efficient.
The gated part adds a control switch on top. Instead of always applying the delta update, the model learns when it is useful to apply it and when it can skip. That way, the network doesn’t waste computation on tokens that don’t really change the information much.
So in short, Gated DeltaNet makes the model faster at long contexts by cutting down unnecessary attention work, while the gating mechanism keeps accuracy intact. This is a big reason why the model can scale smoothly past 32K tokens without slowing down.

Thanks to its hybrid architecture, Qwen3-Next also shines in inference:
Prefill Stage: At 4K context length, throughput is nearly 7x higher than Qwen3-32B. Beyond 32K, it’s over 10x faster.
Decode Stage: At 4K context, throughput is nearly 4x higher. Even beyond 32K, it still maintains over 10x speed advantage.

Qwen3-Next-80B-A3B-Instruct significantly outperforms Qwen3-30B-A3B-Instruct-2507 and Qwen3-32B-Non-thinking, and achieves results nearly matching our flagship Qwen3-235B-A22B-Instruct-2507.

🇨🇳 China unveils world's first brain-like AI Model SpikingBrain1.0

Upto 100X faster while being trained on less than 2% of the data typically required.
Designed to mimic human brain functionality, uses much less energy. A new paradigm in efficiency and hardware independence.
Marks a significant shift from current AI architectures
Unlike models such as GPT and LLaMA, which use attention mechanisms to process all input in parallel, SpikingBrain1.0 employs localized attention, focusing only on the most relevant recent context.
Potential Applications:
Real-time, low-power environments
Autonomous drones and edge computing
Wearable devices requiring efficient processing
Scenarios where energy consumption is critical
This project is part of a larger scientific pursuit of neuromorphic computing, which aims to replicate the remarkable efficiency of the human brain, which operates on only about 20 watts of power.
🧠 The idea for the Human-brain-inspired linear or hybrid-linear LLMs for the SpikingBrain architecture.
SpikingBrain replaces most quadratic attention with linear and local attention, mixes in selective full attention where it matters, and adds an adaptive spiking activation so the model computes only on meaningful events.
It proves the whole recipe works at scale by training and serving on MetaX C550 GPUs, which are non‑NVIDIA devices, without giving up quality on common benchmarks.
The headline efficiencies come from 3 levers working together, linear attention for compressed memory, MoE for token-wise sparsity, and spiking for micro-level sparsity.
🛠️ Training without starting from scratch
They do a conversion‑based continual pre‑training, not full pre‑training, by remapping QKV weights from a Transformer checkpoint into linear and local attention, then training for ~150B tokens across 8k, 32k, and 128k contexts.
Because the converted attention maps stay close to the original softmax map, the model converges quickly and avoids the ~10T token budgets seen in many scratch runs, which is <2% of typical data. Post‑training then adds instruction following and reasoning in 3 short stages without harming the base capabilities.
⚡ Spiking, but practical
Instead of simulating complex leaky neurons, activations are turned into integer spike counts in one step using a threshold that adapts to the activation statistics, which avoids dead or overactive channels. The single‑step integer view trains well on GPUs, then at inference those counts can expand into sparse spike trains for event‑driven hardware.
Overall, this paper ran a huge language model over insanely long inputs, like 4 million tokens, and made it generate the first word more than 100x faster than normal Transformers. And they can do this while training on only about 2% of the data that’s usually needed
How do they achieve it?
They basically copy two tricks from the brain. First, instead of looking at all words all the time (which is very expensive), they use linear attention. That means the model keeps a running summary of past words, like a compressed memory, instead of storing everything in full.
Second, they add spiking neurons. These only “fire” when something really matters, instead of constantly doing math for every single signal. That makes the computations sparse, which saves a ton of energy and time. Together, these changes turn the model into something much leaner: it still learns well, but it runs way faster and uses way less power.
That’s a wrap for today, see you all tomorrow.