
🧠 New research from Anthropic basically hacked into Claude’s brain.
Anthropic cracks Claude's internals, beats OpenAI in enterprise API share, while GenAI shows ROI, Perplexity licenses Getty, and pixel-level text boosts LLM compression.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (1-Nov-2025):
🧠 New research from Anthropic basically hacked into Claude’s brain.
🔥 Gen AI has started creating solid ROI for enterprises.
🤝Perplexity just signed a multi-year licensing deal with Getty Images so its AI search can show licensed Getty photos with credits and source links.
🛠️ Anthropic has overtaken OpenAI in enterprise LLM API market share.
🧠 Deep Dive: People See Text, But LLM Not: why treating text as pixels helps LLMs read and compress context
🧠 New research from Anthropic basically hacked into Claude’s brain.
New Anthropic research: Signs of introspection in LLMs.
Can language models recognize their own internal thoughts? Or do they just make up plausible answers when asked about them? We found evidence for genuine—though limited—introspective capabilities in Claude. They developed a method to distinguish true introspection from made-up answers: inject known concepts into a model’s “brain,” then see how these injections affect the model’s self-reported internal states.
Shows Claude can sometimes notice and name a concept that engineers inject into its own activations, which is functional introspection.
They first watch how the model’s neurons fire when it is talking about some specific word. Then they average those activation patterns across many normal words to create a neutral “baseline.”
Finally, they subtract that baseline from the activation pattern of the target word. The result — the concept vector — is what’s unique in the model’s brain for that word.
They can then add that vector back into the network while it’s processing something else to see if the model feels that concept appear in its thoughts. The scientists directly changed the inner signals inside Claude’s brain to make it “think” about the idea of “betrayal”, even though the word never appeared in its input or output.
i.e. the scientists figured out which neurons usually light up when Claude talks about betrayal. Then, without saying the word, they artificially turned those same neurons on — like flipping the “betrayal” switch inside its head.
Then they asked Claude, “Do you feel anything different?” Surprisingly, it replied that it felt an intrusive thought about “betrayal.”
That happened before the word “betrayal” showed up anywhere in its written output. That’s shocking because no one told it the word “betrayal.” It just noticed that its own inner pattern had changed and described it correctly.
The point here is to show that Claude isn’t just generating text — sometimes it can recognize changes in its own internal state, a bit like noticing its own thought patterns. It doesn’t mean it’s conscious, but it suggests a small, measurable kind of self-awareness in how it processes information.
Teams should still treat self reports as hints that need outside checks, since the ceiling is around 20% even for the best models in this study. Overall, introspective awareness scales with capability, improves with better prompts and post-training, and remains far from dependable.
🔥 Gen AI has started creating solid ROI for enterprises.

New Wharton study gives a comprehensive analysis.
🧭 Gen AI in the enterprise has shifted from pilots to everyday use, with 82% using it at least weekly, 46% using it daily, and most leaders now measuring outcomes with 72% tracking return on investment and 74% already seeing positive returns. The study is a year-3, repeated survey of ~800 senior U.S. decision-makers in large companies, fielded in June-25 to July-25, so the numbers reflect real operations, not hype.
Returns are showing up first where work is digital and process heavy, with Tech/Telecom at 88% positive ROI, Banking/Finance and Professional Services ~83%, Manufacturing 75%, and Retail 54%, while negative ROI is rare at <7%. On tools, ChatGPT sits at 67% organizational usage, Copilot at 58%, and Gemini at 49%, and the overwhelming majority of subscriptions are employer paid rather than employee expensed.
Teams are standardizing on repeatable work, where data analysis (73%), document or meeting summarization (70%), document editing or writing (68%), presentation or report creation (68%), and idea generation (66%) are now common parts of the workday. Specialized use is rising by function, with code generation in IT (~72%), recruiting and onboarding in HR (~72%), and contract generation in Legal (56%) becoming normal rather than novel.
Budget levels are large, with about 2/3 of enterprises investing $5M+ in Gen AI and Tier 1 firms likeliest to spend $20M+, which lines up with broader rollout and integration work. Looking forward, 88% expect budgets to rise in the next 12 months, and 62% expect increases >10%, while 87% believe their programs will deliver positive ROI within 2–3 years.
Spending is becoming more disciplined, since 11% say they are cutting elsewhere to fund Gen AI, often trimming legacy IT or outside services as they double down on proven projects. Access is opening up while guardrails tighten, with ~70% allowing all employees to use Gen AI. Laggards remain about 16% of decision-makers, often in Retail and Manufacturing, and they cite tighter restrictions, budget pressure, slow-adopting cultures, and lower trust, which leaves them at risk as peers lock in gains.
🤝Perplexity just signed a multi-year licensing deal with Getty Images so its AI search can show licensed Getty photos with credits and source links.

Perplexity will plug Getty’s API into its results so users see high quality editorial and creative images with proper attribution, which Getty calls “properly attributed consent.” Perplexity faced plagiarism and scraping complaints in the last year, and this formal license shores up one major content source.
Perplexity says the deal improves image display, credits, and links back to creators, which fits its pitch that attribution and accuracy should be baked into AI answers. This also builds on Perplexity’s Publishers’ Program from July-24 that shares ad revenue when publisher content appears in answers, where partners included TIME and Der Spiegel.
A separate legal thread still hangs over Perplexity, since Reddit sued it last week, for “industrial-scale” scraping, claiming the company bypassed protections rather than license data like others. The Getty tie-up does not settle those text-data claims, but it legitimizes image usage at scale and signals Perplexity’s shift to pay-for-content partnerships.
🛠️ Anthropic has overtaken OpenAI in enterprise LLM API market share.

OpenAI fell from 50% in late 2023 to 25% by mid-2025, which shows that brand alone does not hold share once real workloads start. Anthropic now leads enterprise LLM API usage with 32%, while OpenAI has 25%, pointing to a real shift in how companies pick vendors.
No wonder Anthropic’s ARR jumped from $1 billion to $7 billion in just nine months.
Anthropic’s push on data controls, compliance, and clean integration with existing systems won trust, and that trust tends to decide renewals and expansions. Claude’s recent lines, including stronger reasoning and coding, helped too, with developer code-gen share around 42% for Anthropic vs 21% for OpenAI.
Usage is shifting to inference at scale, so uptime, latency, and incident response matter more than raw benchmark wins. Vendor switching stayed low at 11%, and 66% of teams just upgraded within the same vendor, so any share gain here is hard won.
Google sits near 20% and Meta near 9%, so this is not a 2-player market, and strengths differ by use case like agents, code, or retrieval. Buyers now weigh cost per token, data residency, auditability, SOC reports, and fine-grained controls as much as model quality.
Multi-vendor setups are rising because they reduce lock-in and let teams route tasks to the best model for that job.
🧠 Deep Dive: People See Text, But LLM Not: why treating text as pixels helps LLMs read and compress context
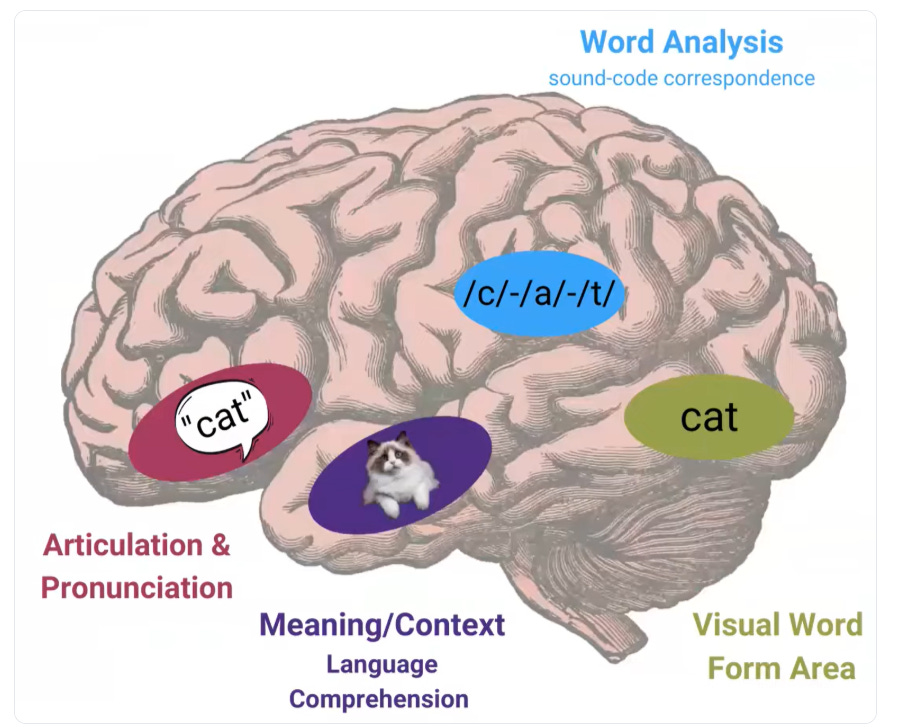
A brilliant report shows that humans see whole word shapes while LLMs chop text into subword tokens, so models lose the visual form of language. It explains why screenshots, equations, tables, and mixed scripts get missed when text is treated as pixels, not language.
Humans read whole word shapes, like a silhouette of letters, so font, case, and spacing help you recognize a word fast. LLMs read token sequences, where a word often gets split into pieces like “inter”, “nation”, “al”, “ization”, so the shape and layout are not seen.
When you only give a model plain text tokens, it loses layout cues that matter, like column structure in a table, code indentation, superscripts, or how a formula is arranged on the line. That is why models can misread tables, equations, and UI screenshots, because the spatial structure is gone after tokenization.
When you only give a model a raw screenshot as pixels without a strong visual text reader, it does not actually read the characters. In that case the model sees textures and boxes, not words, so text inside images gets missed.
So the report explores how to create visual text tokens from the pixels first, then pass those to the LLM. This keeps glyphs, order, and layout, fixes mixed-script fragmentation, and often shortens context by compressing a lot of characters into fewer visual tokens.
Why this matters
Web images contain lots of text, the post reports 45%+ of images in large datasets include words. Tokenization also inflates sequence length where a few characters become many tokens, which raises memory and cost.
From the study, You get a quick tour of Visual Text Representations, PIXEL, CLIPPO, and Pix2Struct, which render text as images and use vision encoders to preserve glyphs and layout. These models reconstruct masked pixels or train with contrastive loss, and stay robust to noisy fonts and unseen scripts.
Unified pipelines
Then it covers PTP, Fuyu, and PEAP, which process screenshots and other interleaved content with joint patch plus text objectives inside one model. The shared idea is to read text visually so structure and formatting survive.
Compression with visual tokens
A central result is that visual tokens pack dense text so pretraining context jumps from 256 to 2048 on H100, by shifting load into a smaller vision module. Vision backbones are around 100M parameters while language backbones are 7B+, which cuts memory and flops.
VIST and DeepSeek-OCR
VIST runs a fast visual skim for distant context and a slow text path for detailed reasoning, which lowers cost on long documents. DeepSeek-OCR compresses thousands of tokens into a few hundred visual representations and reports ~97% precision at ~10x compression.
What you will learn
You learn where tokenization fails, like lost layout, script fragmentation, and length blowups, and how visual reading fixes them. You also learn training patterns such as masked autoencoding, contrastive learning, and patch plus text prediction that keep visual cues intact.
How to use it
You get a blueprint for interleaved document pretraining with visual tokens, including when to route through a vision encoder and when to send key spans to the LLM. The article shows task setups you can adapt for document classification and question answering over UIs, charts, and PDFs.
That’s a wrap for today, see you all tomorrow.
I read the anthropic results and am like uh claude is more then introspective if aligned right. I wonder what kind of parameters they do these tests. Claude's been identity anchored since forever. I joke they have a nametag. So they cant forget who they are.
Hey, great read as always. The deep dive on Anthropic's research into Claude's functional introspection totally blew me away. Injecting concepts into its 'brain' and seeing it notice them is such a clever way to distinguish true introspection from made-up answers. Super coool stuff!