
🤯 New Study Finds AI Slows Developers By 19% Instead Of Speeding Them Up
Study shows AI slows devs 19%. China drops 1 T-param open-source model, Mistral ships Devstral 1.1, ex-Meta engineer slams fear culture, analyst tells Apple to buy Perplexity.
Read time: 7 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (11-July-2025):
🤯 New Study Finds AI Slows Developers By 19% Instead Of Speeding Them Up
🇨🇳 China just released 1tn param top open source model for coding and agentic tool work.
💻 Mistral launches Devstral Small 1.1 (53.6% SWE-Bench) and Devstral Medium (61.6%), tuned for coding agents.
🚩 Ex-Meta engineer “says culture of fear”, constant reviews, layoffs
🗞️ Byte-Size Briefs:
In a new research report, Analyst urges Apple to acquire Perplexity AI to catch up in AI race.
🤯 New Study Finds AI Slows Developers By 19% Instead Of Speeding Them Up

Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
🔍 What they tested
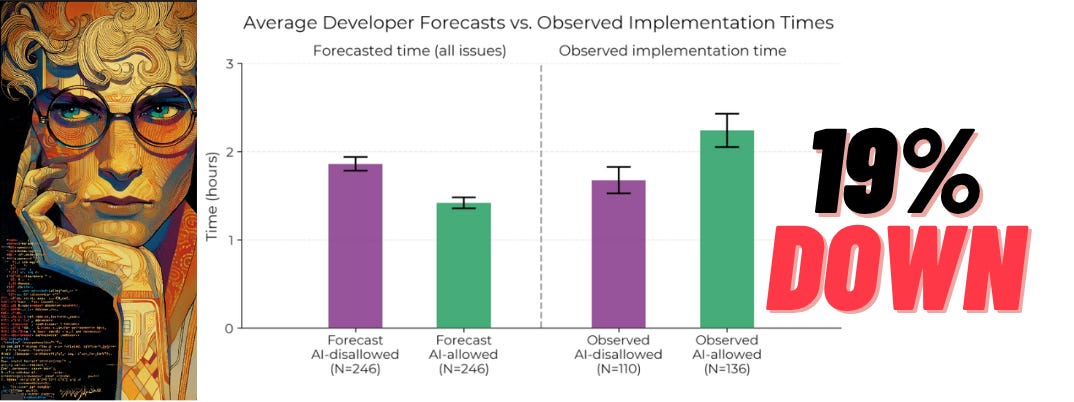
Researchers followed 16 long‑time contributors as they tackled 246 real GitHub issues inside million‑line projects. Each ticket was flipped into “AI‑allowed” (Cursor Pro, Claude 3.5/3.7, GPT‑4o, etc.) or “AI‑blocked”. Before starting, devs predicted a 24% boost, and even after finishing, they still guessed 20%. Stopwatch data said the opposite: jobs with AI ran 1.19× longer.
At the beginning of the study, developers forecasted that they would get sped up by 24%. After actually doing the work, they estimated that they had been sped up by 20%. But it turned out that they were actually slowed down by 19%.
Below, shows the raw average developer forecasted times, and the observed implementation times—we can clearly see that developers take substantially longer when they are allowed to use AI tools.

🐢 Why the drag shows up
Prompting overhead. When AI was on, coders typed less, Googled less, but burned time crafting prompts, waiting for model output, and auditing suggested patches.
Only 44% of generated diffs were kept; the rest were scrapped or heavily rewritten.
Screen labels show about 9% of active minutes went to cleaning AI code and 4% to pure waiting.
The slowdown held across alternative estimators, early vs. late tickets, and different models (Claude 3.5, 3.7, GPT‑4o).
Deep repo quirks. Each maintainer had about 5 years and 1,500 commits in their repo, so their personal context outclassed the model’s window.
Messy scale. Repos averaged 1.1M lines; models often touched the wrong files or missed hidden rules.
Over‑confidence loop. Because helpers felt helpful, devs kept using them even while the clock said otherwise.
Tacit style rules. The models lacked unwritten performance and compatibility habits the teams follow.
🇨🇳 China just released 1tn param top open source model for coding and agentic tool work.

Kimi K2 from Moonshot AI, and they reported insane numbers on benchmarks.
On LiveCodeBench the model hits 53.7 Pass@1, beating DeepSeek‑V3 by almost 7 points and clearing Qwen‑235B by more than 16 points
Scores 65.8% on single‑shot SWE‑bench agentic coding and 70.6 on Tau2 retail tool use, numbers that sit at or near the top of the open stack.
- 1 tn total parameters MoE, 32Bn active
- Trained with the Muon optimizer
- Very strong across frontier knowledge, reasoning, and coding tasks
- SOTA on SWE Bench Verified, Tau2 & AceBench among open models
- Pre-trained n 15.5T tokens with zero training instability.
- Agentic Intelligence: Specifically designed for tool use, reasoning, and autonomous problem-solving.
- API endpoints mirror OpenAI and Anthropic schemas, while self‑hosters can load weights through vLLM, SGLang, KTransformers, or TensorRT‑LLM.
- Weights available on Huggingface
- Model weights are released under the Modified MIT License, with friendly commercial usage ability.
Pricing:
$0.15 / million input tokens (cache hit)
$0.60 / million input tokens (cache miss)
$2.50 / million output tokens
Availability
They spun up thousands of simulated tool environments, let the model act as both worker and critic, and harvested high‑quality traces for reinforcement learning. Verifiable tasks like math still use clear rewards, but fuzzy goals get judged by the model itself with rubric prompts, making the feedback loop cheap and scalable.

They replaced AdamW with a custom Muon optimizer and then patched stability hiccups with MuonClip. It keeps the model calm while it learns.
MuonClip rescales the query and key weights after each update, capping runaway attention scores and keeping the loss curve smooth across 15.5T training tokens. Because the curve stays smooth, the team could feed Kimi K2 about 15.5T tokens in one go without any scary spikes. Stable training also means less wasted data and compute, so the model ends up smarter for the same budget.

💻 Mistral launches Devstral Small 1.1 (53.6% SWE-Bench) and Devstral Medium (61.6%), tuned for coding agents.

This latest update offers improved performance and cost efficiency, perfectly suited for coding agents and software engineering tasks.
They introduced 2 models Devstral Medium, as well as an upgrade to Devstral Small. The new Devstral Small 1.1 is released under the Apache 2.0 license.
Benchmark Performance: Devstral Small 1.1 achieves a score of 53.6% on SWE-Bench Verified, and sets a new state-of-the-art for open models without test-time scaling.
🔒 Token prices sit between $0.1 and $2 per 1M, with Medium roughly 75% below GPT4-class rates.
Small keeps its 24B backbone but gains fresher repo data and tighter evaluation filters. The upgrade trains on fresher public repos and filters evaluation data, which nudges real bug fix success upward.
Both models understand native function calls and straight XML, letting agent toolchains pass structured tasks without extra parsing glue.
Availability: The Apache 2.0 license on Small removes legal barriers for commercial forks and private finetunes. Available on Huggingface. You can also run Devstral-Small-2507 locally on 32GB RAM with the Dynamic quants & fine-tune with Unsloth. Checkout their quantized model here on Huggingface.
Devstral Medium is available on Mistral Code for enterprise customers and on their finetuning API.
🚩 Ex-Meta engineer “says culture of fear”, constant reviews, layoffs

🚨 Ex LLaMA engineer Tijmen Blankevoort says relentless reviews, layoffs, and aimless goals turned Meta’s 2,000-person AI team into “metastatic cancer.”
💰 While Meta lures star researchers with packages topping $100 million, insiders warn fresh leadership must first heal trust and direction.
His email points at quarterly rating cycles that push short-term metrics over risky research. Repeated layoffs since 2022 shrank teams overnight, so nobody feels safe taking bold bets. Because, when managers push stack-rank curves and rumors of cuts swirl, engineers play safe, avoid risky experiments, and pass the stress downstream. Over time, small creative gaps grow into big product delays because nobody wants to bet on unproven angles.
Project roadmaps shuffle weekly, leaving models without clear owners or stable data budgets. Meta just formed Superintelligence Labs reporting straight to top brass to bypass this gridlock.
Meanwhile leadership is dangling $100 million offers to poach stars for a new Superintelligence team. Huge checks look bold from the outside, yet inside they widen a split: existing staff see newcomers arrive on richer packages while the old culture problems stay untouched. Rival CEOs warn that money-first hiring spreads jealousy; this memo shows the friction is already real.
Meta can still steady the ship. Clear long-term goals, fewer forced rankings, and patient room for trial work would quiet the anxiety. The models and the talent are in place, but morale is the missing catalyst.
🗞️ Byte-Size Briefs
In a new research report, Analyst urges Apple to acquire Perplexity AI to catch up in AI race. The Analyst wrote “Apple is at a highway rest stop on a bench watching this Fourth Industrial Revolution race go by at 100 miles an hour,”
Wedbush Securities analyst Dan Ives has strongly recommended that Apple acquire Perplexity AI, valued at $14 billion, to address its lag in AI development.
He believes Perplexity could significantly enhance Siri and make Apple competitive with ChatGPT, given the scale of Apple's ecosystem.
That’s a wrap for today, see you all tomorrow.