
Non-instructional Fine-tuning: Enabling Instruction-Following Capabilities in Pre-trained Language Models without Instruction-Following Data
Non-instructional data enhances LLMs' instruction-following abilities without explicit instruction-related content.


Non-instructional data enhances LLMs' instruction-following abilities without explicit instruction-related content.
Original Problem 🔍:
Conventional instruction fine-tuning for LLMs relies on supervised data containing explicit instructions and correct responses, which can be labor-intensive to create.
Solution in this Paper 🧠:
• Proposes using "non-instructional data" to enable instruction-following capabilities in pre-trained LLMs
• Uses first half of random OpenWebText articles as instructions
• Employs GPT-3.5-turbo or GPT-4-turbo to complete the text as responses
• Fine-tunes models using this generated data
Key Insights from this Paper 💡:
• Non-instructional data can effectively improve instruction-following capabilities
• Method is more scalable and less labor-intensive than traditional approaches
• Performance gains observed even in models already fine-tuned on instruction data
• Filtered datasets confirm improvements not due to latent instructional content
Results 📊:
• LLaMA-3-70B-Instruct fine-tuned with non-instructional data achieved 57.0 on Arena Hard, surpassing LLaMA-3.1-70B-Instruct
• Significant improvements across MT-Bench, Open LLM Leaderboard, and Arena Hard benchmarks
• Fine-tuned LLaMA-2-7B showed MT-Bench score increase from 3.88 to 5.12
• Mistral-7B-v0.1 improved from 3.73 to 7.29 on MT-Bench after fine-tuning
🔍 The researchers conducted a thorough analysis to ensure the non-instructional datasets were devoid of instruction-related content. They used GPT-4 to detect potential instructional and conversational content in the datasets. The analysis showed minimal instructional content (0.7%) in the non-instructional data. They also performed experiments with filtered datasets to confirm that the improved performance was not due to latent instructional content.
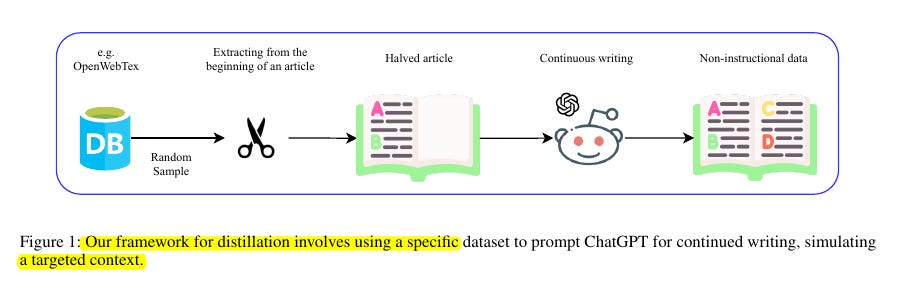
It bypasses the need for generating instruction-formatted content by directly distilling knowledge from large language models like ChatGPT.
🚀 This research opens up new possibilities for training instruction-following LLMs.
The generation of non-instructional data is more scalable and less labor-intensive compared to typical instruction-following datasets.
Paper - "Non-instructional Fine-tuning: Enabling Instruction-Following Capabilities in"