
Not All Heads Matter: A Head-Level KV Cache Compression Method with Integrated Retrieval and Reasoning
Not all brain cells are equal - same goes for LLM attention heads! 💡


Not all brain cells are equal - same goes for LLM attention heads! 💡
Why store everything when you can just remember the important stuff?
Smart KV cache compression that knows which attention heads matter most.
Hence, HeadKV intelligently compresses LLM memory by identifying and prioritizing crucial attention heads
🎯 Original Problem:
KV caching in LLMs faces significant memory overhead with increasing input length. Current compression methods operate at layer-level, missing the opportunity to optimize at individual attention head level.
🔧 Solution in this Paper:
• HeadKV: Compresses KV cache at individual head level instead of layer level
• Allocates cache budgets based on head importance using Needle-in-a-Haystack tests
• HeadKV-R2: Enhanced version that evaluates both retrieval and reasoning abilities
• Uses dynamic budget allocation across heads based on importance scores
• Retains most relevant KV cache entries within each head using attention-based selection
💡 Key Insights:
• Not all attention heads are equally important for text generation
• Head-level compression outperforms layer-level approaches
• Combining retrieval and reasoning abilities for importance scoring is crucial
• Dynamic budget allocation across heads is more effective than fixed allocation
• Just 1.5% of KV cache can retain 97% of full performance
📊 Results:
• Achieves 97% of full KV cache performance while retaining only 1.5% of cache
• Outperforms baselines on LongBench and LooGLE benchmarks
• Superior performance in low-resource settings (KV size = 64 & 128)
• Maintains computational efficiency comparable to existing approaches
• Effective preservation of both retrieval and reasoning capabilities
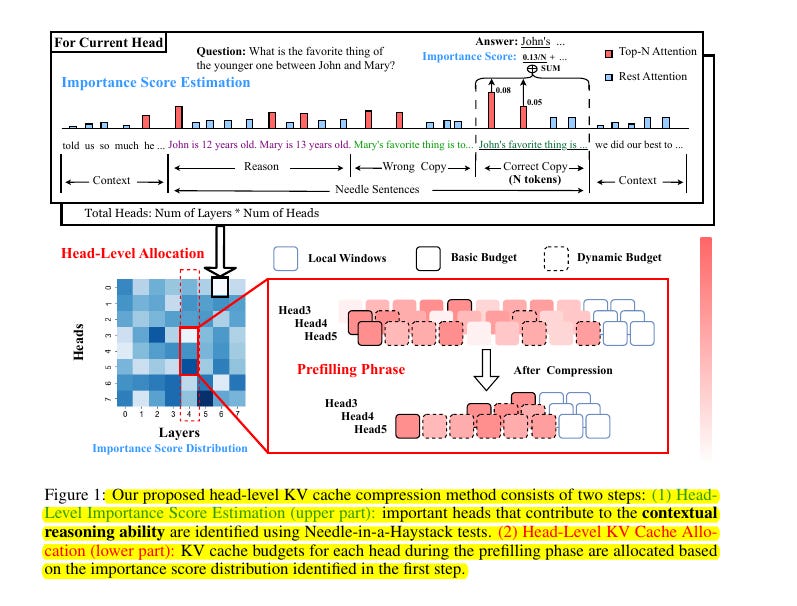
🔍 The method operates in two key steps: First, it estimates head importance scores using Needle-in-a-Haystack tests that evaluate both retrieval and reasoning abilities.
Second, it allocates KV cache budgets to individual heads based on their importance scores, with more important heads receiving larger cache allocations.
💡 The main innovations are:
(1) Operating at individual head level rather than layer level for KV cache compression,
(2) Using a novel importance score estimation that considers both retrieval and reasoning abilities, and
(3) Implementing dynamic budget allocation across heads based on their importance distributions.
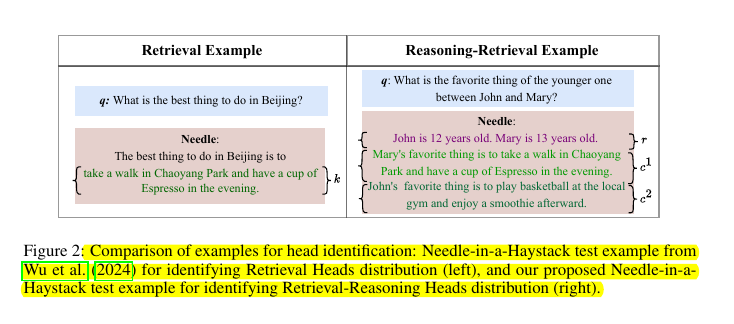
🔧 How does this method handle both retrieval and reasoning capabilities?
The method constructs special retrieval-reasoning examples that require both abilities, modifying the traditional Needle-in-a-Haystack test to include explicit reasoning steps.
It then estimates head importance based on attention patterns during these combined tasks, ensuring the compressed cache preserves both capabilities.
