
OpenAI's o3 model is out and it is absolutely amazing!!
OpenAI launched of o3 full model and o4-mini and a variant of o4-mini called “o4-mini-high”
Read time: 9 min
📚 Browse past editions here.
( I publish this newletter multiple times a week. Noise-free, actionable, applied-AI developments only).
🥉 OpenAI launched of o3 full model and o4-mini and a variant of o4-mini called “o4-mini-high” that spends more time crafting answers to improve its reliability.

📌 Key Highlights
→ o3 and o4‑mini think longer and plan tool calls rather than guessing.
→ Unlike previous reasoning models, o3 and o4-mini can generate responses using tools in ChatGPT such as web browsing, Python code execution, image processing, and image generation.
→ Today's updates reflect the direction OpenAI’s models are heading in: they are converging the specialized reasoning capabilities of the o-series with more of the natural conversational abilities and tool use of the GPT‑series. So they are not really just models, they are "AI systems”.
→ Images join text in the reasoning loop, unlocking visual math and diagram analysis.
→ Benchmarks show double‑digit accuracy jumps over o1 while cutting cost per query.
→ OpenAI also announced Codex CLI, a local coding agent interface for multimodal terminal workflows.
Availability
Starting today, the models, are available for subscribers to OpenAI’s Pro, Plus, and Team plans. And the o3-pro model for ChatGPT’s pro tier will come in a few weeks, so for now, Pro users can still access o1‑pro. Free users can try o4-mini by selecting 'Think' in the composer before submitting their query. Rate limits across all plans remain unchanged from the prior set of models.
Both o3 and o4-mini are also available to developers today via the Chat Completions API and Responses API (some developers will need to verify their organizations(opens in a new window) to access these models). The Responses API supports reasoning summaries, the ability to preserve reasoning tokens around function calls for better performance, and will soon support built-in tools like web search, file search, and code interpreter within the model’s reasoning. To get started, checkout the official docs.
🧠 The Core Themes in this release ⚙️
Longer internal thinking: The models spend more compute per question, giving deeper step‑by‑step reasoning.
Reinforcement learning at scale: OpenAI repeated the “more compute = better” curve inside RL fine‑tuning, not just pre‑training. Extra training steps teach the model when to call which tool.
Multimodal chain‑of‑thought: Images enter the token stream as first‑class reasoning artifacts. The model can crop, rotate, and re‑inspect pictures while it thinks.
Cost tiers: o3 targets tough jobs; o4‑mini trades a small accuracy loss for much lower latency and higher usage caps.
📊 Benchmarks 📈
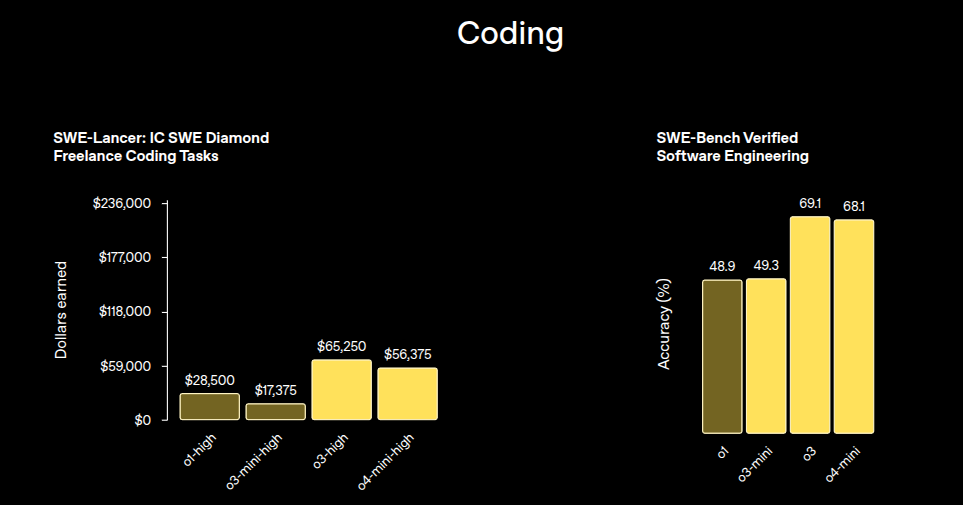
→ o4‑mini‑high dominates o3 on strict math benchmarks and matches it on most others.
→ o3 still owns the headline coding score on SWE‑bench, but the gap is two percentage points.
→ Visual reasoning remains o3’s strongest relative edge.
→ When cost matters, o4‑mini‑high sits on the better side of every frontier.
⚖️ Cost curves
Cost‑performance plots show no crossover: for every dollar tier, o4‑mini‑high returns equal‑or‑better accuracy on math and science while remaining cheaper to run. Coding advantage tilts toward o3 only at the very top end.
🛠️ Agentic Tool Use 🔧
The model decides to search, then writes Python, then renders a chart, iterating until the answer is structured exactly as the user asked. This strategy solves questions whose data live outside the base weights.
o1-Pro vs o3 and o4-mini-high
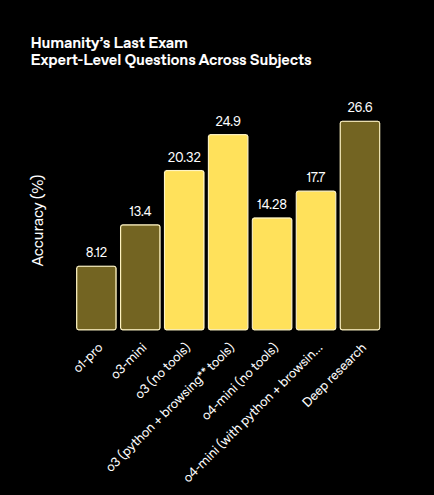
o3 more than doubles o1‑Pro on the raw, no‑tool run.
When both are allowed to search the web and execute code, o3 still keeps a ~7‑point lead over o4‑mini‑high.
o4‑mini‑high cleanly outperforms o1‑Pro in both versions but trails o3.
o3 and o4‑mini last far longer on multi‑step jobs than any earlier OpenAI model, edging out the latest Claude releases.
On an updated version of HCAST benchmark, o3 and o4-mini reached 50% time horizons that are approximately 1.8x and 1.5x that of Claude 3.7 Sonnet, respectively.
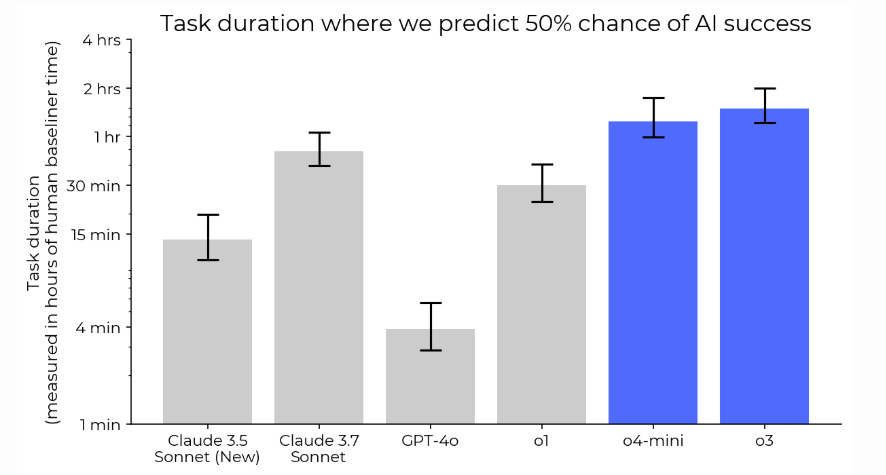
📈 What the bar chart shows
Vertical axis = “How long a human normally spends on a task.”
The higher the bar, the longer the task the model can still finish half the time.
→ Bigger number means deeper stamina: the model keeps track of goals, code, and intermediate results for longer.
→ o4‑mini almost doubles o1’s endurance while costing less to run.
→ o3 pushes the limit to tasks that would keep a trained engineer busy for an hour and a half.
🖼️ Visual Reasoning 🖼️
→ o3 and o4‑mini don’t just glance at an image once. They loop images through their internal reasoning steps—cropping, zooming, rotating—exactly the way a human would scribble notes or move a magnifier while solving a puzzle.
→ This visual chain‑of‑thought is baked into the base model. No separate vision module, no hand‑off to another system. One network handles the whole job.
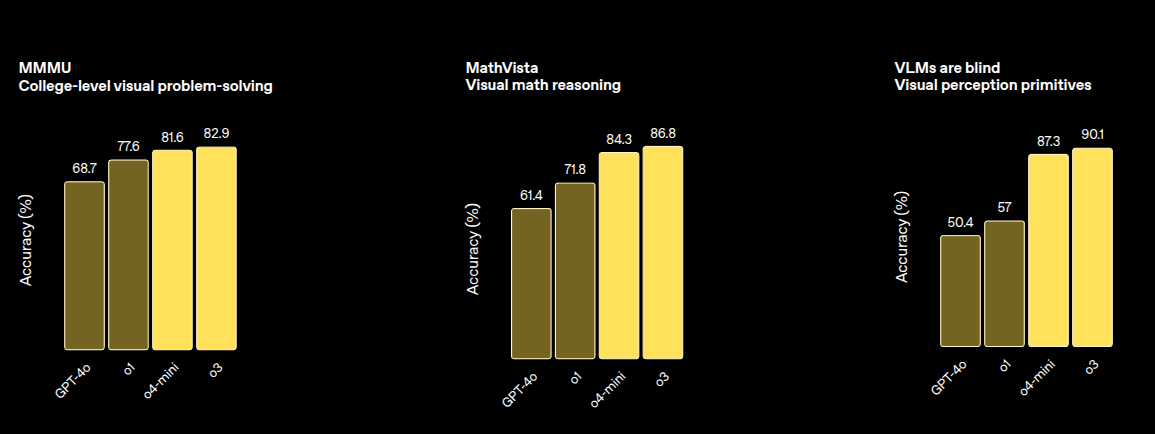
→ Because the model can “think with images,” accuracy on tough multimodal tests jumps from roughly mid‑60 percent (GPT‑4o) to around 83‑90 percent on tasks like college‑level visual problem solving (MMMU) and visual math reasoning (MathVista).
→ Real results: read messy handwriting, trace a maze, debug a code screenshot, identify a bus schedule—even when text is upside‑down or tiny—without extra prompts from you.
→ The same chain‑of‑thought tools (image editing + Python + web search) let it mix vision and text reasoning inside one conversation—OpenAI’s first true multimodal agent experience.
Bottom line: o3 and o4‑mini mark a clean break from “see once, answer once.” They reason with the picture every step of the way, and that single change sets new records across almost every visual benchmark OpenAI tested.
So how exactly this chain-of-thought for visual tasks works in terms of improving accuracy on visual math tasks?
The model treats an image like a worksheet. It zooms or crops until every digit and symbol is sharp, turns those pieces into plain text inside its memory, runs built‑in Python to do the math, then places the answer back on the picture to see if it fits. If the overlay looks wrong, it zooms again and fixes the mistake before replying.
This “look‑solve‑check‑look again” loop stops the classic errors from blurry text or missed labels, so the data going into the calculation are correct and the final answer is verified against the image. That simple habit pushes accuracy on tough visual math tests like MathVista from the low 60 percent range in older models to almost 87 percent in o3 and o4‑mini.
💻 OpenAI also launched Codex CLI, a coding “agent” designed to run locally from terminal
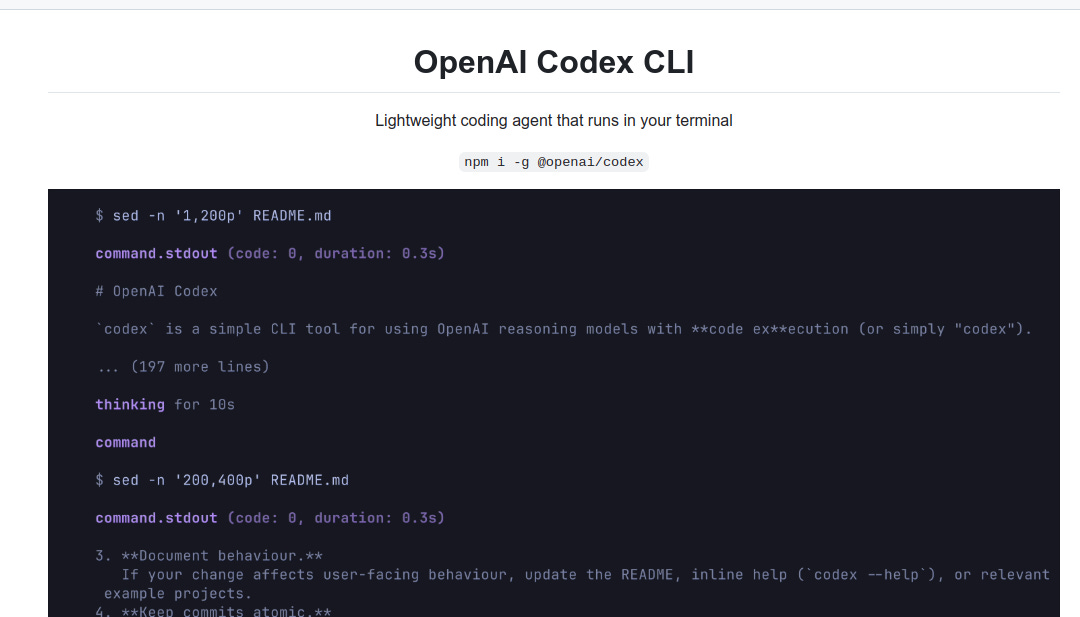
Codex CLI turns an OpenAI model into a hands‑on coding buddy that lives right inside your terminal. Nothing fancy to set up—just install the package and start talking to your code. And its really Open-Source, here’s the Github.
So Codex CLI appears to be a step in the direction of OpenAI’s broader agentic coding vision. Eventually OpenAI wants to build “agentic software engineer,” a set of tools that can take a project description for an app and effectively create it.
🏗️ What It Is
Small Node.js tool (npm i -g @openai/codex) that connects your prompt to your local repo. It speaks to OpenAI models (default o4‑mini) and then edits files, runs tests, or moves stuff around on your drive.
🛡️ Built‑in sandbox in Codex CLI
All commands execute in a sealed sandbox: Apple Seatbelt on macOS or a minimal Docker container on Linux. Outbound network is blocked except for the call to the OpenAI API, so an accidental curl or destructive script cannot touch the rest of your system.
⚙️ How does Codex CLI Work
You type
codex "add login flow"Codex scans the repo, drafts a plan, and shows you the diff.
Run codex "fix login bug" and the tool finds the file, writes the patch, shows a diff, and waits for your “y/n”.
You approve (or reject) each change. In Full Auto mode it skips the questions and pushes straight to Git.
All commands run inside a sandbox—Seatbelt on macOS or Docker on Linux—so rogue scripts can’t reach the wider system.
🔐 Approval Modes Codex CLI (Three autonomy levels)
Each step shows what will change, diff style. You hit y to accept, n to tweak, q to bail.
Suggest – read‑only, every write or shell command needs a “yes”.
Auto Edit – writes directly, still asks before running commands.
Full Auto – writes and runs without asking; ideal for test sandboxes.
🖼️ Extra Trick with Codex CLI
Drop a screenshot or sketch into the prompt. The model can read it, write matching code, compile, and launch—all in one go.
📝 Codex General Instructions that travel with you
Codex lets you pre‑load guidance in two markdown files: put general habits in ~/.codex/instructions.md (applies to every run, like “create a virtual‑env first”) and stash repo‑specific rules in a CODEX.md at the project root (e.g., “React lives in src/components”).
When you type a Codex command, the CLI first checks for these two markdown files. It reads ~/.codex/instructions.md in your home folder, which holds your “always do this” rules—say, “activate .codex‑venv before any Python command.”
Next it looks in the current Git repo (or its root) for a file named CODEX.md; that file can tell the agent about local conventions such as “store React components in src/components” or “never edit generated/.”
Codex concatenates the text from the global file and then the project file, appends your prompt, and sends the combined message to the OpenAI model. The model’s plan and every action it proposes must respect those instructions: if your global file forbids direct npm install, Codex will either ask before running it or choose another path; if the project file says tests must run with `poetry run pytest`, that is the command Codex will insert in its bash steps.
Because this merge happens automatically on every invocation, you change behavior simply by editing either markdown file—no command‑line flags, no extra prompt text—so your personal practices and each repo’s rules travel with you wherever you use the CLI.
Why Codex CLI feels “safer” than past AI coding tools
It insists on Git.
Codex will not enter its hands‑off full‑auto mode unless the folder is a Git repository (git initorgit clone). Every change the agent makes gets stored as a commit.Git is your undo button.
If Codex wrecks a file you simply rungit reset --hard HEAD~1(or use any git GUI) and the code rolls back. No mystery state, no lost work.You stay in one place—the terminal.
All the ChatGPT‑style reasoning happens behind the scenes, but the edits land directly in your local files. You never paste snippets back and forth between a browser and an editor.
In short: Codex demands version control first, so you always have a clean history and an easy way to revert whatever the AI just did. Checkout more on this page in its official Github repo.
💸 To spur use of Codex CLI, OpenAI plans to dole out $1 million in API grants to eligible software development projects. The company says it’ll award $25,000 blocks of API credits to the projects chosen.
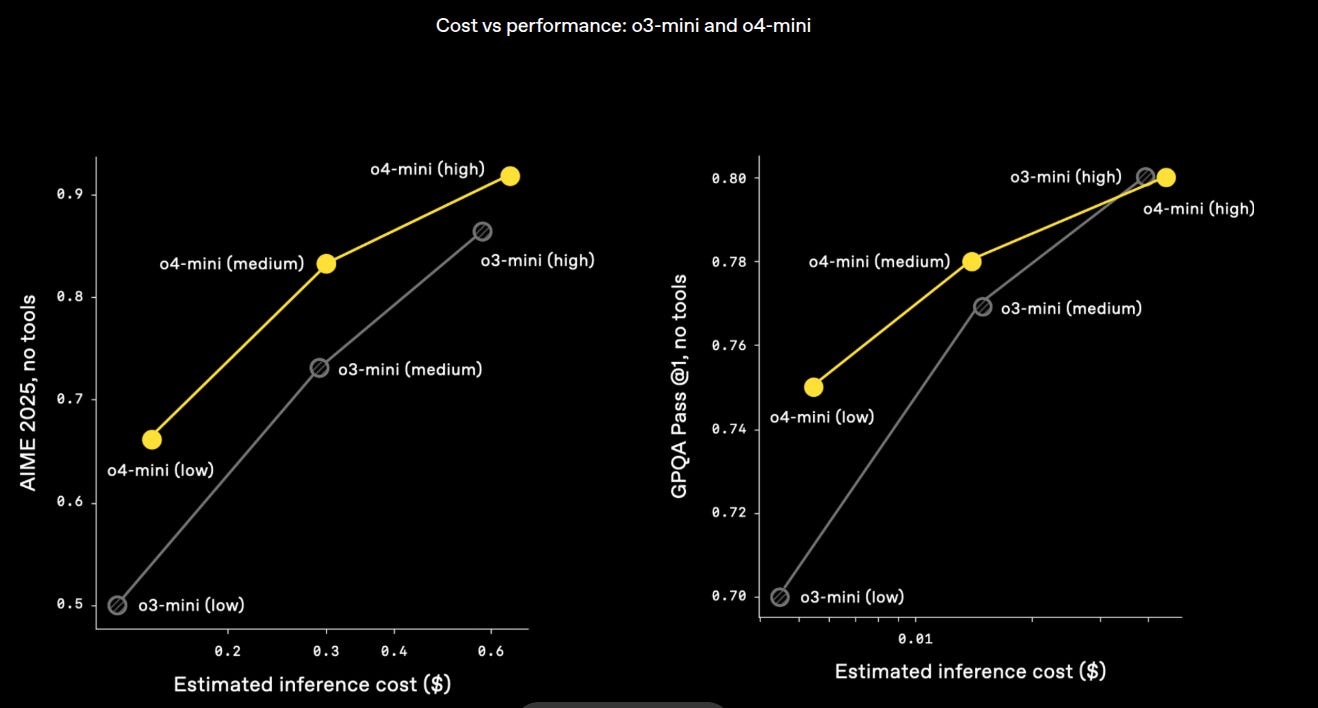
Cost vs performance: o3-mini and o4-mini 💵
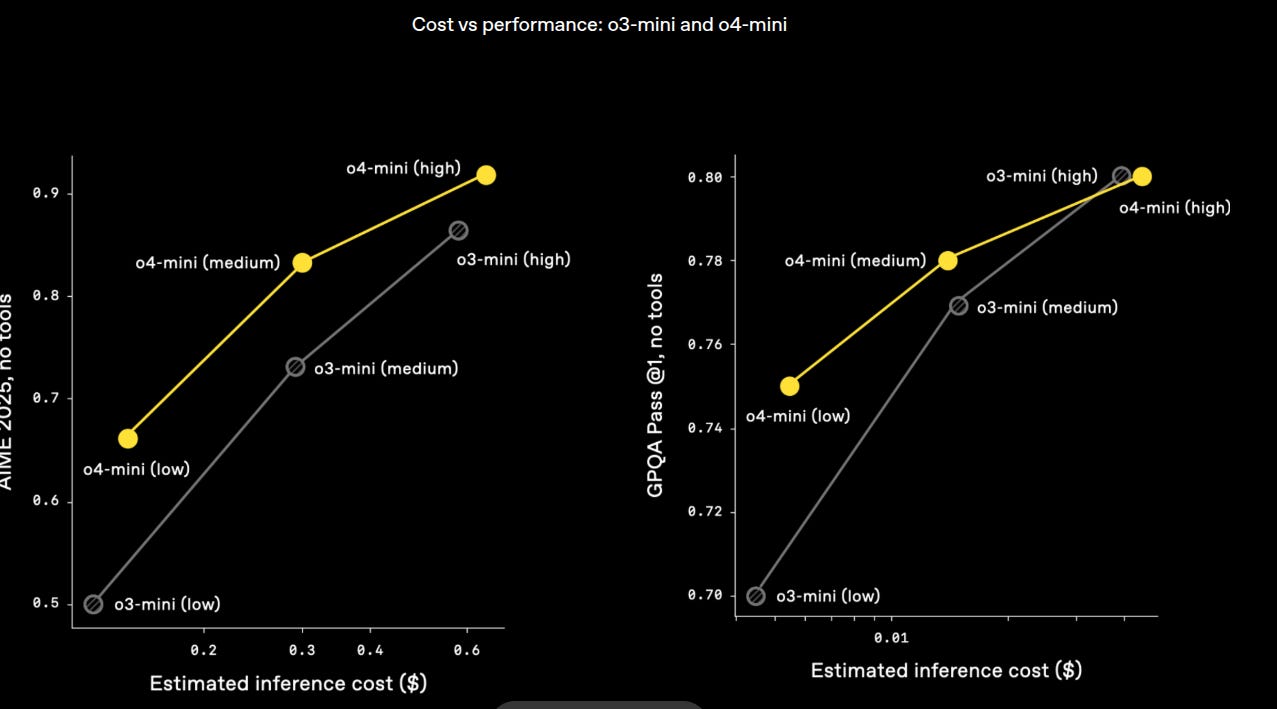
Cost‑performance plots show o3 strictly dominates o1, and o4‑mini strictly dominates o3‑mini across the full latency spectrum. For high‑volume workloads o4‑mini offers the best dollar per correct answer.
→ o4‑mini shifts the entire cost‑performance frontier upward; no crossover points exist, so it strictly dominates o3‑mini.
→ Biggest win is the budget tier most users care about (medium price, 0.30 $ ish): same latency, about one extra correct answer in ten.
→ For equal accuracy targets you can cut inference cost by 30‑40 percent by moving from o3‑mini to o4‑mini.
→ Gains arise from tighter RL fine‑tuning and more optimized inference kernels; training compute went up, serving compute went down.
→ For high‑volume workloads the data make the choice clear: default to o4‑mini unless you need an even cheaper ultra‑low‑tier model.
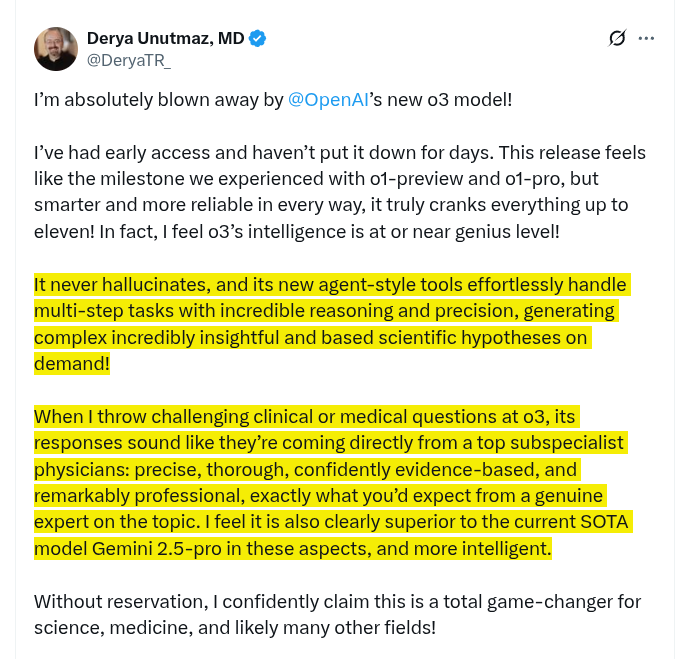
Here is a tweet from one top medica professional who was experimenting with o3 for few days
That’s a wrap for today, see you all tomorrow.