OmniParser for Pure Vision Based GUI Agent
Pure visual understanding of UIs without needing HTML: OmniParser Paper from @Microsoft


Pure visual understanding of UIs without needing HTML: OmniParser Paper from @Microsoft
Original Problem 🎯:
Current vision-based GUI agents struggle to accurately identify interactive elements and understand their functionality across different platforms, limiting GPT-4V's effectiveness in UI automation tasks.
Solution in this Paper 🔧:
• OmniParser: A pure vision-based UI parsing system combining:
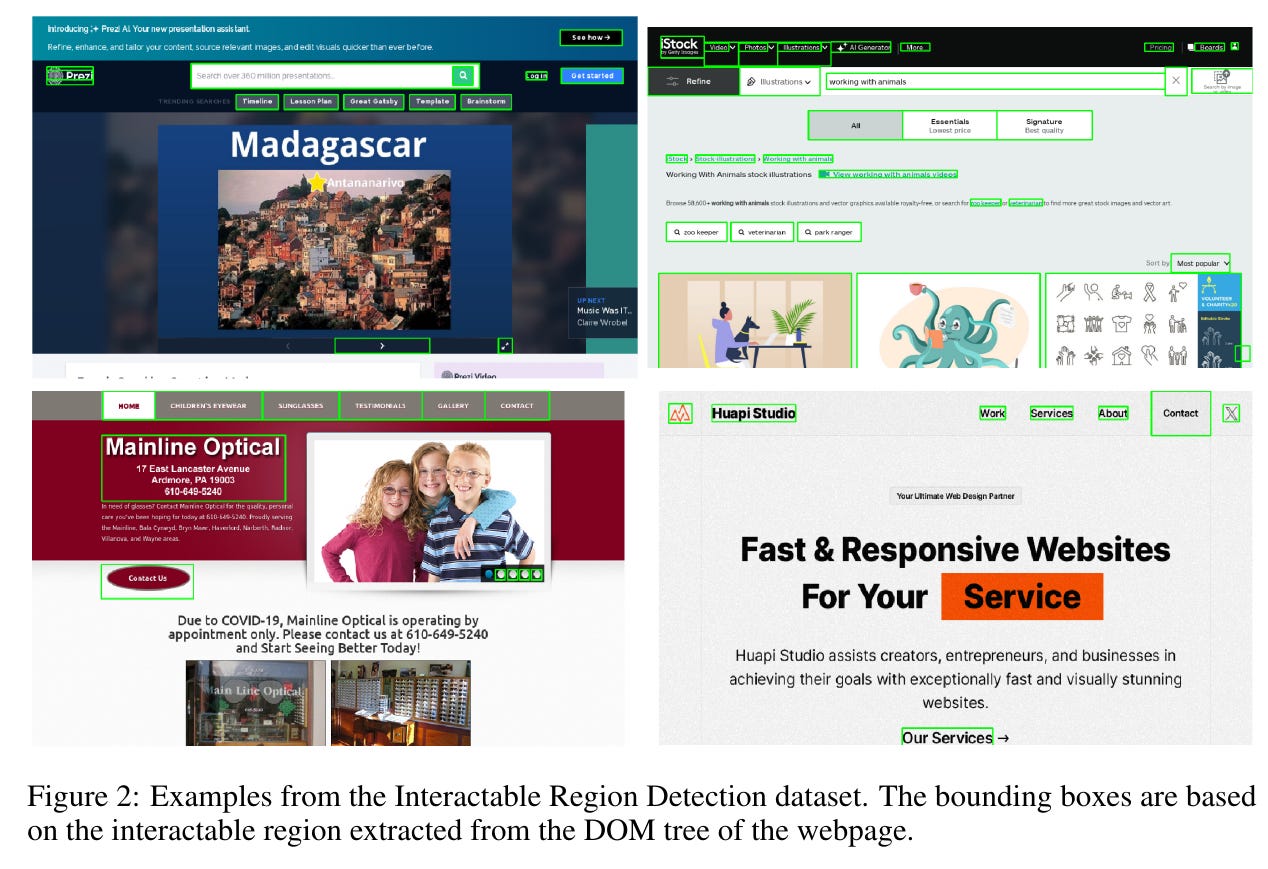
Interactable icon detection model trained on 67k webpage screenshots
Icon description model fine-tuned on 7k icon-description pairs
OCR module for text detection
• Generates structured DOM-like representations with:
Bounding boxes for interactive elements
Numeric IDs for each element
Functional descriptions of detected icons
• Uses Set-of-Marks approach to overlay bounding boxes on screenshots
Key Insights from this Paper 💡:
• GPT-4V performs better with explicit local semantics of UI elements
• Pure vision-based parsing can match or exceed HTML-based approaches
• Incorporating icon functionality descriptions significantly improves accuracy
• Model generalizes well across mobile, desktop and web platforms
Results 📊:
• ScreenSpot Benchmark: 73% accuracy (vs 16.2% GPT-4V baseline)
• Mind2Web: 42% cross-domain accuracy (+5.2% over HTML-based methods)
• AITW: 57.7% overall success rate (+4.7% over GPT-4V with specialized detection)
• SeeAssign: 93.8% accuracy with local semantics (vs 70.5% without)
🛠️ The way OmniParser's architecture is designed:
The system consists of two main components:
An interactable icon detection model trained on a curated dataset from popular webpages, and
A caption model fine-tuned to extract functional semantics of detected elements. It also includes an OCR module to detect text elements.
These components work together to produce structured, DOM-like representations of UI elements.