
🤖 OpenAI and Jony Ive are building a palm sized, screenless AI assistant
Google opens up Jules Tools CLI, OpenAI+Ive prototype a screenless AI device, Nvidia props up US AI, Tesla’s Optimus goes AI-Kung Fu, and MoE inference gets dissected.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (6-Oct-2025):
👨🔧 Google made Jules Tools public, offering a command-line option to configure and manage its coding assistant.
🤖 OpenAI and Jony Ive are building a palm sized, screenless AI assistant targeted for 2026, but core software, privacy, and compute are not ready yet.
🏆 MoE Inference Economics from First Principles
📡 Tesla’s Optimus humanoid robot performs Kung Fu moves - great achievement for humanoid robots as many of these moves are not tele-operated instead they are AI-driven control.
💰 “How Nvidia Is Backstopping America’s AI Boom”
👨🔧 Google made Jules Tools public, offering a command-line option to configure and manage its coding assistant.
Jules is Google’s AI coding agent. It can write code, fix bugs, or create tests for your software projects. It connects directly to your GitHub or other code repositories, looks at your codebase, and then performs specific coding tasks that you assign.
Now Google launched Jules Tools, a command line tool and public API that lets developers run and control its async coding agent, Jules, directly from the terminal instead of the browser.
You can type something like
`jules remote new --session “fix login bug”`
and Jules will automatically open a remote virtual machine (VM), clone your code, work on that issue, and send back a pull request (a proposed code change).
If you have a bunch of GitHub issues or TODOs, you can even pipe them into Jules so it automatically picks them up and handles them. It can also remember your style and previous corrections so its next code suggestions fit your preferences better.
The CLI adds features like task management commands, scriptable automation, context memory, secure credential handling, and an interactive text interface (TUI) for quick dashboard-style control.
The TUI mode mirrors the web dashboard, but faster, showing real time session status and guided task creation within the terminal.
Because it’s fully scriptable, you can integrate Jules into continuous integration (CI) or cron jobs and use it as part of automated pipelines.
The new API makes it possible to trigger Jules automatically from Slack or build systems and track its work until a pull request is created.
Jules plans out its task, runs it on a cloud virtual machine, and then returns a finished pull request for review.
Recent updates gave Jules memory, image uploads, a stacked diff view, and pull request comment handling to make it feel more natural to use in real workflows.
Google also plans to expand Jules beyond GitHub, so it could work with GitLab, Bitbucket, or even setups without version control.
If Jules runs into a problem, it stops and asks for help instead of guessing, though mobile users still don’t get native notifications for those pauses.
The free version allows 15 daily tasks and 3 at once, while paid tiers at $19.99 and $124.99 per month increase limits to about 100 and 300 daily tasks.
This move keeps developers focused inside their own environment while Jules handles routine jobs like testing or dependency updates. It’s a smart expansion because it turns Jules into a real part of the daily developer workflow rather than just a web toy.
🤖 OpenAI and Jony Ive are building a palm sized, screenless AI assistant targeted for 2026, but core software, privacy, and compute are not ready yet.

OpenAI and Jony Ive are working on a small, screenless AI assistant planned for 2026, though its main software, privacy systems, and compute setup are still unfinished.
The device listens and sees the environment through a mic, camera, and speaker, stays always on, and the team has not nailed how its voice should talk or stop. OpenAI bought Ive’s io for $6.5B and has pulled in 20+ ex Apple hardware staff, while manufacturing talks include Luxshare, with assembly possibly outside China.
Compute is the biggest blocker because running multimodal chat at scale needs huge inference capacity, and OpenAI already struggles to serve peak ChatGPT demand. Continuous sensing that builds a user memory creates hard privacy choices about when to capture, what to store, and how to delete or process locally.
The market is unforgiving, as the Humane AI Pin was shut down and offloaded to HP, and the Friend AI pendant drew backlash for being creepy and for constant listening. OpenAI now carries a $500B valuation, so a strong hardware hit would help, but supplier chatter suggests first devices could slip toward 2026 or 2027.
The assistant must deliver low latency speech, clean turn taking, useful visual detection, and lean memory, all under tight cost and power. OpenAI’s projected path to $125B Annuanl Recurring Revenue.

🏆 MoE Inference Economics from First Principles - A super comprehensive tutorial
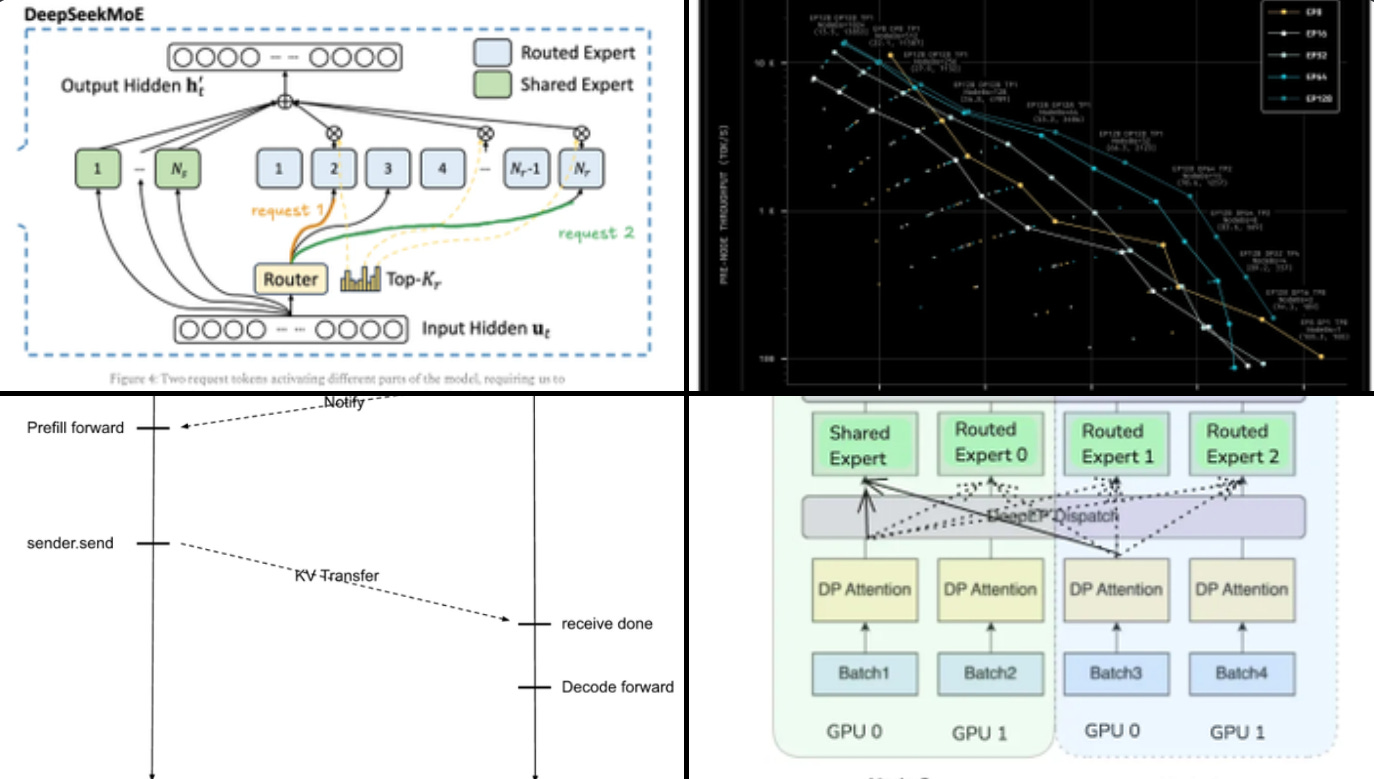
MoE models only activate a few experts per token, which saves compute but causes heavy memory and communication use. With small batches it looks fine, but as batch size grows more experts get touched and the system loads more of the model each step.
This makes decoding tokens a memory bandwidth problem and increases key value cache storage because many sequences run at once. The solution is to spread experts across many GPUs in a setup called expert parallelism, and route each token to its top experts plus a shared expert.
DeepSeek routing usually picks 8 experts from 256 per layer across 58 layers, which is why communication becomes the main cost. To control this, attention stays data parallel so the cache sits on one GPU, and only small activation vectors get moved across devices.
Two microbatches run at once so that while one computes, the other handles communication, hiding most delays. Because some experts get used more than others, hot experts are duplicated and traffic is balanced to avoid bottlenecks.
Routing also favors experts on the same node to reduce slow inter-node transfers. Multi head latent attention compresses the key value cache to 70KB per token instead of hundreds of KB, which lowers memory traffic.
This lets batch sizes grow larger, especially for long contexts. They also reorder the attention math so that projections tied to context length are folded away, cutting wasted compute.
The economics are then simple: GPUs cost money per hour, tokens per hour are the output, and price per token is cost divided by output. Throughput grows with bigger batch size, more GPUs, and faster interconnects, but falls when service requires high tokens per second per user.
Tests on different clusters show that more GPUs in an expert parallel group make each GPU more efficient by keeping experts busier. Interconnect speed is key, with NVLink racks scaling well, while InfiniBand between DGX nodes becomes the bottleneck.
If services guarantee 20 tokens per second per user, then batch size must shrink and cost per token rises. That is why chat settings run fast but waste capacity, while synthetic data jobs should run with huge batches and low tokens per second per user.
A 72-GPU cluster at batch 64 can produce billions of tokens per day at about $0.40 per 1M tokens. Prefill is different, it is compute heavy and grows with input length, so providers split prefill from decode and use caching so prefixes are not recomputed.
Good caching achieves about 56.3% hits, reducing cost and freeing GPUs for decoding. Global demand is still low compared to capacity, with only about 1B output tokens per day on aggregators, far below what even one big rack can handle.
The main lesson is that MoE models become cheap when run with large batches, compressed caches, smart routing, split prefill and decode, and fast interconnects. This allows providers to price fast chat higher while offering slow bulk generation much cheaper, which is useful for synthetic data and fine tuning.
📡 Tesla’s Optimus humanoid robot performs Kung Fu moves - great achievement for humanoid robots as many of these moves are not tele-operated instead they are AI-driven control.

And we can clearly see faster motion, steadier footwork. So the stack is closing the loop from camera input and body sensors to whole-body motion at interactive rates, which is the hard part for legged robots.
That typically means on-board vision estimates the robot’s pose and ground contact, a controller predicts how the body will move next, then solves for joint torques and footsteps every few milliseconds. The quick hop after a shove looks like a capture-point or stepping response, where the controller shifts the base just enough to keep the center of mass inside support.
Skeptics will ask whether this is a choreographed policy that tracks a pose sequence rather than a skill that generalizes to messy inputs. Even if that’s the case, still its a huge success, as interacting with a person untethered will require lower latency, better compliance in the joints, and cleaner whole-body control than older dancing clips.
Musk’s targets are 5,000 units in 2025 and 50,000 in 2026. And Kung Fu is a compact way to stress range of motion, quick balance shifts, and recovery from contact, the same ingredients needed for lifting, box handling, and walking on uneven floors.
💰 “How Nvidia Is Backstopping America’s AI Boom” - A great WSJ article.

A great article by WSJ analyzing this development.
Nvidia is investing $100B in OpenAI to build 10GW of Nvidia-powered AI data centers, locking in GPU demand while giving OpenAI cheaper capital and a direct supply path. This is vendor financing, Nvidia swaps funding and its brand strength for long-term chip orders, a pattern critics call circularity.
NewStreet Research analysts tried to model how Nvidia’s investment into OpenAI plays out financially. They found that for every $10B Nvidia invests into OpenAI, OpenAI in turn commits to spending about $35B on Nvidia chips over time.
So Nvidia isn’t giving money away for free. It’s basically pre-funding its own demand. OpenAI gets cheaper access to capital, and Nvidia gets guaranteed GPU orders in return.
The trade-off is that Nvidia has to lower its usual profit margins on those advanced chips. Instead of charging OpenAI full price, it effectively offers them at a discount. But because the volumes are so large and locked in, Nvidia gains long-term sales stability, which investors love.
OpenAI has been getting access to Nvidia chips through cloud providers or “neo-clouds.” These middlemen front the money to build data centers, buy GPUs, and then rent them to OpenAI at a markup.
Because OpenAI is still unprofitable and seen as risky, the debt used to finance those deals can carry very high interest rates — sometimes around 15%. By contrast, if a company with stronger credit like Microsoft backs the project, the rates drop to about 6–9%.
Nvidia stepping in with its balance sheet gives lenders more confidence, so the effective borrowing cost for projects tied to OpenAI falls closer to that lower range. Nvidia has used similar backstops, including a $6.3B agreement to buy CoreWeave’s unused capacity through Apr-32.
Here also, Nvidia using its financial strength to stabilize its ecosystem. CoreWeave is a cloud provider that rents out clusters filled with Nvidia GPUs. If CoreWeave ever struggles to fully rent out those GPUs, Nvidia has promised to buy back unused capacity through Apr-32.
That means CoreWeave doesn’t carry as much risk of having idle, unprofitable infrastructure. In turn, this ensures GPUs keep running and generating revenue, even if demand temporarily dips.
It also committed $5B to Intel alongside a product tie-up to connect Nvidia GPUs with Intel processors for PCs and data centers. Beyond that, Nvidia invested in Musk’s xAI and later joined the AI Infrastructure Partnership with Microsoft, BlackRock and MGX to fund data centers and energy assets.
The move lands as OpenAI reports 700M weekly users yet still projects $44B cumulative losses before first profit in 2029, so cheaper capital tied to hardware is a bridge from usage to cash flow. There are real risks, including regulatory scrutiny of the structure and lower near-term margins for Nvidia, but the deal deepens lock-in around its platform.
That’s a wrap for today, see you all tomorrow.