
🧮 OpenAI CFO Sarah Friar just published OpenAI Strategy and Growing Metrics.
OpenAI’s growth playbook, Anthropic’s AI-work metric, Gemini’s usage spike, Meta’s layoffs, and DeepMind’s cheap misuse detection with activation probes and LLM checks.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (19-Jan-2026):
🧮 OpenAI CFO Sarah Friar just published OpenAI Strategy and Growing Metrics.
🗞️ Anthropic releases fourth Economic Index Report: New metric to understand how AI Is reshaping work globally
🛠️ New GoogleDeepMind paper shows that small activation probes can catch cyber misuse cheaply, and pairing them with LLM checks works best.
👨🔧 Google’s Gemini API traffic reportedly doubled in 5 months
🧠 Meta Lays Off 1,500 People in Metaverse Division
🧮 OpenAI CFO Sarah Friar just published OpenAI Strategy and Growing Metrics.
Compute rose from 0.2GW in 2023 to 0.6GW in 2024 to ~1.9GW in 2025, about 3x each year.
Annual recurring revenue (ARR), rose in step from $2B to $6B to $20B+, about 10x in 2 years. The earlier constraint was dependence on 1 compute provider, with capacity acting as a hard ceiling.
Now compute is managed as a portfolio across multiple providers, mixing premium training hardware with lower-cost serving to improve latency, throughput, and unit cost. Serving cost is described as trending toward cents per 1M tokens, which is what makes routine work usage viable.
Monetization now spans individual and team subscriptions, usage-based application programming interface (API) pricing, plus commerce and clearly labeled ads when users are close to a decision. She describes a flywheel where compute enables research, research improves products, adoption drives revenue, and revenue funds more compute, while Weekly Active Users (WAU) and Daily Active Users (DAU), counts of weekly and daily users, sit at all-time highs. The next push is agents that carry context over time and take actions across tools, paired with a 2026 focus on practical adoption.
🗞️ Anthropic releases fourth Economic Index Report: New metric to understand how AI Is reshaping work globally
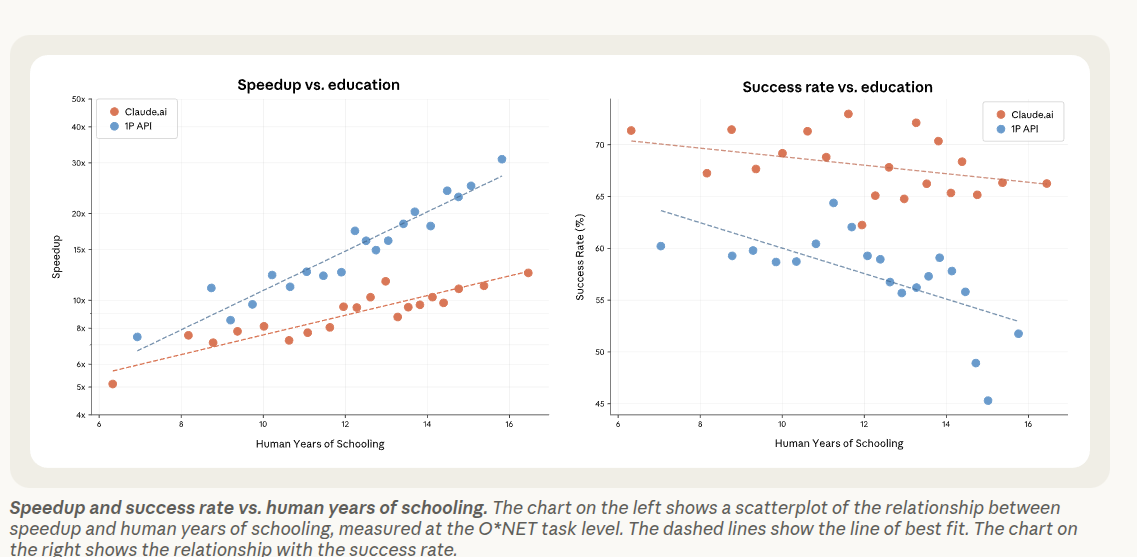
Anthropic measured what people do with Claude by analyzing real chats and API calls. It adds 5 “economic primitives” that label interactions by complexity, skills, autonomy, success, and purpose.
Early insights show that AI delivers the greatest time-savings on COMPLEX TASKS, that its usage patterns differ significantly across countries and economic contexts, and that AI's overall effects remain uneven across occupations and geographies.
Some key takeaway is that, coding stays central, adoption is uneven, and success drops on longer tasks.
The sample covers 1M Claude.ai conversations and 1M first-party (1P) application programming interface (API) records from Nov2025. Top 10 Occupational Information Network (O*NET) tasks, a US job-task database, are 24% of Claude.ai chats and 32% of 1P API traffic.
52% of the Claude.ai chat traffic is classified as this back-and-forth collaborative pattern rather than fully automated use. 74% of the first-party API records were labeled as work use, like coding, business writing, analysis, or other job tasks, rather than personal or hobby use.
The Anthropic AI Usage Index (AUI) compares usage to population and rises with gross domestic product (GDP) per capita, with 1% higher GDP linked to 0.7% more usage.
Within the US, state concentration fell as the Gini coefficient, an inequality measure, dropped from 0.37 to 0.32, projecting 2 to 5 years to parity if sustained.
The average task people bring to Claude.ai would take about 3.1h if done fully by a human, but about 15.4min when using Claude to help. “Success” is the share of tasks the system judges as completed correctly, and it estimates 67% success for Claude.ai chats.
For API use, where Claude is called by software inside apps, the estimated success rate is lower at 49%. So chat use looks faster and more often ends in a “worked” outcome than automated API workflows, in their measurement.
More time-consuming tasks are less likely to end in a successful outcome, based on their success classifier.
For API jobs, once the estimated “human-only” task length gets to about 3.5h, the success rate drops to around 50%, meaning about half of those tasks are judged to finish correctly.
For Claude.ai chats, success stays above 50% until tasks that would take about 19h human-only, then it falls to around 50%.
So the same “half of tasks succeed” point happens much earlier for API automation than for interactive chat, which likely reflects that humans can steer and fix issues during a chat.
Discounting speedups by success cuts the implied labor productivity growth boost, output per hour, from 1.8pp to 1.2pp for Claude.ai and 1.0pp for API.
Effective AI coverage weights task importance and success, lifting jobs like data entry keyers where AI works on core duties.
Covered tasks skew higher-education at 14.4 years versus 13.2 economy-wide, so removing them tends to deskill many jobs.
🛠️ New GoogleDeepMind paper shows that small activation probes can catch cyber misuse cheaply, and pairing them with LLM checks works best.

A probe is a tiny classifier that reads a model’s hidden signals to flag risky prompts, and it already informs Gemini deployments.
They found using probes across traffic can be over 10,000x cheaper than running an LLM monitor on every request with similar accuracy.
When the main model already computed activations for answering the user, a probe just does a small matrix read on those numbers, so the extra work is tiny.
An LLM monitor must run a fresh prompt like “is this safe,” which burns tokens, adds latency, and charges per request.
They train small classifiers on the model’s internal activations, then adjust pooling and aggregation so brief harmful snippets stand out even inside 1M token prompts.
Their MultiMax probes and a Max of Rolling Means Attention design choose strongest local windows, so long context noise does not wash out a harmful span.
They also cascade the probe with an LLM monitor, trusting the probe only at extreme scores and sending the rest to Flash, cutting cost roughly 50x at similar accuracy.
👨🔧 Google’s Gemini API traffic reportedly doubled in 5 months

Internal Google data shows Gemini API calls count surged from ~35B in March 2025 to ~85B in August 2025;
Google says Gemini Enterprise has hit 8M subscribers.
That jump is also reported to pull extra spend into adjacent Google Cloud products like storage and databases, not just the model endpoint itself.
Google is also betting on packaged enterprise software, where Gemini Enterprise sits closer to company data through connectors and permissions-aware internal search.
🧠 Meta Lays Off 1,500 People in Metaverse Division

Meta cut about 1,500 Reality Labs jobs and shut down VR studios Twisted Pixel, Sanzaru, and Armature, amid a shift of budget away from VR gaming and toward wearables and related AI features.
The cuts look like a pullback from first party VR content, not a company exit from VR hardware or the Quest platform.
Palmer Luckey who was fired by Mark Zuckerberg after acquiring his company for $2 billion writes a long viral note on Meta layoffs; says:
“This is not a disaster. They still employ the largest team working on VR by about an order of magnitude. Nobody else is even close. The “Meta is abandoning VR” narrative is obviously false, 10% layoffs is basically six months of normal churn concentrated into 60 days, strictly numbers wise.
The majority of the 1,500 jobs cut in Reality Labs (out of 15,000) were roles working on first-party content, internally developed games that competed directly with third party developers. I think this is a good decision, and I thought the same back when I was still at Oculus.”
In a capital-constrained environment, Luckey said, Meta’s resources are better spent on core technology and platform stability than on competing directly with developers it needs to keep VR viable.
He also framed the move as a return to Oculus’s original philosophy. Internally, he said, the company aimed “to NOT be Nintendo” — avoiding a closed, first-party-dominated model in favor of building an ecosystem that others could profit from.
That’s a wrap for today, see you all tomorrow.