
🎬 OpenAI debuts Sora 2 AI video generator app with sound and self-insertion cameos, API coming soon
OpenAI's Sora 2 is launched, Meta exposes reasoning inefficiencies, DeepSeek-V3.2-Exp drops technicals, and Thinking Machines shares fresh research insights.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (1-Oct-2025):
🎬 OpenAI debuts Sora 2 AI video generator app with sound and self-insertion cameos, API coming soon
🧠 Thinking Machines’s next research blog is published.
🔥 Meta reveals a massive inefficiency in AI’s reasoning process and gives a solution.
🛠️ Technical report of DeepSeek-V3.2-Exp
🎬 OpenAI debuts Sora 2 AI video generator app with sound and self-insertion cameos, API coming soon
They also released a new Sora social app that lets people make and share short clips with their own faces using a verified “cameo” feature. The cameo feature is just OpenAI’s way to let you put yourself inside an AI video. You do a one-time video and audio recording to verify it’s really you.
After that, the model can insert your face, body, and voice into generated scenes. You can share or revoke access with friends anytime and delete any video that uses your cameo.
It’s basically a controlled system for safe personal deepfakes with consent. Sora 2 adds synchronized audio and video, stronger physics realism, and tighter multi-shot control, so motions like jumps, rebounds, and flips behave in ways that feel consistent instead of warping to match a prompt.
The Sora iOS app is invite-only in US and Canada with Android later, and it launches free with the option to pay for extra generations during high demand. Clips inside the app are 10 seconds, created from prompts or photos without people, and you can share to a feed or just with friends, then others can remix the result.
OpenAI also mentions a liveness check to make impersonation harder during that identity step. Feed ranking can use your Sora activity, city-level location from IP, ChatGPT history that you can turn off, and engagement signals like likes and remixes, with steerable controls for what you want to see.
Parents get ChatGPT-based parental controls to cap infinite scroll, turn off personalization, restrict DMs, and apply stricter cameo permissions for teens.
Downloads carry content credentials and visible watermarks so exported videos are labeled as AI-generated. OpenAI says public-figure use and explicit or extreme content are blocked in the app, which matches the stricter guardrails seen at launch.
For creators who want higher fidelity, ChatGPT Pro users get access to Sora 2 Pro on sora[.]com, and an API is on the roadmap. Sora 2’s physics realism means the model keeps track of objects and forces over time, so a missed basketball shot rebounds off the backboard instead of teleporting to the hoop, which avoids the “overoptimistic” object morphing that older models sometimes showed.
Multi-shot control means the model can follow a sequence of directions across shots, carry world state between them, and keep characters and props consistent when the camera or scene changes. Audio-video sync matters because dialogue timing and effects like footsteps or splashes line up with motion, which reduces the uncanny feel that comes from off-beat sound.
The app’s ranking system is designed to favor creation over passive scrolling, with steerable preferences and periodic wellbeing checks, rather than optimizing for time spent. Sam Altman also posted product principles like long-term user satisfaction, user-controlled feeds, and creation priority, saying they will change or shut it down if it fails those goals.
OpenAI isn’t automatically blocking copyrighted material inside Sora videos. Instead, they’re taking the same approach they already use for image generation in ChatGPT. If someone makes a video that contains copyrighted characters, music, or styles, OpenAI won’t stop it up front.
The responsibility is on the copyright owner (for example, Disney, if it’s Mickey Mouse) to find the video and file a takedown request. Once that happens, OpenAI can remove it. So basically, they are not filtering copyrighted content in advance, they are only responding after the rights holder asks for removal.
🧠 Thinking Machines’s next research - super practical if you are training models on budgets

LoRA is usually seen as a more efficient way to train by adding an adapter layer on top of a base model, but it often comes with some performance trade-offs. This blog argues that, with the right setup, that trade-off disappears. That’s huge because it opens the door for people to train models even on local machines, or Google Colab.
This research gives LoRA a solid, repeatable formula. That turns post-training into something dependable instead of erratic, which fits perfectly with Thinking Machines’ focus on making AI outputs steady and trustworthy.
That matters for reliability, because it means you don’t have to gamble with whether LoRA will “work this time” or collapse. They give clear rules: put LoRA on all layers (not just attention), use about 10x the usual learning rate, and don’t crank the batch size too high.
With those simple rules, LoRA training curves follow the same path as full fine-tuning until the adapter runs out of space, and even then it fails gracefully, just slowing down instead of breaking. This removes randomness from the process. It’s no longer trial and error or chasing mysterious hyperparameters. It’s a recipe anyone can repeat and expect the same outcome. And because LoRA is cheaper (about two-thirds the compute of full fine-tuning), teams can run multiple trials and still get steady results, which adds another layer of consistency.
---
Note, Thinking Machines has said they are on a mission to make AI models reliable rather than erratic.
🎯 It has one simple but BIG idea: AI outputs can be consistent. While most call models non-deterministic, they claim it’s a solvable flaw.
Fixing randomness would make AI safe for high-stakes workflows. Hence, This research pushes the mission by giving a repeatable recipe that makes post‑training behave predictably like FullFT. They chart a low‑regret regime where LoRA’s loss‑vs‑steps curve matches FullFT until the adapter runs out of capacity, then it just slows rather than hitting a hard floor.
🔥 Meta reveals a massive inefficiency in AI’s reasoning process and gives a solution.

Large language models keep redoing the same work inside long chains of thought.
For example, when adding fractions with different denominators, the model often re explains finding a common denominator step by step instead of just using a common denominator behavior. In quadratic equations, it re explains the discriminant logic or completes the square again instead of calling a solve quadratic behavior. In unit conversion, it spells out inches to centimeters again instead of applying a unit conversion behavior.
🛑The Prblem with this approach is, when the model re explains a routine, it spends many tokens on boilerplate steps that are identical across problems which is wasted budget. So this paper teaches the model to compress those recurring steps into small named behaviors that it can recall later or even learn into its weights.
A behavior compresses that routine into a short name plus instruction like a tiny macro that the model can reference. At inference, a small list of relevant behaviors is given to the model or already internalized by training so the model can say which behavior it is using and skip the long re derivation.
Because it points to a named behavior, the output needs fewer tokens, and the saved tokens go to the new parts of the question. Behavior conditioned fine tuning teaches the weights to trigger those routines from the question alone so even without retrieval the model tends to use the right shortcut.
Compute shifts from many output tokens to a few input hints and weight activations which is cheaper in most serving stacks and usually faster too. Accuracy can improve because the model follows a tested routine instead of improvising a fresh multi step derivation that may drift.
⚙️ The Core Concepts
A behavior is a short name plus instruction for a reusable move, like inclusion exclusion or turning words into equations. The behavior handbook is a store of how-to steps, which is procedural memory, unlike RAG that stores facts. The authors frame the goal as remember how to reason, not just what to conclude, which matches the engineer’s point that remembering how to think beats thinking longer.

🧵Behavior Curation Pipeline
Step 1: Solving and reflecting
The process starts with a model (labeled LLM A) that gets a math question. It solves it normally, producing a full reasoning trace.
Then the same model reflects on that solution, asking: “What steps here are general tricks I could reuse later?”
From that reflection, it extracts behaviors. Each behavior has a short name plus an instruction, like triangle angle sum or inclusion exclusion.
Step 2: Building a handbook
These extracted behaviors are added to a behavior handbook. Think of it as a growing library of reasoning shortcuts. The handbook is procedural memory, so instead of facts like “Paris is in France,” it stores “how to” rules, like “angles in a triangle add to 180.”
Step 3: Using the handbook at test time
Now another model (LLM C, called the Student) faces new problems. During inference, it is given the problem plus a small selection of relevant behaviors from the handbook. It solves the problem while explicitly referencing these behaviors, so the reasoning trace is shorter and less repetitive.
Step 4: Self-improvement loop
The same idea can also be used for self-improvement. A model solves a problem once, extracts behaviors from that first attempt, then retries the problem using those behaviors as hints. This second try is usually more accurate than just a critique-and-revise method.
Step 5: Training with behaviors
There’s also a training path called behavior-conditioned supervised fine-tuning (SFT). Here, a Teacher model (LLM B) generates reasoning traces that explicitly include behaviors.
The Student is then trained on these behavior-annotated traces. After training, the Student doesn’t need behavior prompts anymore because it has internalized the patterns.

🛠️ Technical report of DeepSeek-V3.2-Exp

DeepSeek Sparse Attention is described in detail in the diagram below
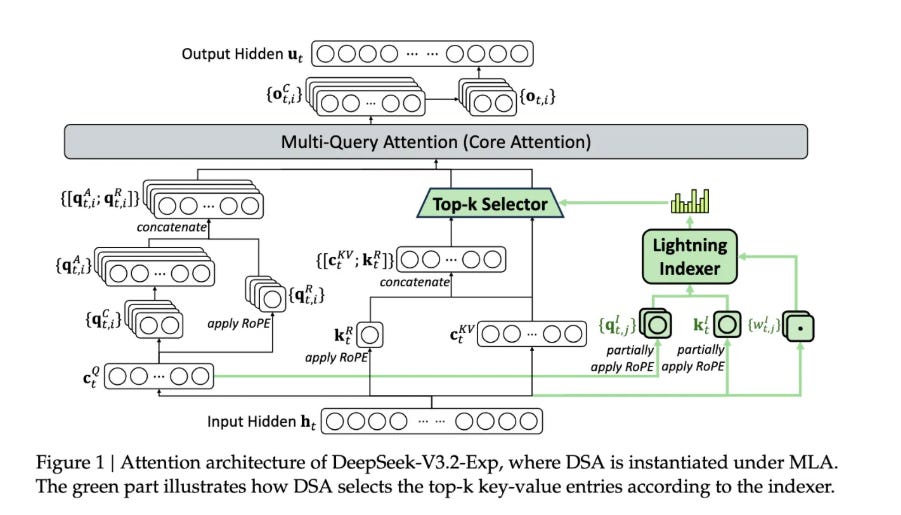
The setup works by using a “lightning indexer” that picks out the most relevant chunks from the context window. Then a “fine-grained token selection system” digs into those chunks to pull specific tokens into the limited attention window. This combo lets Sparse Attention models handle long contexts while keeping server demand low.
For long-context operations, the benefits of the system are significant. Preliminary testing by DeepSeek found that the price of a simple API call could be reduced by as much as half in long-context situations.
The lightning indexer scores past tokens for each query using a small number of indexer heads with ReLU and can run in FP8, then the model fetches only the chosen keys and values. Only the top set is attended per query, set to 2048 during training, which changes attention from quadratic in sequence length to roughly proportional to length times k.
DSA is instantiated under MLA using the multi-query variant so each key value entry is shared across all heads of a token, which makes kernels efficient on GPUs. Training adds a 2-stage schedule that is new here, a short dense warm-up that teaches the indexer to match dense attention with a KL loss, then a long sparse stage that adapts the whole model while applying the KL on only the selected set and detaching the indexer input from backprop.
Concrete details are given, warm-up 1000 steps with 16 sequences of 128K per step for 2.1B tokens at lr 1e-3, then sparse training 15000 steps with 480 sequences of 128K per step for 943.7B tokens at lr 7.3e-6. Post-training keeps the same data as V3.1 to isolate the DSA effect, but switches to a single mixed RL stage using GRPO that merges reasoning, agent, and preference tuning with specialist distillation feeding the final checkpoint.
System results are included, end-to-end token cost curves on H800 clusters and a note on a masked MHA mode that mimics DSA for short prefills. The code is opened, they provide an inference implementation and kernels so the sparse pattern is reproducible.
That’s a wrap for today, see you all tomorrow.