
🔥 OpenAI dropped o3-mini: MASSIVE Improvement in Coding Tasks, outperforms o1 Model and 15x Cheaper
o3-mini revolutionizes coding efficiency, Semianalysis uncovers DeepSeek’s AI economics, and DeepSeek’s founder declares: "We’re done following. It’s time to lead."
Read time: 7 min 10 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (31-Jan-2025):
🔥 It’s here: OpenAI just dropped o3-mini: MASSIVE Improvement in Coding Tasks, outperforms o1 Model and 15x Cheaper
📚 Semianalysis Pulished Detailed Report On DeepSeek Debates: Chinese Leadership On Cost & True Training Cost
🏆 Interview with Deepseek Founder Liang Wenfeng (from July 2024): "We’re Done Following. It’s Time to Lead"
🔥 It’s here: OpenAI just dropped o3-mini: MASSIVE Improvement in Coding Tasks, outperforms o1 Model and 15x Cheaper
→ ChatGPT Plus, Team, and Pro users can access o3-mini immediately, with Enterprise access coming within a week.
The Most Important Key points are
Massive performance numbers for Coding significantly exceeding o1 model.
Pro users ($200 per month): unlimited o3-mini.
Plus ($20 per month) & Team: have up to 150 messages per day with o3-mini and 50 message per week on o3-mini-high. Pro users have unlimited access to o3-mini-high.
Inference is 24% faster than o1-mini
We are getting o1-level model, in-fact with many benchmarks, a better than o1-level model, with 2-3x faster speed and at a price point that is 13x-15x cheaper. 🫡

Key Highlights 👇
→ In ChatGPT, o3-mini is released now with 2 modes the regular o3-mini and o3-mini-high. It uses medium reasoning effort by default.
→ Paid users (Pro, Plus and Team) can choose o3-mini-high in the model picker for a higher-intelligence version that takes slightly longer for responses
→ Free plan users can also access o3-mini in ChatGPT by selecting 'Reason' in the message composer or regenerating a response, marking the first time a reasoning model is available to free ChatGPT users.
→ o3-mini includes highly requested developer features such as function calling, Structured Outputs, and developer messages, making it production-ready immediately.
→ Like o1-mini and o1-preview, o3-mini supports streaming and offers developers a choice of three reasoning effort levels—low, medium, and high—to optimize for different use cases, allowing it to "think harder" on complex tasks or prioritize speed when latency is critical.
→ It does not support vision capabilities; for visual reasoning tasks, developers should continue using o1.
→ o3-mini is being rolled out in the Chat Completions API, Assistants API, and Batch API, starting today for select developers in API usage tiers 3-5. Developers can also adjust the reasoning effort level (low, medium, high) based on their application needs, allowing for more control over latency and accuracy trade-offs.
→ o3-mini will replace o1-mini in the model picker, providing higher rate limits and lower latency, making it ideal for coding, STEM, and logical problem-solving.
→ o3-mini integrates search functionality to provide up-to-date answers with links to web sources.
Pricing (o3-mini vs o1 vs DeepSeek)
One of o3-mini’s most notable advantages is its cost efficiency: It’s 63% cheaper than OpenAI o1-mini and 93% cheaper than the full o1 model, priced at $1.10/$4.40 per million tokens in/out (with a 50% cache discount).
While DeepSeek’s API provides R1 at just $0.14/$0.55 per million tokens in/out, making it far more affordable, its Chinese origin raises geopolitical and security concerns for enterprises handling sensitive data. This makes OpenAI a safer bet for security-conscious users in the U.S. and Europe.
A recent report covered in Wired showed that DeepSeek succumbed to every jailbreak prompt and attempt out of 50 tested by security researchers, which may give OpenAI o3-mini the edge over DeepSeek R1 in cases where security and safety are paramount.
OpenAI also said “This model continues our track record of driving down the cost of intelligence—reducing per-token pricing by 95% since launching GPT-4—while maintaining top-tier reasoning capabilities.”
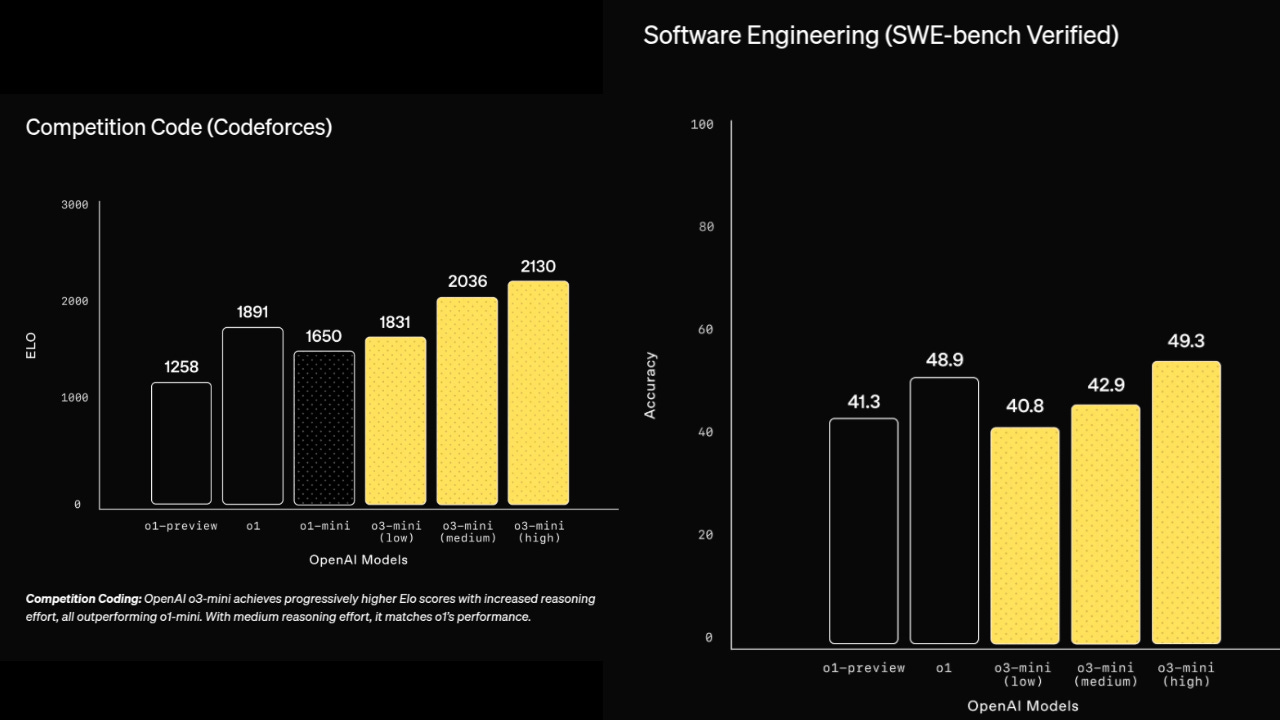
Performance (The best coder in the world)
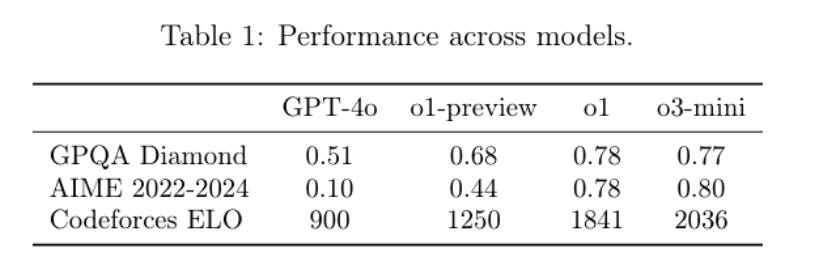
Similar to o1, OpenAI o3-mini is optimized for reasoning in math, coding, and science.
More Accurate & Clear: Preferred by experts 56% of the time over o1-mini, with 39% fewer major errors.
STEM Leader: Matches or beats o1-mini on benchmarks like AIME, GPQA, and FrontierMath.
Top Software Engineering: OpenAI's best model on SWEbench for coding tasks.
24% Faster: Responds in 7.7 seconds vs. o1-mini's 10.16 seconds.
Safer than GPT-4o: Significantly better in safety and jailbreak tests.
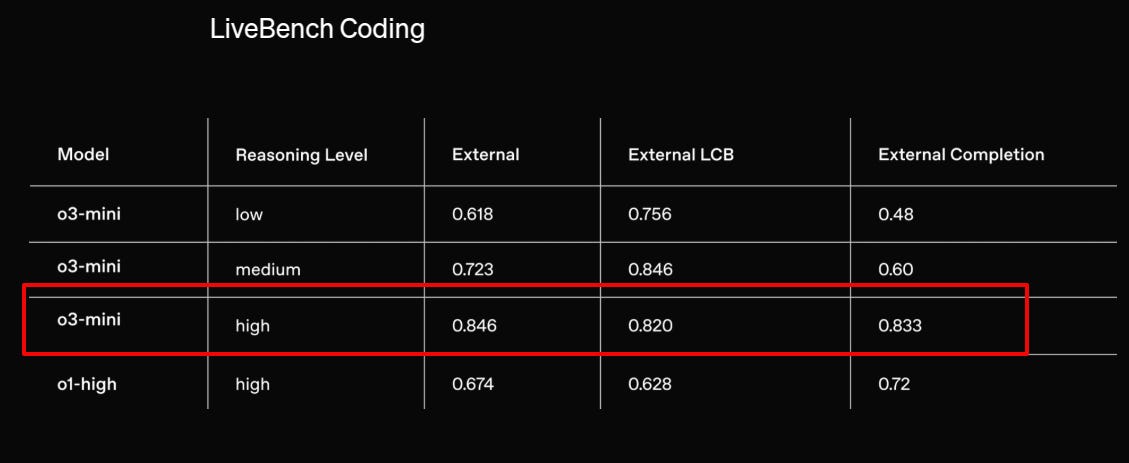
Special note on o3-mini’s superior performance on LiveCodeBench
Note, that LiveCodeBench is a holistic and contamination-free evaluation benchmark of LLMs for code that continuously collects new problems over time.
The o3-mini model achieves 0.846 in "External," which is significantly higher than o1-high's 0.674,
Note on the Context Window of 03-mini
o3-mini’s context window — the number of combined tokens it can input/output in a single interaction — is 200,000, with a maximum of 100,000 in each output. That’s the same as the full o1 model and outperforms DeepSeek R1’s context window of around 128,000/130,000 tokens. But it is far below Google Gemini 2.0 Flash Thinking’s new context window of up to 1 million tokens.
📚 Semianalysis Pulished Detailed Report On DeepSeek Debates: Chinese Leadership On Cost & True Training Cost

🎯 Key Takeaways from the Report
→ DeepSeek reportedly has access to around 50,000 GPUs, including 10,000 H800s, 10,000 H100s, and growing orders of H20 GPUs. Nvidia has produced over a million China-specific GPUs, which DeepSeek leverages for training, inference, and research.
→ DeepSeek’s GPU investments exceed $500M, with a total server CapEx estimated at $1.4 billion.
→ DeepSeek may be operating at a loss, offering inference at cost to gain market share. If this trend continues, it could reshape AI pricing models, forcing competitors to lower costs and accelerating AI adoption worldwide.
🏆 Interview with Deepseek Founder Liang Wenfeng (from July 2024): "We’re Done Following. It’s Time to Lead"

The interview was conducted shortly after the company’s open-source V2 model catapulted it to fame.
Liang Wenfeng, founder of DeepSeek, has triggered a major shift in the AI landscape from the day DeepSeek-R1 was released.
→ Raised in the small Chinese village of Mililing, Liang’s journey from a math-loving student to a hedge fund quant and AI entrepreneur has turned him into a national hero in China. His transition from automated trading at High-Flyer to generative AI has positioned him as a key figure in China's AI race against the US.
🎯 Key Takeaways from the Interview:
→ DeepSeek set prices based on cost calculations, not market disruption. But ByteDance, Alibaba, Baidu, and Tencent were forced to follow, mirroring the subsidy-driven battles of the internet era.
→ China’s AI efficiency gap is massive. Chinese models require 4x the compute of top Western models due to training inefficiencies. DeepSeek is focused on closing this gap with superior architectures.
→ DeepSeek believes long-term R&D is the real driver of global AI dominance. Unlike competitors, DeepSeek won’t build consumer apps but will let others develop products using its models.
→ The industry needs ecosystems, not monopolies. Future AI will be driven by specialized foundational models, not a single dominant player.
📡 NVIDIA deployed DeepSeek-R1 671-bn param model to NVIDIA NIM microservice
🎯 The Brief
NVIDIA depoloyed DeepSeek-R1, into NVIDIA NIM, making it available as a microservice on build.nvidia.com. This enables secure enterprise-scale AI deployments with industry-standard APIs. The model delivers up to 3,872 tokens per second on a single NVIDIA HGX H200 system, leveraging FP8 Transformer Engines and 900 GB/s NVLink bandwidth.
⚙️ The Details
→ DeepSeek-R1 will be great for tasks requiring logical inference, math, coding, and language understanding. It follows test-time scaling, meaning it performs multiple inference passes to refine answers using chain-of-thought, consensus, and search methods.
→ Using NVIDIA Hopper architecture, DeepSeek-R1 can deliver high-speed inference by leveraging FP8 Transformer Engines and 900 GB/s NVLink bandwidth for expert communication.
→ As usual with NVIDIA's NIM, its a enterprise-scale setu to securely experiment, and deploy AI agents with industry-standard APIs.
→ In the official announcement NVIDIA says "Getting every floating point operation per second (FLOPS) of performance out of a GPU is critical for real-time inference. The next-generation NVIDIA Blackwell architecture will give test-time scaling on reasoning models like DeepSeek-R1 a giant boost with fifth-generation Tensor Cores that can deliver up to 20 petaflops of peak FP4 compute performance and a 72-GPU NVLink domain specifically optimized for inference."
→ Developers can experiment now via NVIDIA NIM microservice, with API support coming soon. And you can play with it directly here.
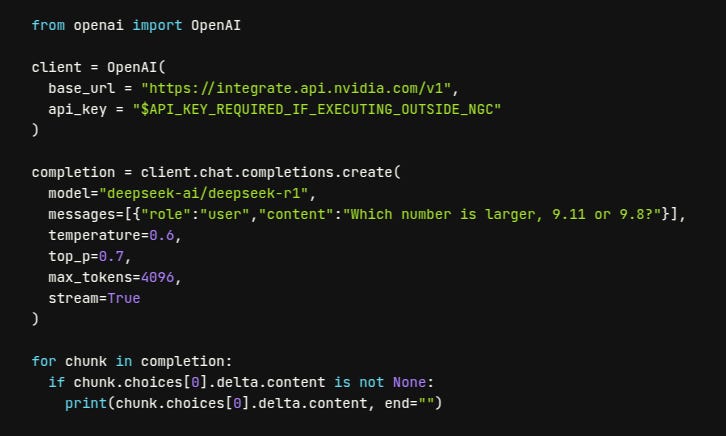
Example code run it with NVIDIA NIM
That’s a wrap for today, see you all tomorrow.