
🎯 OpenAI drops GPT-5.2 right in the middle of its own ‘Code Red’ storm.
GPT-5.2 lands during OpenAI’s internal chaos, shatters GDPVal benchmarks, and shows a 390X efficiency leap in just 12 months.

Read time: 8 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (12-Dec-2025):
🎯 OpenAI drops GPT-5.2 right in the middle of its own ‘Code Red’ storm.
📡 GPT-5.2 Thinking’s score on GDPVal is a BIGGER deal than you think
🎯 AI’s “supersonic tsunami” is in full motion with a massive 390X efficiency jump in just a year for GPT’s best model.
🎯 OpenAI drops GPT-5.2 right in the middle of its own ‘Code Red’ storm.

OpenAI’s latest AI model GPT-5.2 is here.
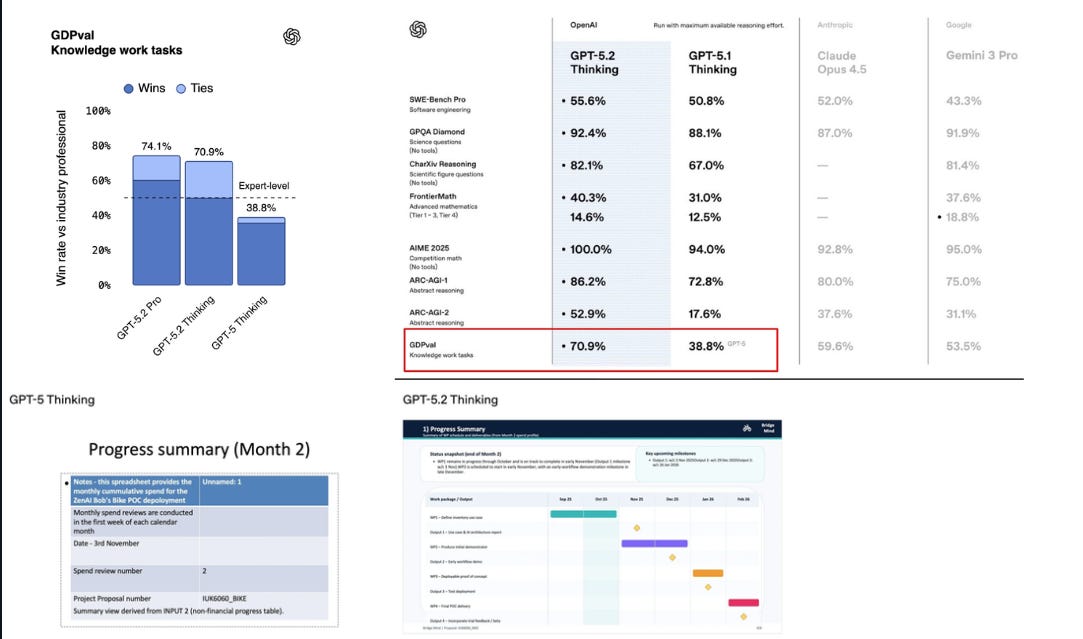
On the GDPval benchmark it beats or equals human-experts in 70.9% of tasks, while producing outputs over 11x faster at <1% cost.
GDPval measures well specified work like sales decks, workforce spreadsheets, shift schedules, and videos, so this signals better hands on help with actual real-life deliverables.
For coding, GPT-5.2 Thinking reaches 55.6% on SWE-Bench Pro across 4 languages and 80.0% on SWE-bench Verified, mapping to more reliable patches, refactors, and features.

Response errors on de identified ChatGPT queries drop from 8.8% to 6.2%, so everyday research and writing should contain fewer wrong claims.
GPT‑5.2 Thinking sets a new state of the art in long-context reasoning, achieving leading performance on OpenAI MRCRv2. GPT-5.2 Thinking keeps almost perfect recall of relevant information across very long inputs, while GPT-5.1 Thinking loses accuracy as the context gets bigger.

Vision improves with 88.7% on CharXiv reasoning and 86.3% on ScreenSpot Pro, so it reads charts and software screens with fewer mistakes.
Tool use jumps to 98.7% on Tau2 Telecom and 82.0% on Tau2 Retail, enabling steadier multi step workflows like data pulls, support case resolution, and final document generation.
For abstract reasoning, GPT-5.2 Thinking hits 52.9% on ARC AGI 2 and GPT-5.2 Pro reaches 90.5% on ARC AGI 1, with math at 40.3% on FrontierMath tiers 1 to 3.
Availability starts now for ChatGPT paid plans and the API with models gpt-5.2, gpt-5.2-chat-latest, and gpt-5.2-pro, pricing $1.75/1M input, $14/1M output, with 90% discount on cached inputs.
GPT-5.1 remains in ChatGPT for 3 months as a legacy option, and Pro adds an high reasoning effort setting for the hardest requests.
GPT-5.2 Thinking is their first model that performs at a human expert level on GDPval.

GDPval is built around economically valuable knowledge work and covers 44 occupations drawn from the 9 largest sectors of the US economy that contribute most to GDP, such as finance, healthcare, law, and software.
The 5.2 model also lowers the chance of hallucinations when people use GPT-5.2 for research, writing, analysis, or decision support, which makes it a safer choice for everyday professional work.

GPT-5.2 Thinking gets about 89% of scientific figure questions right on this CharXiv vision benchmark, while GPT-5.1 Thinking is around 80%.

CharXiv is a dataset of real charts from scientific papers where the model has to answer questions that depend on reading axes, legends, trends, and relationships, not just spotting simple labels.
The gap here means GPT-5.2 is noticeably better at correctly interpreting information-dense charts, which is exactly the kind of visual reasoning that earlier multimodal models often struggled with.
For professionals, this translates to more reliable help when asking the model to read dashboards, experiment plots, KPI charts, or other complex visual reports and then reason over what they show.
GPT-5.2 Thinking is better at understanding where things sit relative to each other inside an image, so it can label many more motherboard components with boxes that actually match their real positions.

GPT-5.1 Thinking only manages to tag a few ports and regions, and its boxes are rough and incomplete, which shows it has a weaker grasp of the overall layout.
This kind of spatial awareness is exactly what ScreenSpot-Pro is testing when it uses complex interface or hardware screenshots, so the example is showing that GPT-5.2’s accuracy comes from genuinely stronger layout reasoning, not just better text recognition.
For practical work, this means GPT-5.2 is more reliable for tasks like tagging UI elements, auditing screenshots, documenting hardware, or building automation that depends on correctly understanding where each visual element appears on the screen.
GPT-5.2 Thinking is much more reliable than earlier models at using external tools across long, multi-step customer support scenarios.

On the telecom benchmark, GPT-5.2 Thinking with high reasoning effort reaches about 98.7% accuracy, slightly ahead of GPT-5.1 Thinking, and even with no extra reasoning it stays clearly ahead of GPT-5.1 Thinking and GPT-4.1.
On the retail benchmark, GPT-5.2 Thinking again leads, with higher accuracy both in the high-effort and no-effort settings, which means it keeps making the right tool calls even when you want faster, cheaper runs.
🎯 AI’s “supersonic tsunami” is in full motion with a massive 390X efficiency jump in just a year for GPT’s best model.

ARC Prize just verified GPT-5.2 Pro (X-High) at 90.5% on ARC-AGI-1 for $11.64 per task. Which beats prior records and shows a ~390X efficiency jump in just a year.
And GPT-5.2 Pro (High) hits 54.2% on ARC-AGI-2 for $15.72 per task.
For context, ARC-AGI tasks are small unseen puzzles that stress on-the-fly generalization, so gains here signal less reliance on memorized data.
The benchmark’s efficiency target is $0.20 per task, but the new state of the art still costs $11.64 per task, which is ~58x more expensive than the goal.
Humans are at 100% on these tasks, while the best verified model is 90.5%, so there is still a non-trivial accuracy gap.
📡 GPT-5.2 Thinking’s score on GDPVal is a BIGGER deal than you think
Unlike classic benchmarks that are just text in and text out, GDPval tasks come with reference files and context, and the expected outputs are full deliverables like documents, slides, spreadsheets, diagrams, audio, or video files with “Economic Value”.
It’s a benchmark from OpenAI that tests how well AI models do full, real-world work tasks like spreadsheets, reports, and slide decks, compared directly against experienced human professionals.
GDPval is built around economically valuable knowledge work and covers 44 occupations drawn from the 9 largest sectors of the US economy that contribute most to GDP, such as finance, healthcare, law, and software.
The full benchmark has 1,320 tasks (with a 220 task gold subset) and each task is based on an actual work product like a legal brief, engineering blueprint, customer support exchange, or nursing care plan.
Tasks were written and reviewed by industry professionals with about 14 years of experience on average, and they went through multiple expert review rounds so they look like the kind of assignments real employers give.
Each task usually takes a human expert around 4–8 hours to do, with median completion times of 4–5 hours and typical task value in the $150–$200 range, so these are serious multi hour deliverables not toy prompts.
For each task, an expert first submits a “gold” solution, then the AI model gets the same prompt and files and generates its own complete deliverable.
A separate panel of expert graders from that same occupation then compares the human and model outputs blind, without knowing which is which, and marks whether the model’s deliverable is better, about as good, or worse than the expert’s.
The main GDPval score is the win rate, which is simply the share of tasks where the model’s work is judged as good as or better than the expert deliverable (wins plus ties).
So when “GPT-5.2 wins 71% on GDPval,” that means that on those evaluated tasks, human graders preferred the model’s output or thought it matched the expert’s in about 71% of head to head comparisons.
OpenAI also uses GDPval to estimate speed and cost, finding that strong models can complete these tasks roughly 90–100x faster and around 100x cheaper than human experts if only raw model time and API cost are counted.
In practice, GDPval is best thought of as “how close is this model to a seasoned human-specialist when asked to produce a real client facing deliverable, with all the messy context and formatting that job actually involves.”
That’s a wrap for today, see you all tomorrow.