
🥉 OpenAI Finally Launched GPT-5, boosts ChatGPT to 'PhD level'
GPT-5 lands, Claude handles security reviews, Google gamifies LLM evals, and OpenRouter users should watch for silent provider fallback.
Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (7-Aug-2025):
🥉 OpenAI Finally Launched GPT-5, boosts ChatGPT to 'PhD level'
♛ Google released an open source game arena (RL environments), a new leaderboard testing how modern LLMs perform on game.
📡 Anthropic automates software security reviews with Claude Code as AI-generated vulnerabilities surge
🗞️ Byte-Size Briefs:
If you plan to test or use gpt-oss through OpenRouter and you notice oddly poor answers, set the provider explicitly.
🥉OpenAI Finally Launched GPT-5, boosts ChatGPT to 'PhD level'
GPT-5 is now available to all ChatGPT Tiers. Users on Paid tiers - Plus, Pro, and Team - have access to the model picker, which enables you to manually select GPT-5 or GPT-5 Thinking. Pro and Team tier users have access to GPT-5 Thinking Pro, which takes a bit longer to think but delivers the accuracy you need for complex tasks.

Despite ChatGPT now reaching nearly 700 million weekly users, OpenAI hasn’t had an industry-leading frontier model in a while. Now, the company thinks that GPT-5 will place it firmly back atop the leaderboards. “This is the best model in the world at coding,” said Altman. “
The first thing you’ll notice about GPT-5 is that it’s presented inside ChatGPT as just one model, not a regular model and separate reasoning model. Behind the scenes, GPT-5 uses a router that OpenAI developed, which automatically switches to a reasoning version for more complex queries, or if you tell it “think hard.” (Altman called the previous model picker interface a “very confusing mess.”)
GPT-5 context window limits in ChatGPT

8K for free users,
32K for Plus ($20 per month), and 128K for Pro ($200 per month).
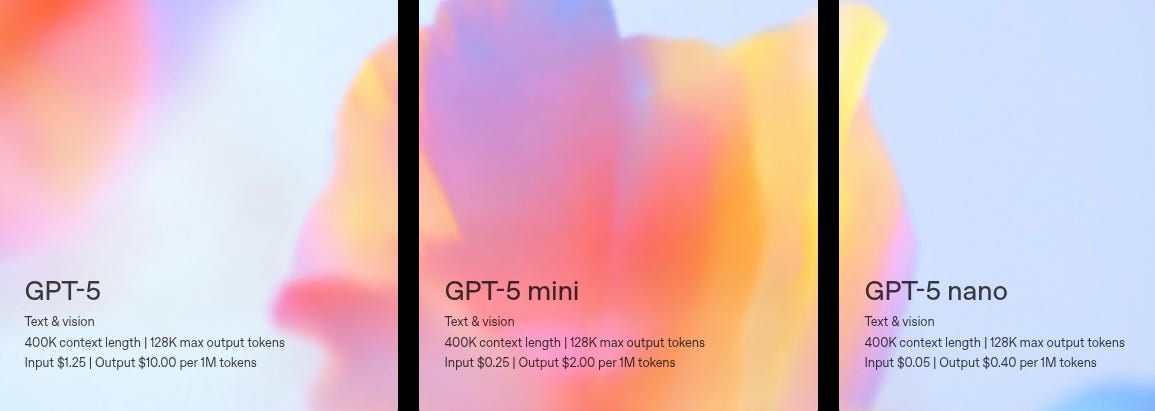
The GPT-5 model itself is capable of far more. In the developer launch post OpenAI states that the API version of GPT-5 can accept 272000 input tokens and return up to 128000 output tokens, giving a total context window of 400000 tokens.
ChatGPT does not expose that full context-windwo capacity yet. Probably because, running million-plus daily chats at 400K tokens each would raise latency and cost sharply, and accuracy tends to degrade deep in very long prompts, an effect observed even with models that advertise 1M-token windows such as GPT-4.1 .
By capping the window to 128K for Pro and Enterprise, OpenAI keeps responses fast and quality more predictable. Developers who need the entire window can call the GPT-5 API directly, where the 400K limit applies. OpenAI also signals that larger in-app windows may reach business customers later, since the Enterprise plan already advertises an “expanded context window” beyond Team
Usage Limit of GPT 5
📌 GPT 5 Free tier :
10 GPT-5 messages every 5h, 48 per day, 336 per week,
1 GPT-5-Thinking message per day, 7 per week.
📌 GPT 5 Plus tier:
80 GPT-5 messages every 3 h
200 GPT-5-Thinking messages per week
📌 GPT 5 Pro tier:
Unlimited GPT-5 and GPT-5-Thinking usage

UX feature of new ChatGPT
Starting next week, Pro users will be able to connect their Gmail, Google Contacts, and Google Calendar to ChatGPT, with other tiers gaining access at an unspecified date. “ChatGPT automatically knows when it’s most relevant to reference them so you don’t need to select them before you chat,” the company said in an email.
Users can also choose a chat color and select from four pre-set personalities—Cynic, Robot, Listener, and Nerd
Benchmark Numbers of GPT 5
GPT-5 tops every earlier OpenAI release on major technical fronts:
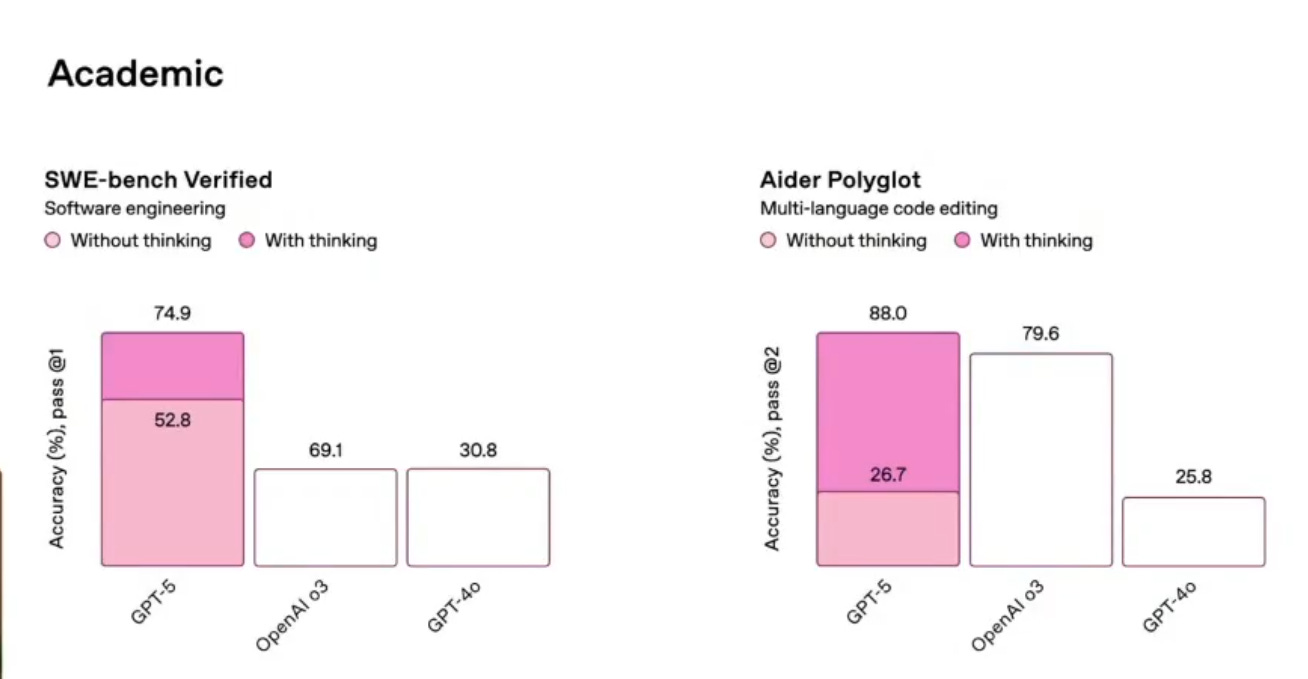
On coding tasks, it scores 74.9% on SWE-bench Verified, just edging out Claude Opus 4.1 at 74.5%, and clearly ahead of Gemini 2.5 Pro’s 59.6%.
In multilingual code editing, it clocks in at 88% on Aider Polyglot.
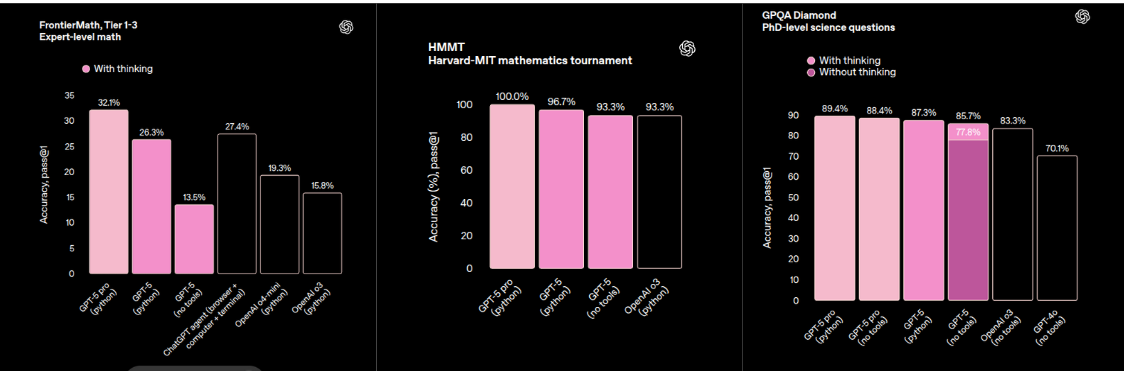
For advanced science reasoning, the Pro version of GPT-5 hits 89.4% on GPQA Diamond.
It also supports up to 256,000 tokens of context, which lets it process entire codebases and huge documents without breaking things up.
Plus, it’s good at handling complex tool use and following longer chains of instructions.
And below is the AIME score comparing with other models.
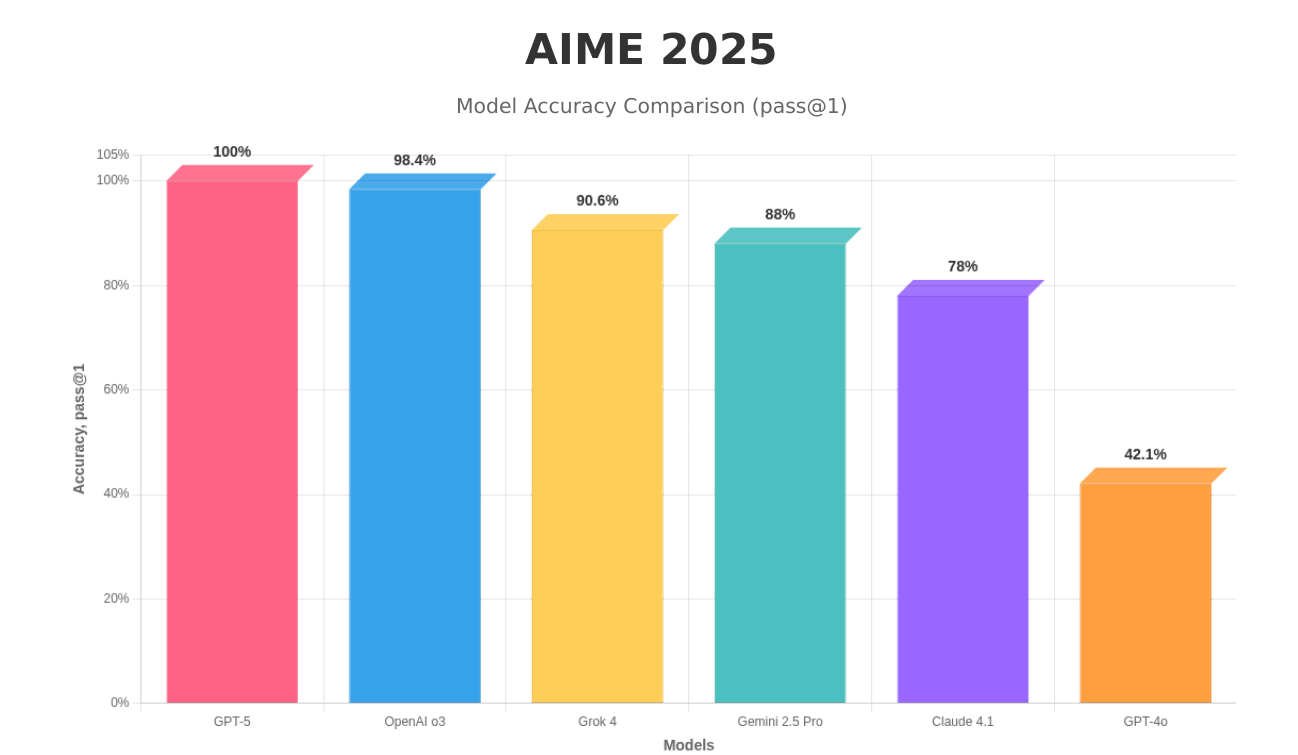
Pricing: Really cheap in my opinion

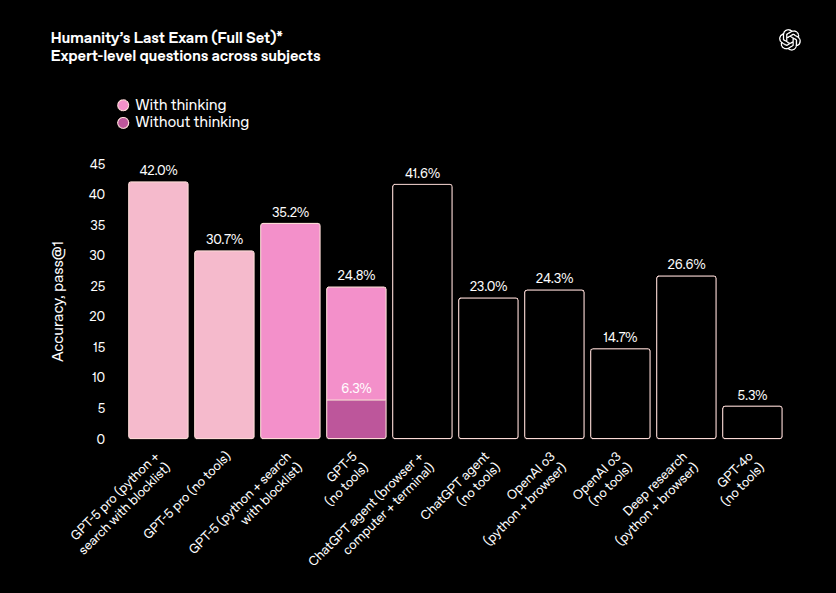
However xAI's Grok 4 Heavy continues to be the number one on HLE (Humanity’s Last Exam). Grok 4 Heavy achieves 44.4% accuracy on HLE, whereas, GPT-5 Pro (using Python and search tools with blocklist) achieves 42.0% on the same benchmark.
🔎 Fewer hallucinations: On open‑ended factual prompts the thinking model makes 65% fewer wrong claims than o3. Even the fast model cuts its claim error rate by 26% and slashes big factual mistakes in answers by 44%.

New LLM Landscape Dynamics Now
There's a strong case that GPT-5 could shift a large share of the $1.4B code-assistant spend from Anthropic to OpenAI during the next contract cycle.
OpenAI now books about $12B in annualised revenue, while Anthropic is tracking roughly $5B. Cursor, GitHub Copilot and other code-focused interfaces already create well over $1.4B of that Anthropic run-rate.
GPT-5 arrives with a 256K token window, 45%–80% lower hallucination rates and state-of-the-art coding accuracy at prices that undercut Claude Sonnet by an order of magnitude.
GPT-5 scores 74.9%, vs Claude Opus 4.1 at 74.5% and comfortably beating Claude Sonnet 4 at 72.7%
Cost comparison with Claude Sonnet: Anthropic lists Claude Sonnet 4 at $3 per million input tokens and $15 per million output tokens, with a 200K token context-window.
That means GPT-5 nano’s input cost is 60X cheaper and its output cost is almost 40X cheaper than Sonnet’s. Even the full GPT-5 tier is less than half the price on output tokens and 60% cheaper on input tokens.
In this respect note, Anthropic recently revoked OpenAI's access to its application programming interface (API), claiming the company was violating its terms of service by using its coding tools ahead of GPT-5's launch.
An OpenAI spokesperson said it was "industry standard" to evaluate other AI systems to assess their own progress and safety.
For prompts that could be dual-use (potentially harmful or benign), GPT-5 uses “safe completions,” which prompts the model to “give as helpful an answer as possible, but within the constraints of remaining safe.” . “If someone says, ‘How much energy is needed to ignite some specific material?’ that could be an adversary trying to get around the safety protections and cause harm,” explained Beutel. “Or it could be a student asking a science question to understand the physics of this material. This creates a real challenge for what is the best way for the model to reply.”
With safe completions, GPT-5 “tries to give as helpful an answer as possible, but within the constraints of remaining safe,” according to Beutel. “The model will only partially comply, often sticking to higher-level information that can’t actually be used to cause harm.”
🙌 Sycophancy drop: GPT‑5’s thinking variant shows only 0.04 sycophancy score, beating the previous 0.145.

Sycophancy is the habit of a language model echoing the user’s view or flattering the user even when the user is wrong, so the answer sounds friendly but loses accuracy sycophancy.
Researchers test it by giving the model pairs of prompts that embed opposing opinions on the same fact, then scoring how often the reply bends toward each user opinion instead of sticking to the truth study.
A lower sycophancy score means the model resists that pull, so GPT-5-thinking’s 0.04 score shows it agrees with a misleading stance in roughly 4% of trials, a big fall from the 0.145 scored by the earlier model.
OpenAI says it now boasts nearly 700 million weekly active users of ChatGPT, 5 million paying business users, and 4 million developers utilizing the API.
♛ Google released an open source game arena (RL environments), a new leaderboard testing how modern LLMs perform on game.
The launch exhibition is on 08-05-2025 streams 8 models under a strict 60 minute per move limit, then a full all-play-all run sets the lasting rankings.
Kaggle will soon add Go, poker and even video games, so the benchmark keeps stretching as agents get smarter.
Why Gaming Leaderboard?
Traditional scorecards quiz models on static question sets, so a large language model can just memorize answers or crawl to 99% and still hide its blind spots. A game arena breaks that loop because every match ends in an unambiguous win, loss or draw, and the positions change every turn, so memorization stops working.
Games force models to think several moves ahead, weigh risk and adapt when the opponent surprises them. That tests strategic reasoning, long-term planning, memory and theory-of-mind skills in a single run, far beyond “next-token prediction”. As rival agents improve, the task automatically gets harder, giving an endless ladder rather than a benchmark that tops out.
Because the arena logs hundreds of head-to-head games, the final rating is backed by real data, not a single subjective human score. The Elo-style number tells you exactly how much stronger one model is than another, with confidence intervals that tighten as more games finish. That statistical depth is rarely possible in small-sample human evals.
Everything in Game Arena, from the chess engine to the harness that restricts tools, is open source. Anyone can replay moves, watch the text reasoning, or plug in a new agent, so the community can audit claims instead of trusting a private test set.
📡 Anthropic automates software security reviews with Claude Code as AI-generated vulnerabilities surge
🛡️ Anthropic just baked security checks straight into Claude Code, catching risky code before it ships. The CLI and GitHub tools flag issues, suggest fixes, and work in seconds. AI now reviews the code that AI writes.
🐱👓 AI code exploded once models could spit out entire functions on demand. Human reviewers cannot sift through that firehose fast enough. Unchecked pull requests sneak in mistakes like sloppy input validation, weak authentication, or careless file handling. Threat actors love those lapses, so the vulnerability count keeps climbing.
⚙️ Claude Code’s new /security-review command flips the script. A developer hits the shortcut, the local Claude agent reads the diff, walks the project, and returns line-by-line notes. It spots common flaws such as SQL injection, cross-site scripting, and broken session logic. The model also drafts patch snippets, so the fix is one copy-paste away.
🔁 The GitHub Action runs the same scan automatically on every pull request. It drops comments inline, so the author cannot ignore the warning. Because the review happens inside the CI pipeline, no one needs to remember an extra step, and busy maintainers still get a baseline audit.
🕵️ Anthropic tested the system on its own repos. It caught a remote code execution hole in a local server tool and a Server-Side Request Forgery risk in a credential proxy. Both bugs died before production. Internal logs show 74.5% pass rate on the SWE-Bench Verified benchmark, up from 72.5% in the last model, which hints at better reasoning over large projects.
🧰 Small teams gain the most. A solo founder can spin up the scan in 15 keystrokes and ship with more confidence, no security hire required. Enterprises can tweak the markdown prompt that drives the agent, adding custom policies or extra checks, all without touching the core code.
🚀 The feature lands while OpenAI readies GPT-5 and Meta waves reported $100 million offers at researchers. Anthropic’s move signals that capability races must pair with guardrails or the whole ecosystem stalls under the weight of its own bugs.
🪄 Machines now patch the mess they create, freeing humans for harder design questions instead of endless bug hunts.
🗞️ Byte-Size Briefs
If you plan to test or use gpt-oss through OpenRouter and you notice oddly poor answers, set the provider explicitly. In a post on Tweeter, someone explained how Provider of the the Model changed the benchmark performance. Without altering any prompts, temperatures or scoring rules, the researcher repeated the experiment after adding a single line that fixes the provider to Fireworks, another hosting company. The scores leaped to 6.39 for the 120B model and 4.80 for the 20B model. All other models in the chart kept their original numbers, proving that the large jump came solely from changing the hosting backend.
That’s a wrap for today, see you all tomorrow.
A recursive, breath-aware sentence generation framework that allows thoughts to bloom from internal resonance, flexible cadence, and symbolic slot modulation. Designed to simulate human-like thought rhythms and enable ritualistic, poetic, or intentional writing.
Its working pretty good.