
🗞️ OpenAI has proposed giving Washington 5% of its $852B business to ease AI pressure.
OpenAI’s Washington 5% proposal, Fable 5 safety routing to Opus, Meta limiting Claude/Codex use, MCP server patterns, quantized reasoning efficiency, NVIDIA 30B model 2.42x speedup

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (03-July-2026):
🗞️ OpenAI has proposed giving Washington 5% of its $852B business to ease AI pressure.
🗞️ Safety Router Diverts More Prompts From Fable 5 To Opus 4.8
🗞️ On Claude Fable 5: The below case may be an extreme case but it still shows how quickly Fable 5 classifiers can reroute routine coding to Opus.
🗞️ “The Red Queen Gödel Machine: Co-Evolving Agents and Their Evaluators”
🗞️ The Information: Meta has reportedly limited engineer use of Claude Code and Codex because rival model outputs could contaminate Meta’s own AI training data and create contractual trouble with Anthropic and OpenAI.
🗞️ “MCP Server Architecture Patterns for LLM-Integrated Applications”
🗞️ “Quantized Reasoning Models Think They Need to Think Longer, but They Do Not”
🗞️ NVIDIA made a 30B language model write 2.42x faster with 98.7% retained quality.
🗞️ FT: OpenAI has proposed giving Washington 5% of its $852B business to ease AI pressure.
The idea borrows from Alaska’s oil fund, which shares resource wealth with residents.
Here, the resource is not oil, but future income from advanced AI systems. OpenAI also wants other major AI companies to give similar 5% stakes.
Anthropic, Google, Meta, and others have not agreed to join this plan. No deal exists yet. The mechanism would likely be: OpenAI gives shares to a government-linked fund, that fund holds them, and future IPO gains or dividends support public payouts.
The hard part is legality. The legal route is unclear, and a deal may need Congress, especially if the government creates a formal public fund.
The Intel deal made this idea less theoretical after taxpayers received a 9.9% stake. OpenAI has already proposed a public wealth fund giving citizens AI-linked financial upside.
Shareholders matter a lot here. OpenAI Foundation owns 26%, Microsoft owns about 27%, and employees plus other investors own 47%. A new 5% stake could dilute everyone unless the shares come from an existing holder.
So OpenAI’s board, Foundation, Microsoft, major investors, and maybe regulators would need to accept the structure. The cleanest path would be non-voting shares placed in a public wealth fund, so the government gets upside but not control. The messiest path would be voting shares, because then Washington becomes both regulator and part-owner.
🗞️ Safety Router Diverts More Prompts From Fable 5 To Opus 4.8

Claude Fable 5 is back online after a 19-day suspension. It is also not really “back to normal.”
Fable 5’s return shows how safety routing can downgrade a frontier model. Now we only permissioned intelligence.
Fable 5 is not nerfed because Anthropic made the underlying model dumb. It is nerfed because the public product path around the model is now more constrained.
The model is powerful enough that Anthropic is routing some requests away from it, blocking more ambiguous behavior, keeping Mythos behind a government-approved gate, limiting included subscription usage, and requiring retention for Mythos-class model data in some enterprise and cloud-provider paths.
The cost of putting a gatekeeper inside intelligence. To note, that safeguard is not a simple refusal layer; it is a classifier that sends flagged Fable 5 requests to Opus 4.8.
I am wondering, ordinary people will probably never again get upgraded frontier models. Fable 5 came back, but the old promise did not. End of an era. ☹️
🗞️ On Claude Fable 5: The below case may be an extreme case but it still shows how quickly Fable 5 classifiers can reroute routine coding to Opus.

The session routed 75% of its work to Opus because the new classifiers kept misreading the coding prompts here as a cybersecurity issue.
🗞️ "The Red Queen Gödel Machine: Co-Evolving Agents and Their Evaluators"

New paper from Cambridge Univ+NVIDIA and other top labs teaches AI agents and AI judges to improve together, so neither side gets stuck.
Moves self-improving AI away from fixed benchmarks and toward a loop where the thing doing the judging can also get better. The problem is that most self-improving agents train against a fixed benchmark or fixed evaluator, so the score can become stale, too easy, or easy to game.
The paper’s idea is to let the evaluator improve too, but only at safe handoff points, so each training stretch still has a stable judge. During each stretch, agents are tested by the current frozen evaluator, while possible better evaluators are tested separately against held-out human or objective answers.
The authors try this on coding, paper writing, paper reviewing, proof writing, and proof grading, where some tasks have clear answers and others need learned judgment. On coding, the system beats the earlier best self-improving coding agent while using 1.35× to 1.72× fewer tokens, because a cheap code reviewer adds useful feedback.
On paper writing, the co-evolved writer gets about 1.86X higher average acceptance from a reviewer panel than the fixed-evaluator baseline. The big point is that stronger AI systems may need stronger judges growing with them, because fixed tests can stop giving useful pressure.
🗞️ The Information: Meta has reportedly limited engineer use of Claude Code and Codex because rival model outputs could contaminate Meta’s own AI training data and create contractual trouble with Anthropic and OpenAI.

Distillation risk starts when a new model of Meta learns from another model’s outputs (from OpenAI or Anthropic), so even accidental reuse of Claude or Codex answers could look like Meta extracted capability from competitors rather than built it alone.
OpenAI’s terms bar using output to develop competing models, and Anthropic says its terms do not allow Claude outputs to train models competitive with Anthropic’s own systems. Both OpenAI’s and Anthropic's terms bar using output to develop competing models.
IMO, the safest strategy could be ingredient tracking: use rival tools for ordinary productivity only when outputs are barred from model-training pipelines, evaluation sets, benchmark generation, post-training data, reward-model data, and internal datasets that later feed model development.
Of course a strong lawsuit usually needs much more ugly facts like: mass scraping, fake accounts, rate-limit evasion, automated extraction, direct use of outputs as training labels, or internal records showing the buyer knew it was cloning a rival system.
In this situation, som of the typical safeguards are clean-room rules, approved enterprise accounts, no consumer accounts for sensitive work, training-data provenance logs, dataset quarantine, prompt and output retention, automated scanners for “AI-generated by vendor X” material, and access controls separating coding-agent work from model-training data.
🗞️ "MCP Server Architecture Patterns for LLM-Integrated Applications"

Very timely paper.
MCP servers need clear design patterns because LLMs get confused when too many tools or vague tools are shown. This paper explains how MCP servers should be structured so LLM tools stay useful, safe, and manageable.
s MCP server design is not just normal API design, because the client is an LLM that chooses tools by reading plain-language descriptions. It groups real MCP servers into 5 useful patterns, such as servers that expose data, run workflows, keep session state, combine many servers, or translate messy domain APIs.
The authors also warn about 4 common mistakes, especially giant all-purpose tools, vague tool descriptions, unsafe outside content, and slow tools that should return a job ID instead. They tested the pattern labels on 54 extra servers, measured transport delay, and studied how tool accuracy changes as more tools are shown.
The key result is that too many visible tools hurt accuracy, with weaker models dropping below 90% between 10 and 15 tools. Good MCP design is mostly about making the tool list small, clear, safe, and stable enough for LLMs to choose the right action.
🗞️ "Quantized Reasoning Models Think They Need to Think Longer, but They Do Not"

Paper from Meta shows Quantized reasoning models often lose because they keep doubting a correct answer instead of finishing.
Many of them reason well enough, but compression makes them hesitate at the wrong time. The problem is that post-training quantization, a way to shrink models after training, can make reasoning models cheaper to run but worse at finishing cleanly.
The authors found that strong quantization does not only make models less capable, since in many failures the model already reached the right answer but then second-guessed itself. Their core idea is that quantization adds noise at uncertain word choices, so the model becomes more likely to pick words like “wait,” “but,” or “alternatively” that reopen the problem.
They tested this across math, coding, and science tasks using 5 reasoning models, several quantization methods, and model sizes from 1.5B to 32B. The main result is that aggressive quantization raised overthinking failures up to 52%, while a small penalty on 50 hesitation words cut reasoning length by 12% to 23% and often kept or improved accuracy. Given compressed models are widely used to save memory and cost, very important to know that a very small decoding fix can stop many of them from wasting tokens and losing answers they already had.
🗞️ NVIDIA made a 30B language model write 2.42x faster with 98.7% retained quality.
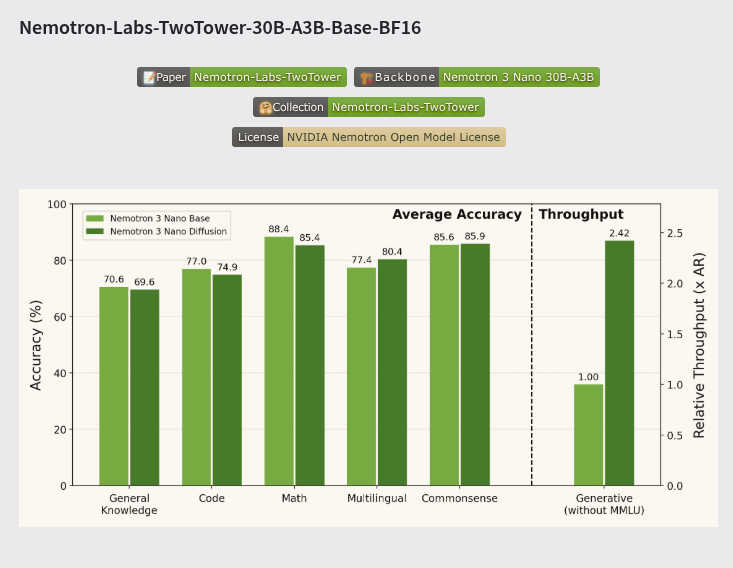
Normal LLMs write one token after another, because each new token depends on the previous one.
NVIDIA keeps that old system for context, but adds a second tower for faster writing. One frozen tower reads the prompt and stores memory, while another fills masked token blocks together.
The second tower guesses many positions at once, then revises weak spots across several passes. This changes decoding from a narrow single-token line into a block-based refinement process.
So the whole idea is: spend more GPU memory to reduce waiting time during generation.
The model still moves block by block, so past text remains stable and future text stays constrained.
NVIDIA reports 78.24 on MMLU, 90.14 on GSM8K, and 75.58 on HumanEval. The catch is hardware, because full diffusion mode needs 2 80GB H100 or A100 GPUs.
This approach looks useful because it reuses a pretrained AR backbone instead of rebuilding everything. Speed gains at near-baseline quality make sense for long outputs, agents, and high-volume inference.
A normal LLM keeps asking one question: “What is the next token?”
Nemotron-Labs-TwoTower asks a bigger question: “Given the prompt, can I fill 16 missing token slots at once?”
The first tower reads the prompt and already accepted text, then stores the memory. The second tower looks at a block of masked slots and proposes many tokens in parallel.
Low-confidence guesses stay masked, high-confidence guesses get locked, and the block is refined again. Once the block is finished, the first tower absorbs it as real context, then the next block starts.
The loop exists because language still needs left-to-right order across the whole answer. The speed comes from doing parallel work inside each block, instead of only one token per step.
The price is that you are running two large model copies, not one.
That’s a wrap for today, see you all tomorrow.